Download to read offline

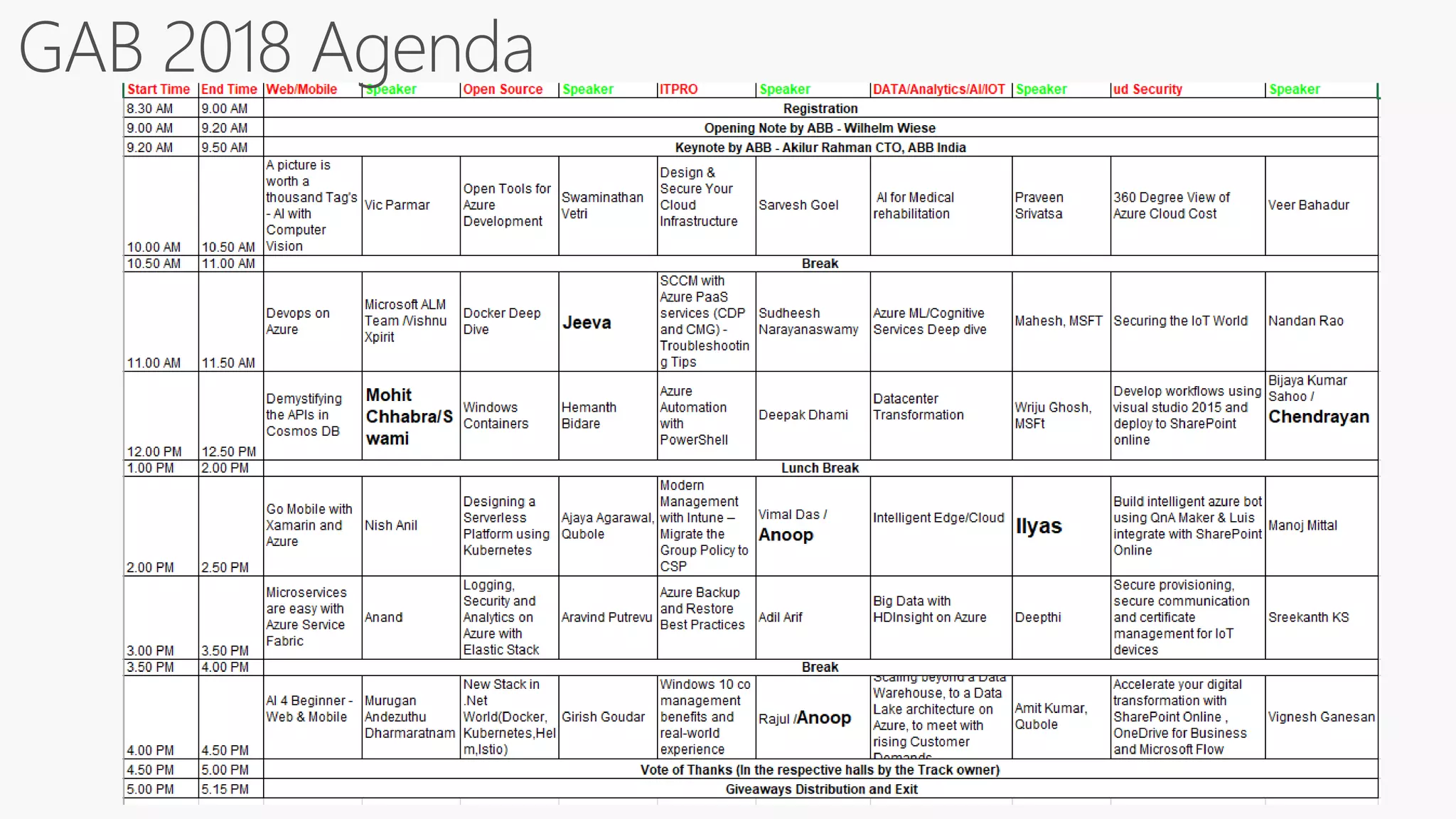




