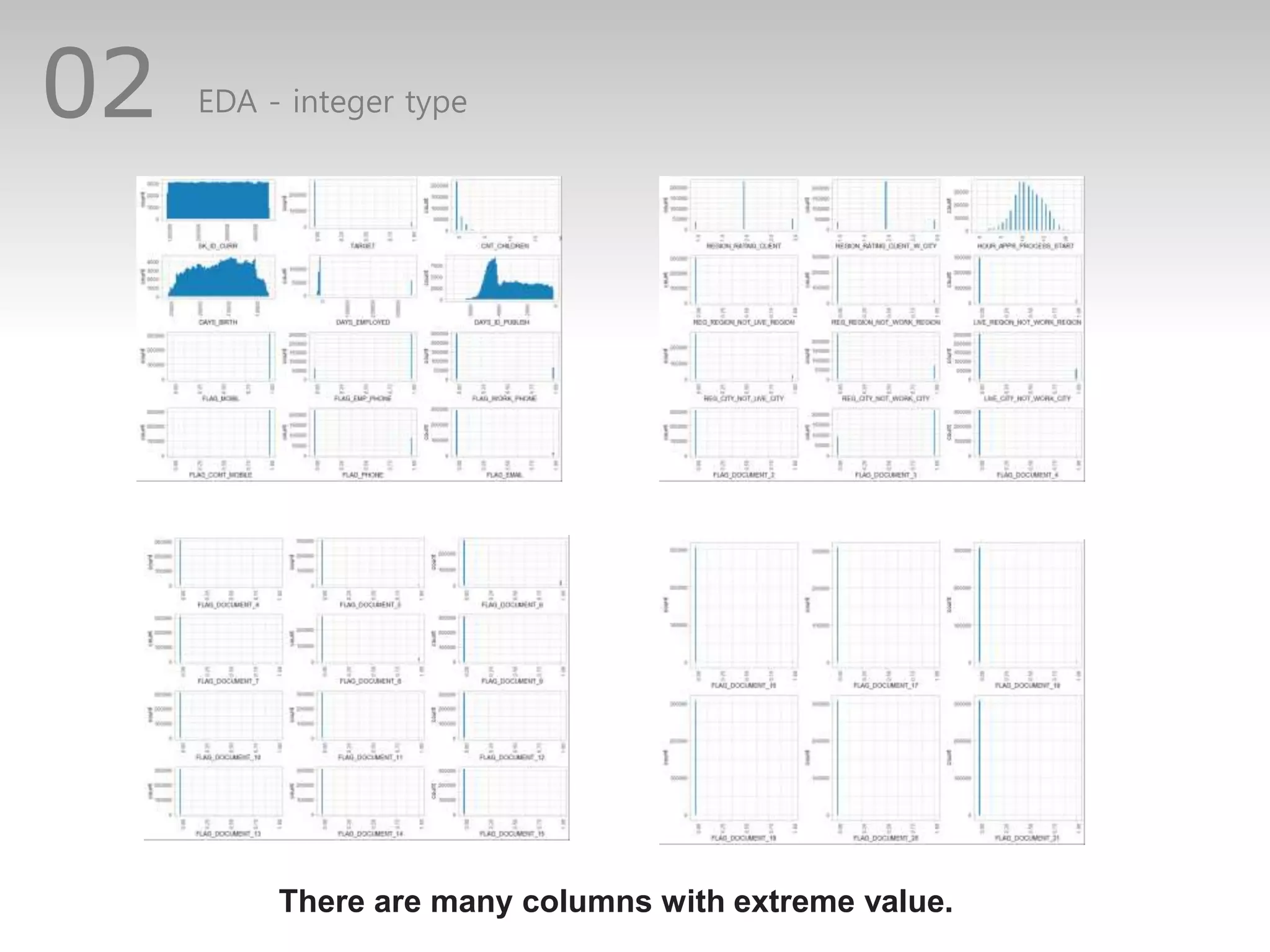
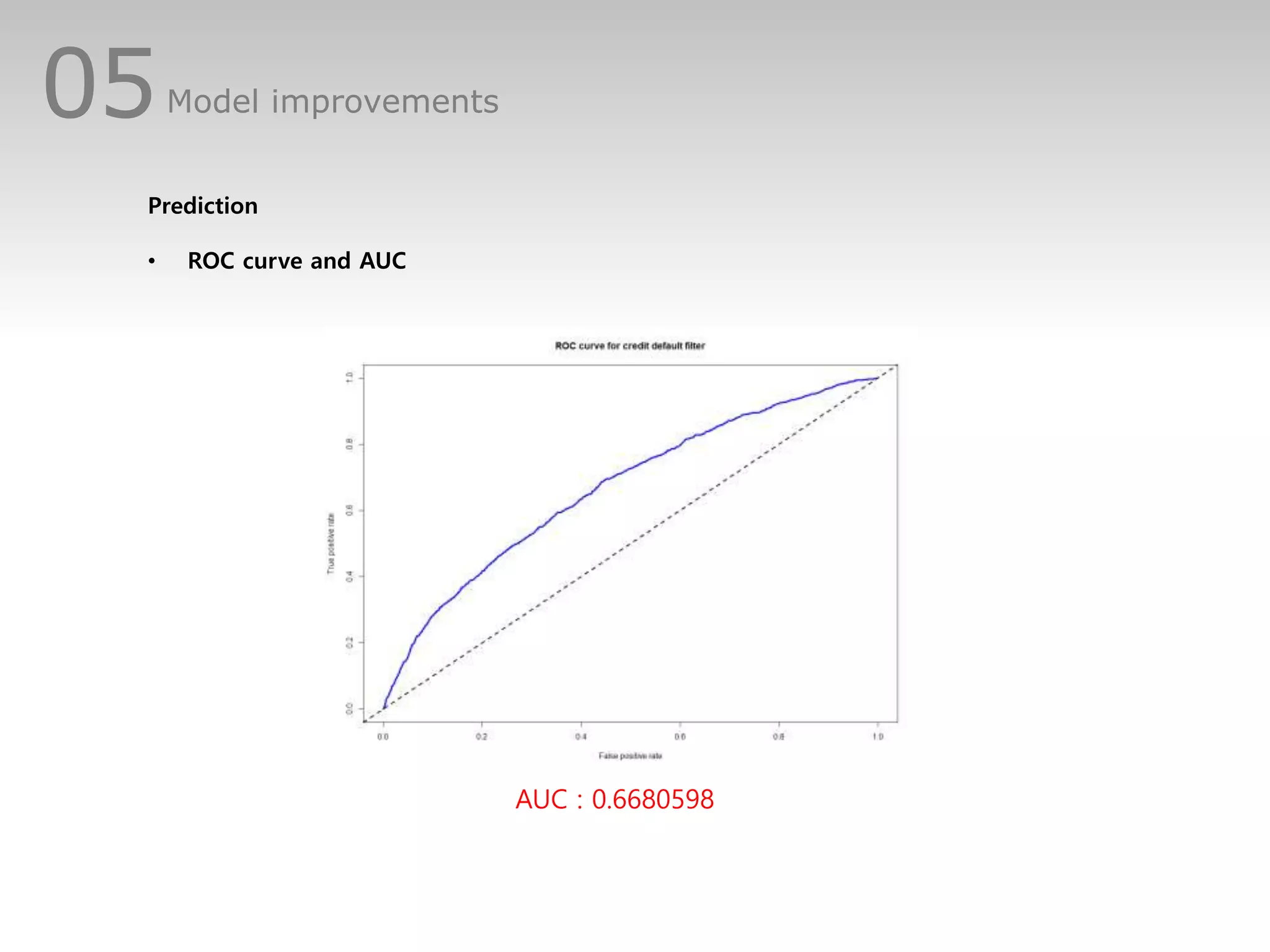
This document discusses predicting credit default risk using a Home Credit dataset. It summarizes analyzing the data using logistic regression, dealing with imbalanced classes and multicollinearity. Model improvements using SMOTE sampling and excluding correlated variables increased sensitivity from 0.01 to 0.33, though accuracy and AUC decreased. Further improvements could involve other models, and handling missing values without exclusion.












![02NULL Values
> mean(is.na(application)) [1] 0.2454355
Columns with null values greater than 50%
Too many null values
we assume that variables with
Large number of null values are
hard to present data
Decided to exclude those variables](https://image.slidesharecdn.com/creditdefaultrisk-181116123247/75/Credit-default-risk-14-2048.jpg)







































![ai it hw mst prac[1] - Read-Offnly.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiithwmstprac1-read-only-250118093323-c97d352c-thumbnail.jpg?width=640&height=640&fit=bounds)










![Seoul square[mock project]](https://cdn.slidesharecdn.com/ss_thumbnails/seoulsquaremockproject-181117120538-thumbnail.jpg?width=640&height=640&fit=bounds)


























