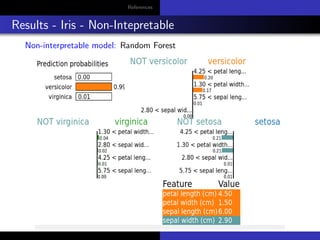
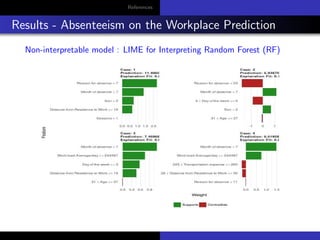
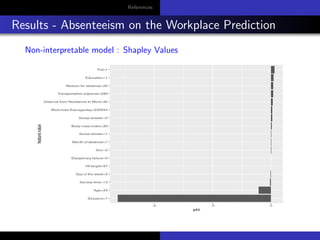
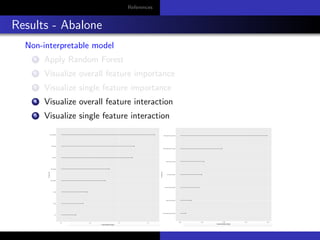
The document discusses model-agnostic methods for interpretable machine learning, emphasizing the importance of understanding not just the predictions ('what') but also their explanations ('why') in various applications. It introduces techniques such as Local Interpretable Model-agnostic Explanations (LIME), Shapley values, and Individual Conditional Expectation (ICE) plots to derive insights from black-box models. Case studies include interpreting predictions for datasets like Iris and absenteeism at workplaces using various models like decision trees and random forests.

![References
Introduction
ML is winning popularity: games, medical, driving, etc.
Black-Box models - Inner working
The necessity for interpretability comes from an incompleteness in
the problem formalisation [?], meaning that for certain problems or
tasks it is not enough to get the answer (the what). The model also
has to give an explanation how it came to the answer (the why),
because a correct prediction only partially solves your original
problem.
Aim of interpretation models - Control biased results
Minorities: winner takes it all.
Ethics: Job seeking, terrorist detection, etc.
Accuracy : when applying the model to real life - 99% accuracy
beacuse of test-validation. Existance of correlations that might not
ecists in real time.](https://image.slidesharecdn.com/presentationmodelagnosticmethodsforintepretablemachinelearning-180622181733/85/Intepretable-Machine-Learning-2-320.jpg)