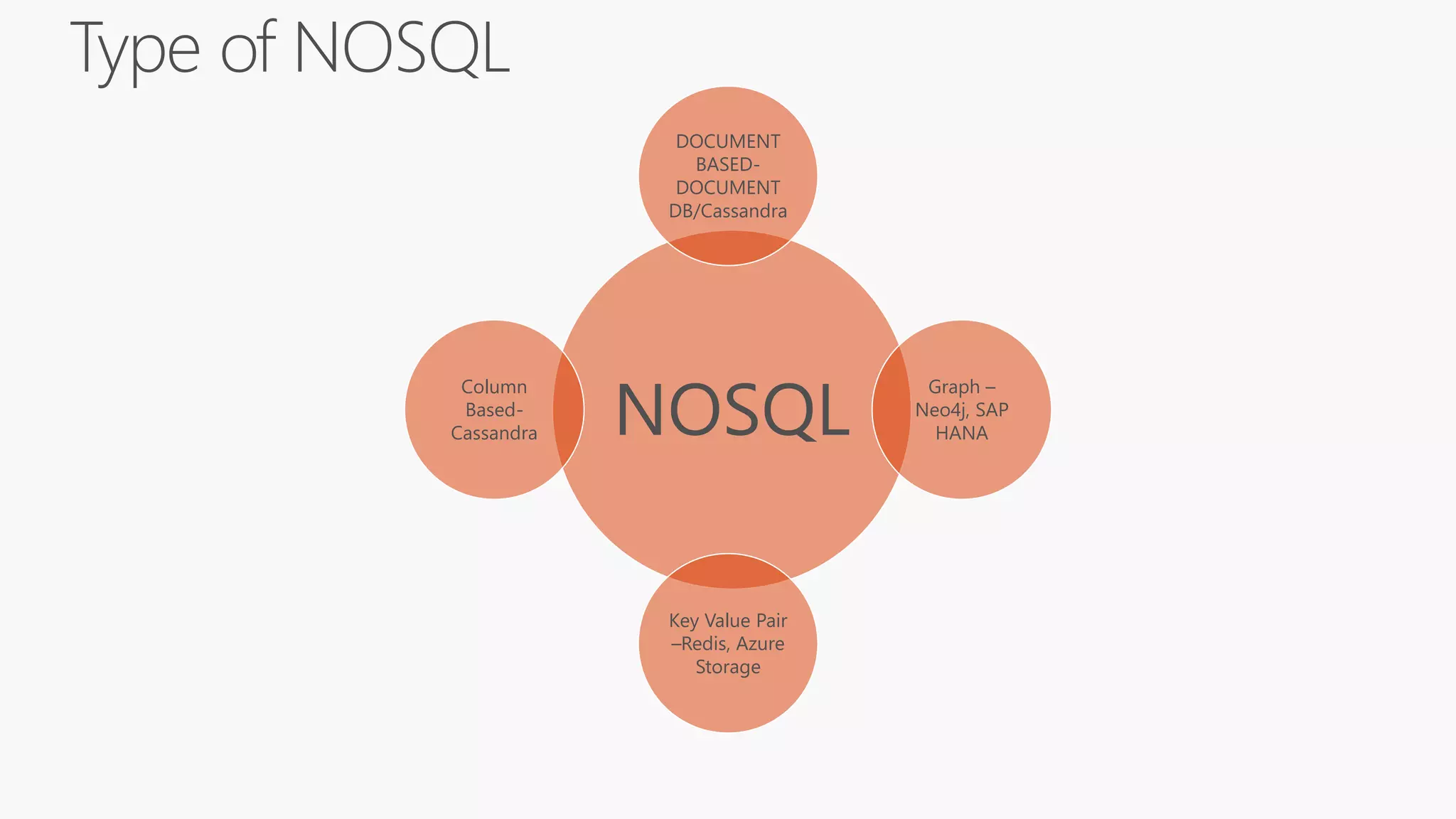
