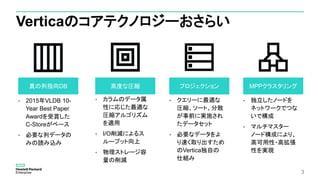
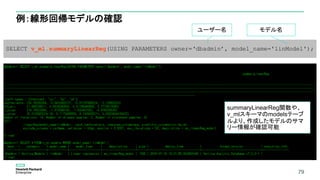
40
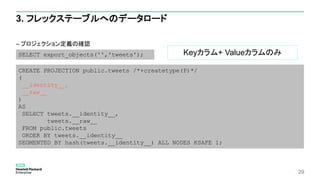
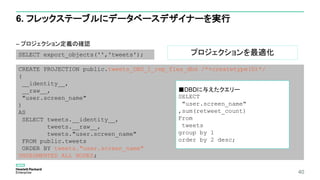
– プロジェクション定義の確認
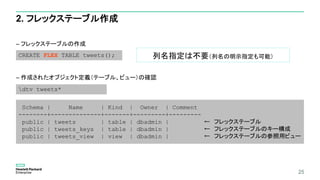
6. フレックステーブルにデータベースデザイナーを実行
CREATEPROJECTION public.tweets_DBD_1_rep_flex_dbd /*+createtype(D)*/
(
__identity__,
__raw__,
"user.screen_name"
)
AS
SELECT tweets.__identity__,
tweets.__raw__,
tweets."user.screen_name"
FROM public.tweets
ORDER BY tweets."user.screen_name"
UNSEGMENTED ALL NODES;
SELECT export_objects('','tweets');
■DBDに与えたクエリー
SELECT
"user.screen_name"
,sum(retweet_count)
From
tweets
group by 1
order by 2 desc;
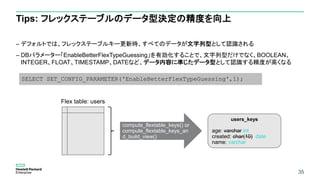
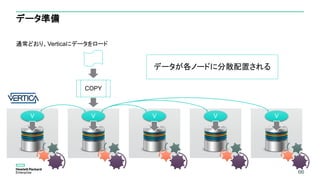
プロジェクションを最適化
63
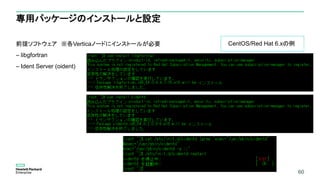
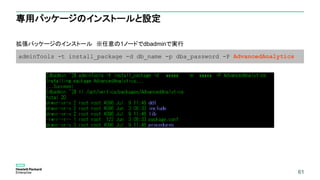
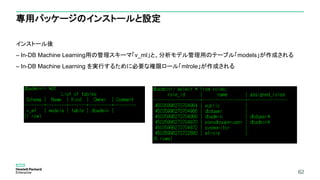
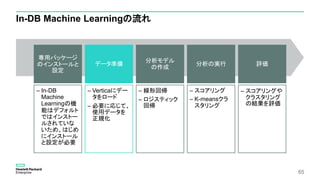
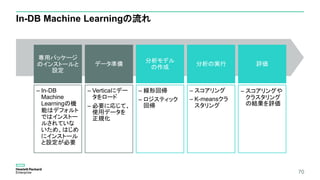
専用パッケージのインストールと設定
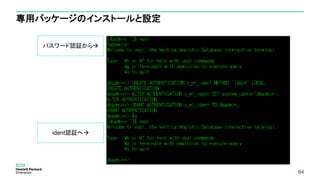
In-DB Machine Learningを実行するユーザーの認証方法をident認証にすることが必要
– この例では、mlroleロール権限をデフォルトで持っているdbadminを使った例となっているが、
専用のユーザーを作成し、「mlroleロール」権限を付与することを推奨
63
CREATE AUTHENTICATION v_ml_ident METHOD 'ident' LOCAL;
ALTER AUTHENTICATION v_ml_ident SET system_users='dbadmin';
GRANT AUTHENTICATION v_ml_ident TO dbadmin;
その他設定の詳細は、以下をご参照ください
■ Assign Users to the mlrole Role and Allow Access to Advanced Analytics Functions
■ Configuring Hash and Ident Authentication












