Download to read offline








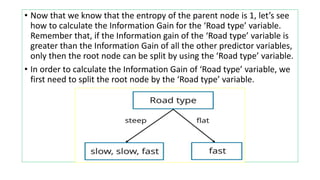

![• Our next step is to calculate the Entropy(children) with weighted
average:
• Total number of outcomes in parent node: 4
• Total number of outcomes in left child node: 3
• Total number of outcomes in right child node: 1
• Formula for Entropy(children) with weighted avg. :
• [Weighted avg]Entropy(children) = (no. of outcomes in left child node)
/ (total no. of outcomes in parent node) * (entropy of left node) + (no.
of outcomes in right child node)/ (total no. of outcomes in parent
node) * (entropy of right node)
• By using the above formula you’ll find that the, Entropy(children) with
weighted avg. is = 0.675](https://image.slidesharecdn.com/decisiontree-220104100444/85/Decision-tree-11-320.jpg)



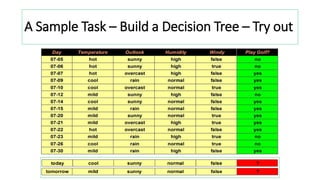

A decision tree classifier is explained. Key points include: - Nodes test attribute values, edges correspond to test outcomes, and leaves predict the class. - Information gain measures how much a variable contributes to the classification. - It is used to select the variable that best splits the data at each node, with the highest information gain splitting the root node. - An example calculates information gain for road type, obstruction, and speed limit variables to classify car speed. Speed limit has the highest information gain of 1 and is used to build the decision tree.























































