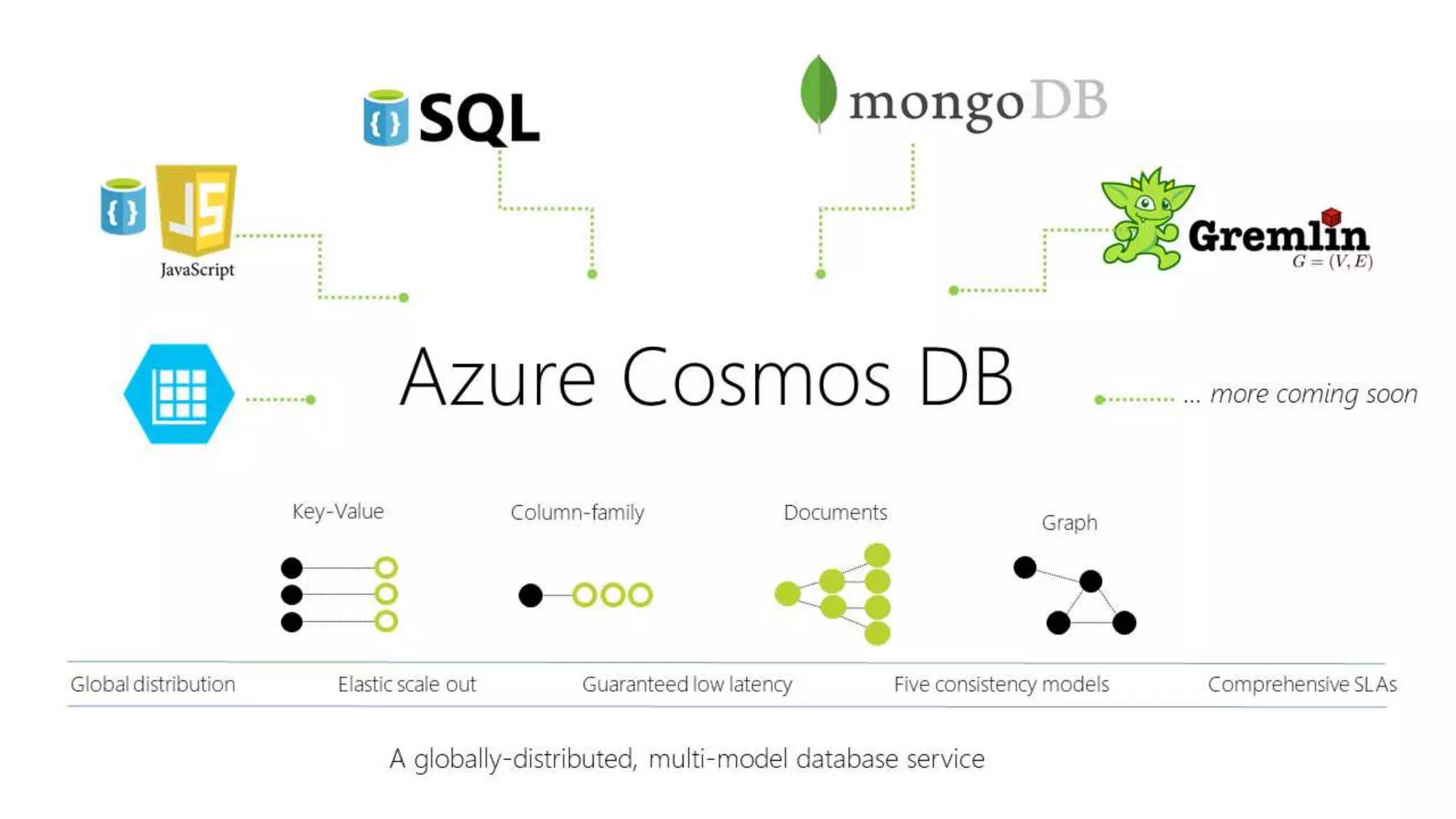