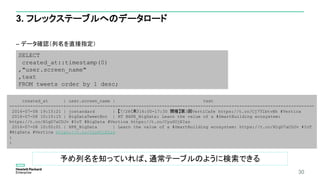
![23
1. JSONファイルの準備
– Twitter Public APIよりJSONファイルを取得し、Verticaノードに配置
– GET https://api.twitter.com/1.1/search/tweets.json?q=%23Vertica&count=100
– JSONは、ネスト、配列構造の形式をサポート
{
"statuses":
[
{
"created_at": "Fri Jul 08 10:15:21 +0000 2016",
"text": "u30107/28uff08u6728uff0916:00-17:30 … …",
:
"user": {
"screen_name": "jostandard",
:
},
:
"lang": "ja"
},
:
]
}](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-23-320.jpg)
![24
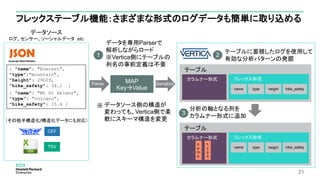
フレックステーブル機能を使ってJSONデータを取り込んでみる
Tweets.json [Flex Table]
Tweets
2. フレックステーブル作成
[Flex Table]
Tweets_keys
[Flex View]
Tweets_view
Tweetsテーブル作成時、以下も同時に生成
・Tweets_keys(キー構成管理テーブル)
・Tweets_view(参照用ビュー)](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-24-320.jpg)
![26
フレックステーブル機能を使ってJSONデータを取り込んでみる
Tweets.json [Flex Table]
Tweets
3. データロード
[Flex Table]
Tweets_keys
[Flex View]
Tweets_view](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-26-320.jpg)

![31
フレックステーブル機能を使ってJSONデータを取り込んでみる
Tweets.json [Flex Table]
Tweets
[Flex Table]
Tweets_keys
[Flex View]
Tweets_view
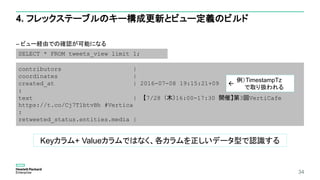
4. キー構成更新と
ビュー定義のビルド](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-30-320.jpg)


![36
フレックステーブル機能を使ってJSONデータを取り込んでみる
Tweets.json [Flex Table]
Tweets
[Flex Table]
Tweets_keys
[Flex View]
Tweets_view
[Flex Table]
Tweets
5. カラムナー形式の列を追加](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-35-320.jpg)


![39
フレックステーブル機能を使ってJSONデータを取り込んでみる
Tweets.json [Flex Table]
Tweets
[Flex Table]
Tweets_keys
[Flex View]
Tweets_view
[Flex Table]
Tweets
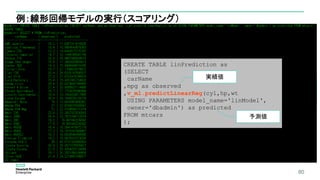
DBD
6. DBDの実行(*)
Query
* DBD(Database Designer)の詳細については、以下の資料をご参照ください
マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステップ](https://image.slidesharecdn.com/eyjhzxacrfq3hpbt3sam-signature-42556db2a0cceb001c7af1355dfc480ed7ae9469d6b3958af3d55547345cbe79-poli-160802091004/85/db-tech-showcase-Tokyo-2016-A13-Vertica-Analytics-by-38-320.jpg)






















