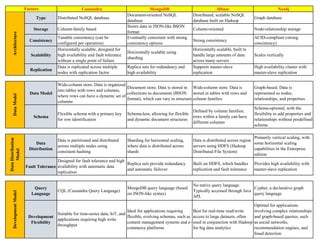
The document compares various distributed NoSQL databases, including Cassandra, MongoDB, HBase, and Neo4j, highlighting their characteristics such as data models, scalability, fault tolerance, and query languages. It outlines specific features like the flexible schema of MongoDB, the wide-column store of Cassandra, and the graph-based structure of Neo4j. The document also emphasizes their suitability for different applications, such as time-series data, content management, big data analytics, and complex relationship queries.