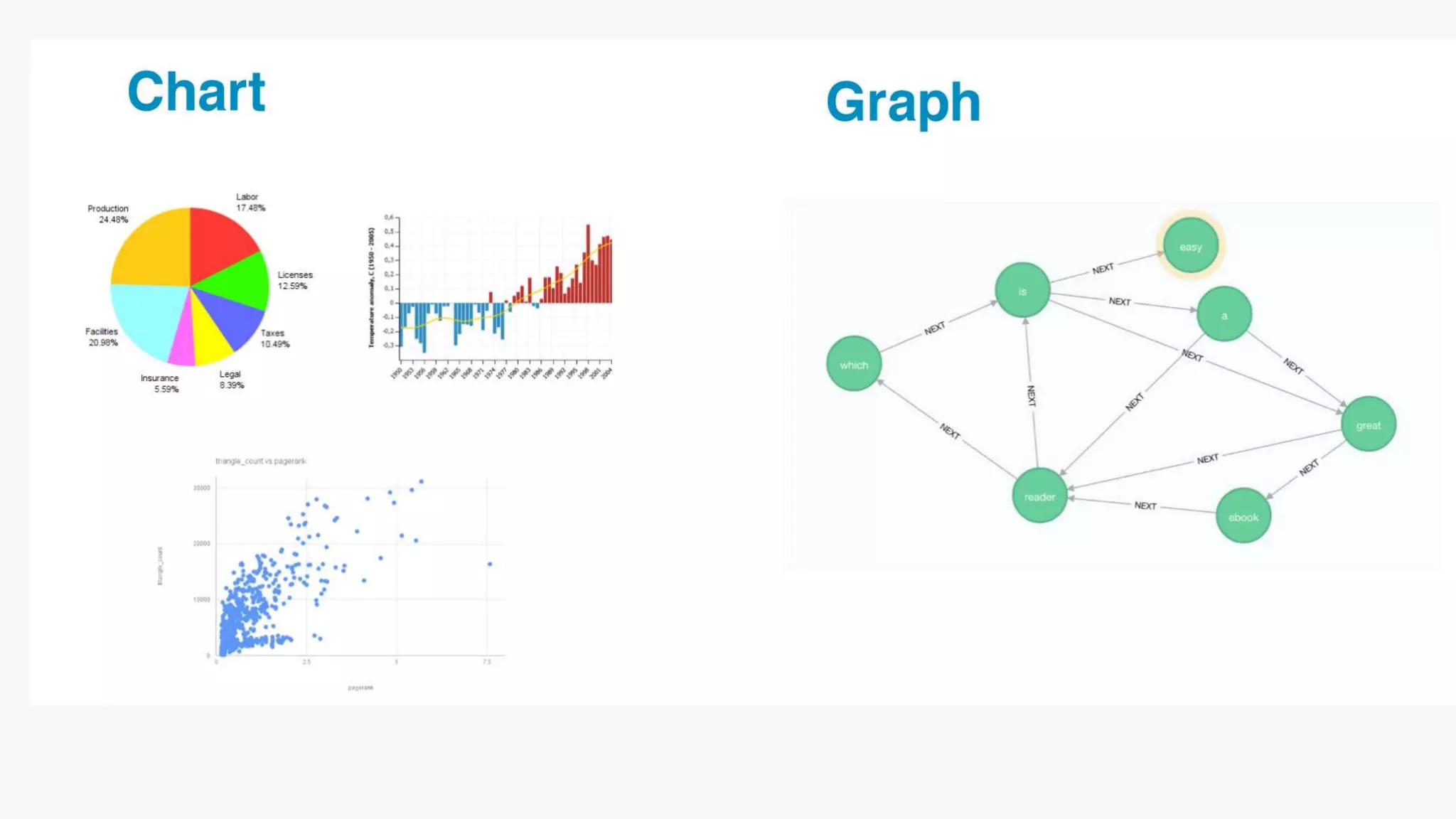
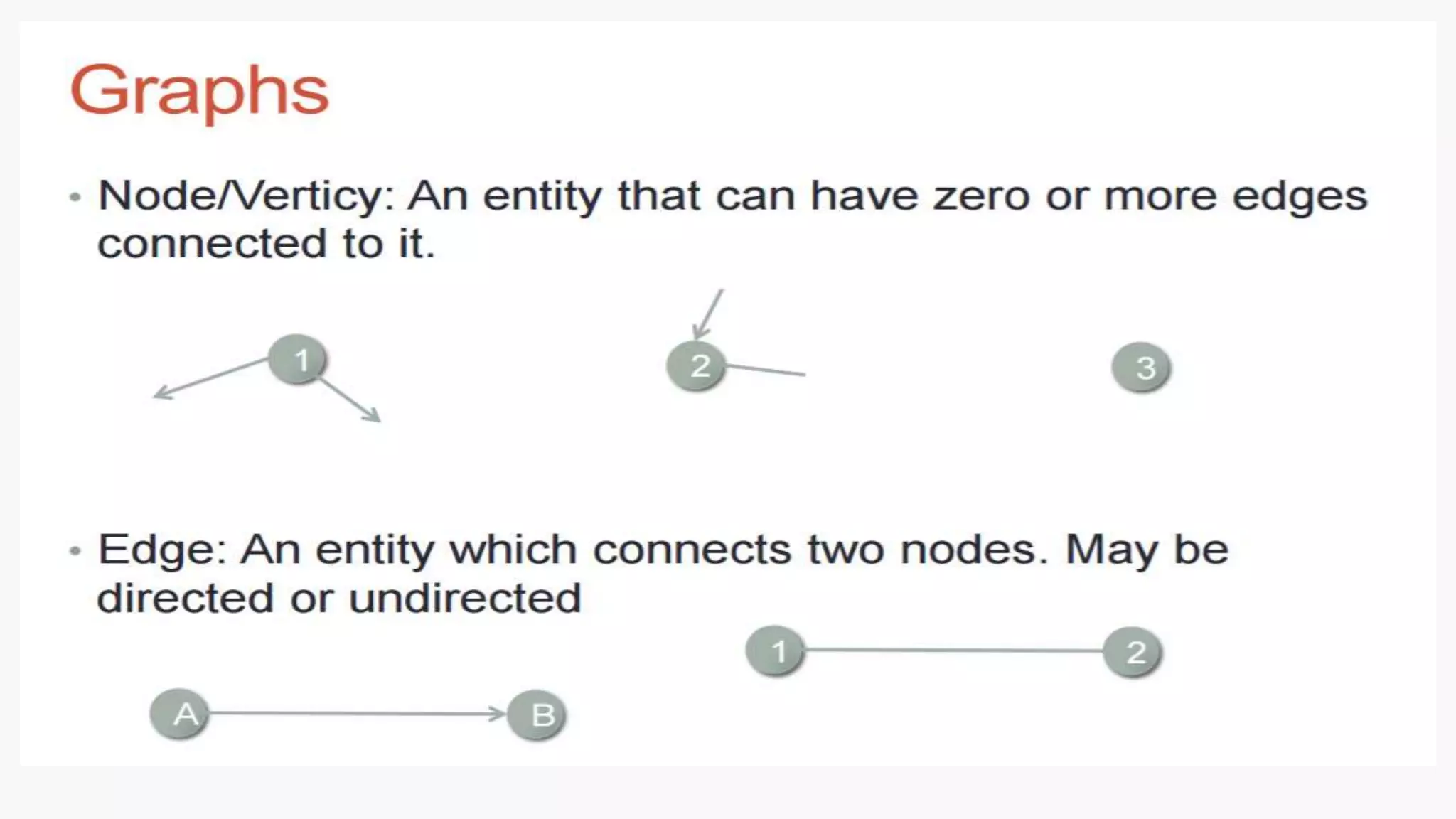