![[db tech showcase Tokyo 2016] D24: データベース環境における検証結果から理解する失敗しないフラッシュ活用法 第三章 ~デ...](https://cdn.slidesharecdn.com/ss_thumbnails/d6uypm5osrop0rxlhdef-signature-2d11c0bd82acade7267e98773c5eb2fdeb5e2d37143247ecfa1a77486c63a28f-poli-160721021336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B24: そのデータベース 5年後大丈夫ですか ~ 本気で標準化とサービスレベルの確保を手に入...](https://cdn.slidesharecdn.com/ss_thumbnails/kmkt9scqkurhysqpfnyd-signature-bc6e39cef4e34861db534164f852c5f36a4273c7f8d554162f3d3d3e0e8be912-poli-160802091657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] D13: NVMeフラッシュストレージを用いた高性能高拡張高可用なデータベースシステムの実現方...](https://cdn.slidesharecdn.com/ss_thumbnails/efmcwyyftdwdehhr3b4y-signature-06a70abedb3d16e5e7bcb9b2ba8014302148552ca76b90497742e559ab641b61-poli-160726094411-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] D15: データベース フラッシュソリューション徹底解説! 安価にデータベースを高速にする方法...](https://cdn.slidesharecdn.com/ss_thumbnails/8dzgn4hircgyxu7agvvv-signature-e2d161bac10db4b1f2edfe0e3785064ea4537096d62ef03035d3e3fcb7faeb03-poli-160815015129-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] D32: SPARCサーバ + Pure Storage DB仮想化のすべらない話 〜 Exa...](https://cdn.slidesharecdn.com/ss_thumbnails/z2eqswjiq0qjpsc4dkeb-signature-2d942d3aa095bc3836bb8cb6191902c41b7c0f1a401dee95c7cbbf61a4eb7178-poli-160721013608-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] A25: ACIDトランザクションをサポートするエンタープライズ向けNoSQL Databas...](https://cdn.slidesharecdn.com/ss_thumbnails/0srcpmelq3u9j2hc5dv9-signature-2f56a4964d89a71ef0ade271d7aebd1fb48e0c6f2d10a84704e4a42846607f3d-poli-160721034720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20171019 三木会] データベース・マイグレーションについて by 株式会社シー・エス・イー 藤井 元雄 氏](https://cdn.slidesharecdn.com/ss_thumbnails/dbmigration-171030091652-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] A35: NVMe徹底検証 by 株式会社インサイトテクノロジー 平間 大輔](https://cdn.slidesharecdn.com/ss_thumbnails/duwstkmftmk1ljzvasyo-signature-894dfd7b74ecb9b4108868bb00c4d449f11835b4a29fd9720063bbf078c9ab25-poli-160721065555-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Sapporo 2015] A12:DBAが知っておくべき最新テクノロジー: フラッシュ, ストレージ, クラウド b...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtssapporo2015a12oraclesqlserverinsighttechnology-150918013852-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] A12: フラッシュストレージのその先へ ~不揮発性メモリNVDIMMが拓くデータベースの世界...](https://cdn.slidesharecdn.com/ss_thumbnails/uqh9hsugt9krhv4njvvp-signature-8a4b77bfb689f3a07a5dada750f0363640888114386361e908c1a0ac19dad85c-poli-160802091305-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...](https://cdn.slidesharecdn.com/ss_thumbnails/b37dbtechshowcasetokyo2015haclusteringsoftware20150612-150611165311-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A16: Using a Multi-Model Database to Improve Da...](https://cdn.slidesharecdn.com/ss_thumbnails/a16-170913083202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C27:楽天MySQL Backup Structure by 楽天株式会社 粟田啓介](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c27mysqlrakuten-150617022225-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B22: 超高速NoSQLデータベースと超高速SSDの融合 by Aerospike Inc....](https://cdn.slidesharecdn.com/ss_thumbnails/r3oxkwcnqk6ave10vnms-signature-08572b1973d1e838ce6e259472803258e44e38c17ea11d66d7dde184367c2ef2-poli-160721055148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] A27: ストレージ視点から見たMariaDB性能チューニング by 東芝メモリ株式会社 佐藤修一](https://cdn.slidesharecdn.com/ss_thumbnails/a27-170915045743-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] B14: 4年連続No.1リーダー評価のストレージでDBクローンするとどんな感じ?瞬時のクロー...](https://cdn.slidesharecdn.com/ss_thumbnails/20180905oracleonpurebackuprecoveryv1-170912014552-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] E24: 流行りに乗っていれば幸せになれますか?数あるデータベースの中から敢えて今Db2が選ば...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2017db2ibm-171006012214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] E34: Oracle SE - RAC, HA and Standby are Still ...](https://cdn.slidesharecdn.com/ss_thumbnails/lqy2zqfxqmif8xeztxtr-signature-44327555e43d6a00760901a1f10c738a3c30da5dd494b81e3f7ae75f088cd2d2-poli-160815043717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] E22: Getting real time Oracle data into Kafka a...](https://cdn.slidesharecdn.com/ss_thumbnails/33xykpqpmbutrglvlbgg-signature-6edb48f833318dd95dfa58e0d889618cd124b3092d7873eb24c23621e1294cb3-poli-160815030056-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] A15: デジタルデータの可視化基盤「ENdoSnipe」を使った、システムトラブルの未然防止、経営判...](https://cdn.slidesharecdn.com/ss_thumbnails/cy4rydjvtbqlsdbjvfjp-signature-6c441ec4ed8a596b287f8876a9c2327726653416fda3001e3b626ac244237f38-poli-161007073506-thumbnail.jpg?width=640&height=640&fit=bounds)

