Download as PDF, PPTX



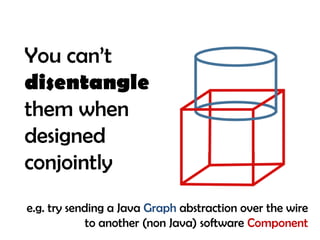
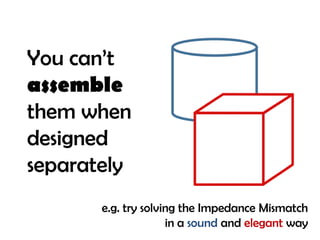

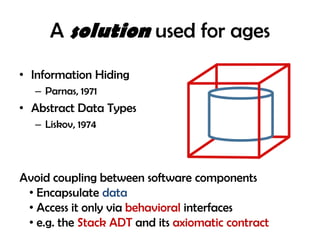
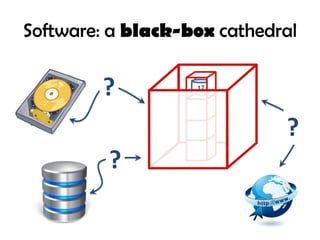






The document discusses the intertwined nature of code and data, highlighting persistent issues such as impedance mismatch and coupling between software components. It emphasizes the need for a data-centric programming language, proposing 'finitio' as a solution for enforcing and validating data types across various platforms. The author urges for a paradigm shift that prioritizes data representation alongside behavior in software engineering.
































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