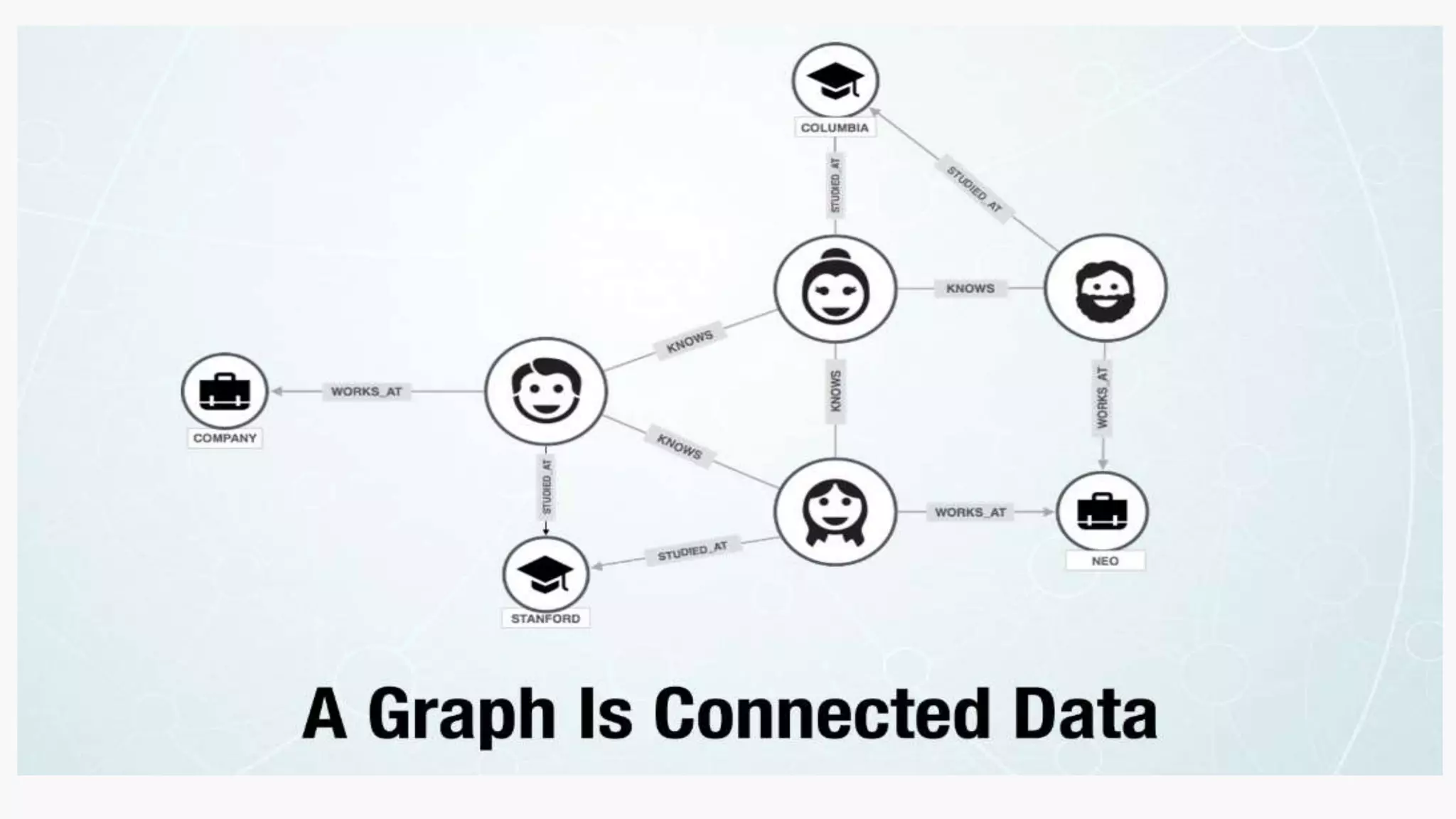