![[data analytics showcase] B14: 文字情報の分析基盤 Mroonga by 株式会社インサイトテクノロジー 小幡 一郎](https://cdn.slidesharecdn.com/ss_thumbnails/gewtegxitccqr9e2hb5m-signature-dbdadd8978e07a8eac70e8d97843d87d84136d17cf5a5b684423cc574b8995e4-poli-161007060519-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] B11: ビッグデータを高速に検索・分析する「Elasticsearch」~新プラグイン「Graph」...](https://cdn.slidesharecdn.com/ss_thumbnails/waubsfngq2iqk8eggult-signature-33a079331e4d341f615beadcebfcdc44a5e412d60f4705c29726afdc4cbdaa7a-poli-161007073051-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2016] C32: 世界一速いPostgreSQLを目指せ!インメモリカラムナの実現 by 富士通株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/decdzrorcuek1megqnk7-signature-4c0dd3fcb9eb3d17930cacb079ea1fd12d54c70d5a7ef5cbe3514e2f97cef80f-poli-160902010202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] A12: データに隠された課題、ちゃんと見えていますか? by Tableau Japan 株式会社 ...](https://cdn.slidesharecdn.com/ss_thumbnails/qeouriw3q6utlro0qyn1-signature-bac39e432b181dc3cbb550d6b84a1ba118e0e86ab38872b728592f592e9523c9-poli-161007055821-thumbnail.jpg?width=640&height=640&fit=bounds)
![[data analytics showcase] B12: サーバー1,000台を監視するということ by 株式会社インサイトテクノロジー 小幡 一郎](https://cdn.slidesharecdn.com/ss_thumbnails/zwxv3e5eq2onvtifzkda-signature-1379033641429794afbc9d6c48d9c7cc5945545725d7bf5772715883640ebcaa-poli-161011071522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[data analytics showcase] B16: Live Demo! データ分析基盤を支えるデータレプリケーション技術とデータワークロード分...](https://cdn.slidesharecdn.com/ss_thumbnails/waf1saonq7kghgwbprmc-signature-25a0ea6711cd6aa4d4a08a1137bfd90f9f8e7850cd850623d7101ef7c30a9b4c-poli-161007061148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...](https://cdn.slidesharecdn.com/ss_thumbnails/tehahj7vqmsswpgrzrq6-signature-4c7632456c9c538ff9d2a30431910153be9e17d570b88fac06692ab02f11f222-poli-160725043205-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B27:SQL Server 2016 AlwaysOn 可用性グループ New Featur...](https://cdn.slidesharecdn.com/ss_thumbnails/yee2npgr5waqmemzestf-signature-b2f2152254fdb7226f9f1a595e25a2a665f2eab3e0fa1feb5c6cabee34d27a40-poli-160719052915-thumbnail.jpg?width=640&height=640&fit=bounds)







![[db tech showcase Tokyo 2014] C25: Facebookが採用した世界最大級の分析基盤とは? by 日本ヒューレット・パッ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c25hpfacebook-141120232027-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2018] #dbts2018 #D27 『Verticaの進化が止まらない! 機械学習、データレイク、処...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts2018d27vertica-180929170331-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)