



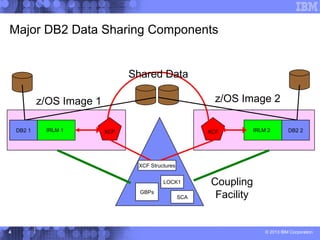





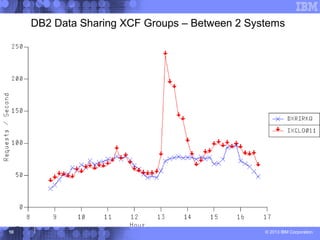
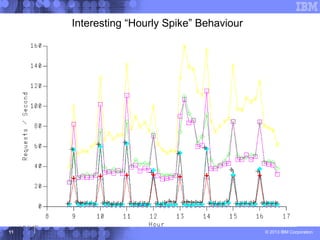



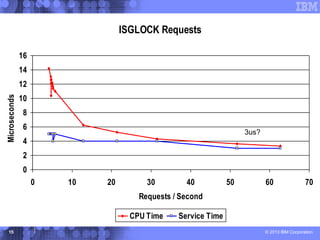
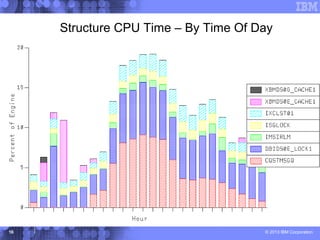

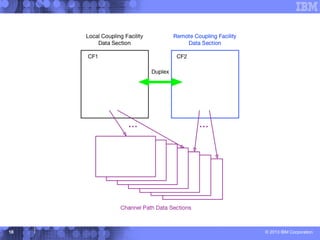





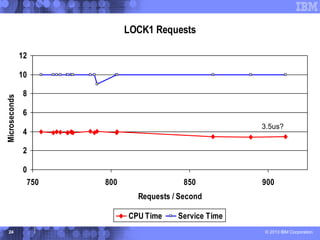


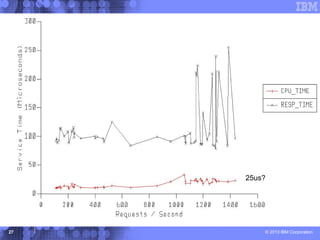
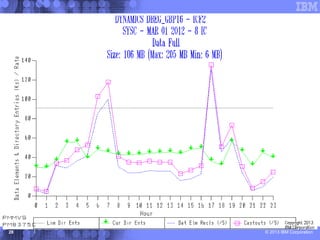






This document presents a comprehensive view of DB2 data sharing performance within a parallel sysplex environment, focusing on components such as XCF, the coupling facility, and data sharing structures. It covers performance optimization strategies, including tuning approaches for locking, group buffer pools, and XCF traffic management. The key takeaway emphasizes the importance of effective configuration and monitoring to enhance both performance and cost-efficiency in DB2 data sharing setups.





















































