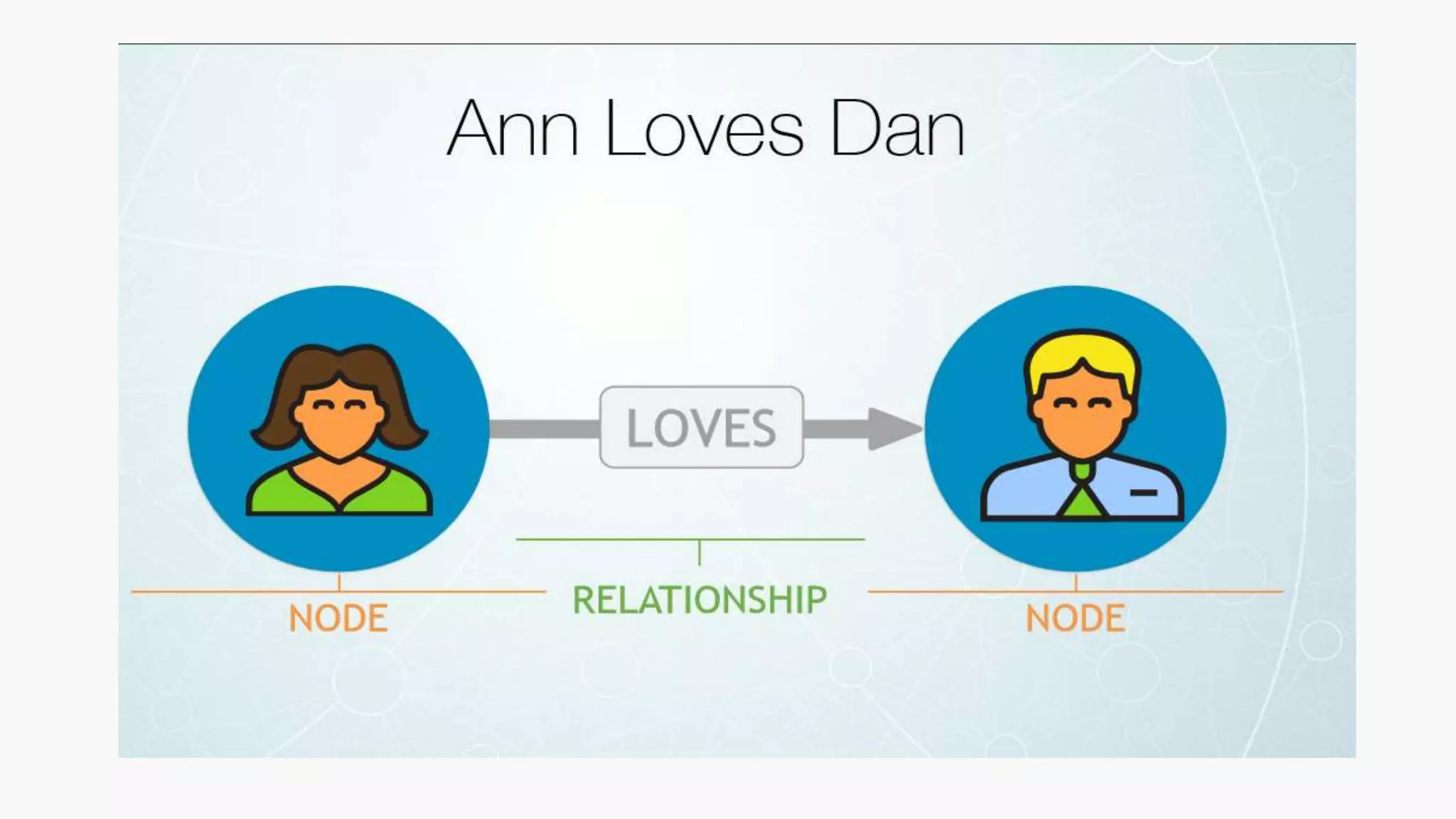
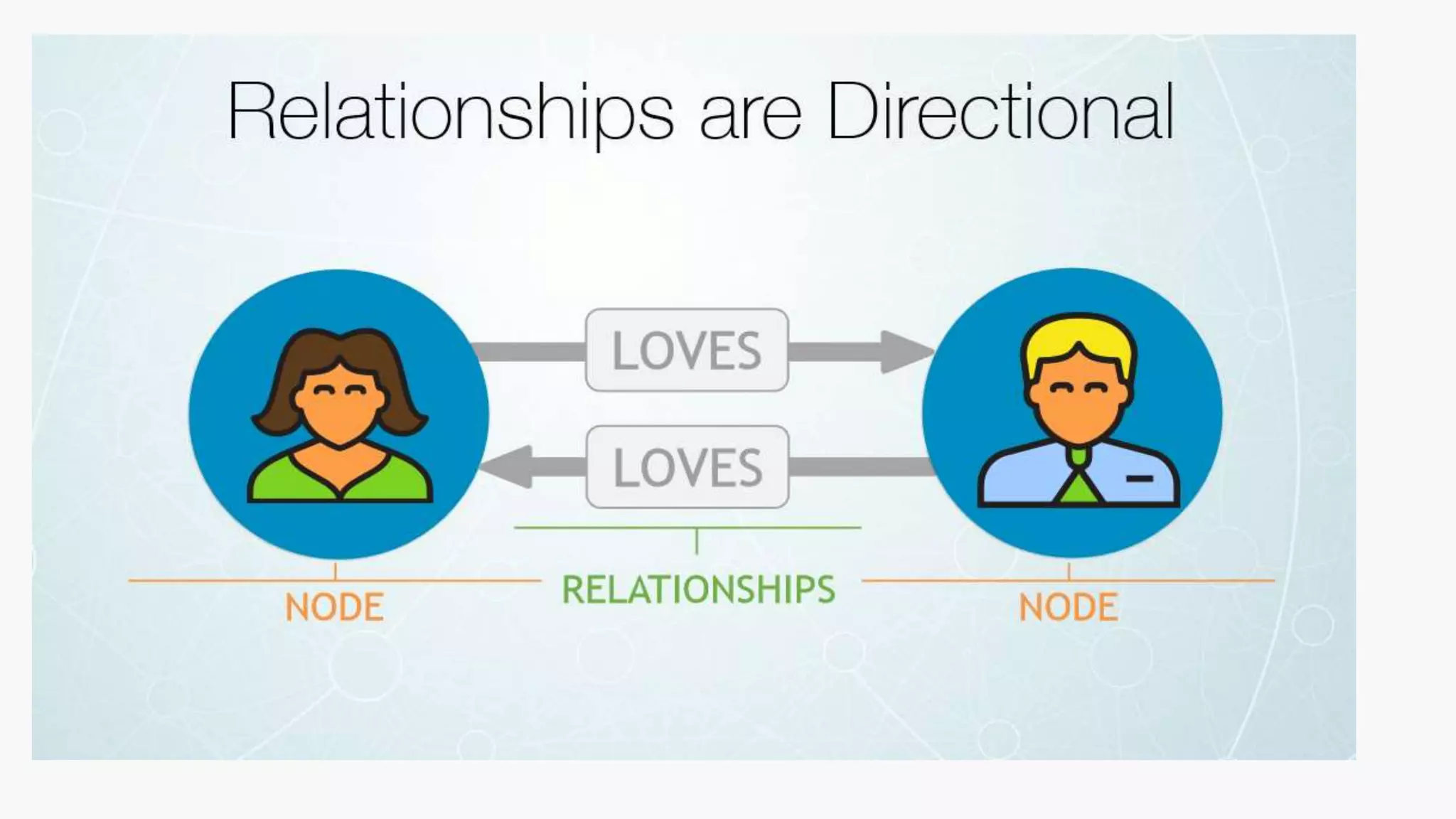
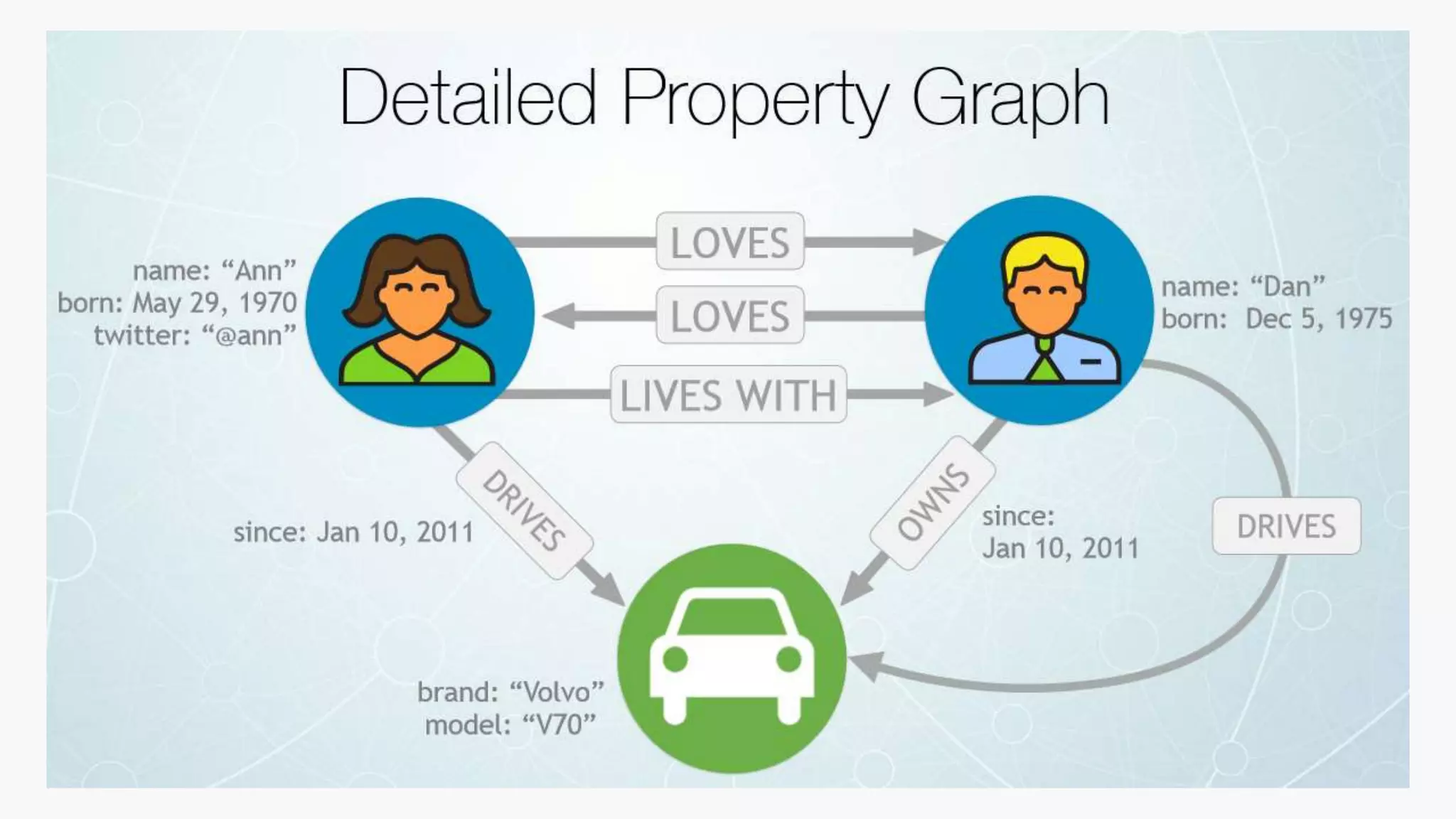
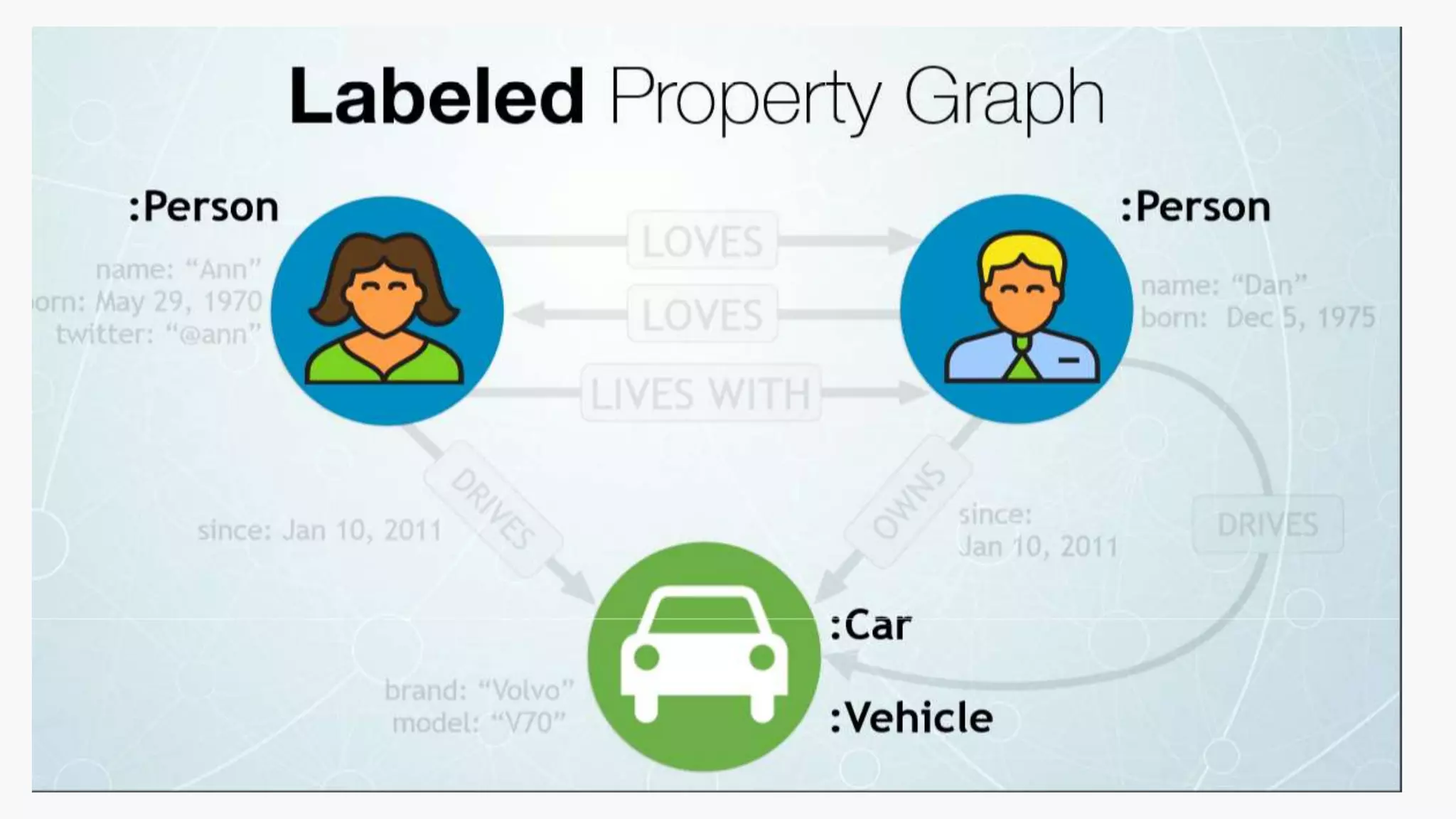
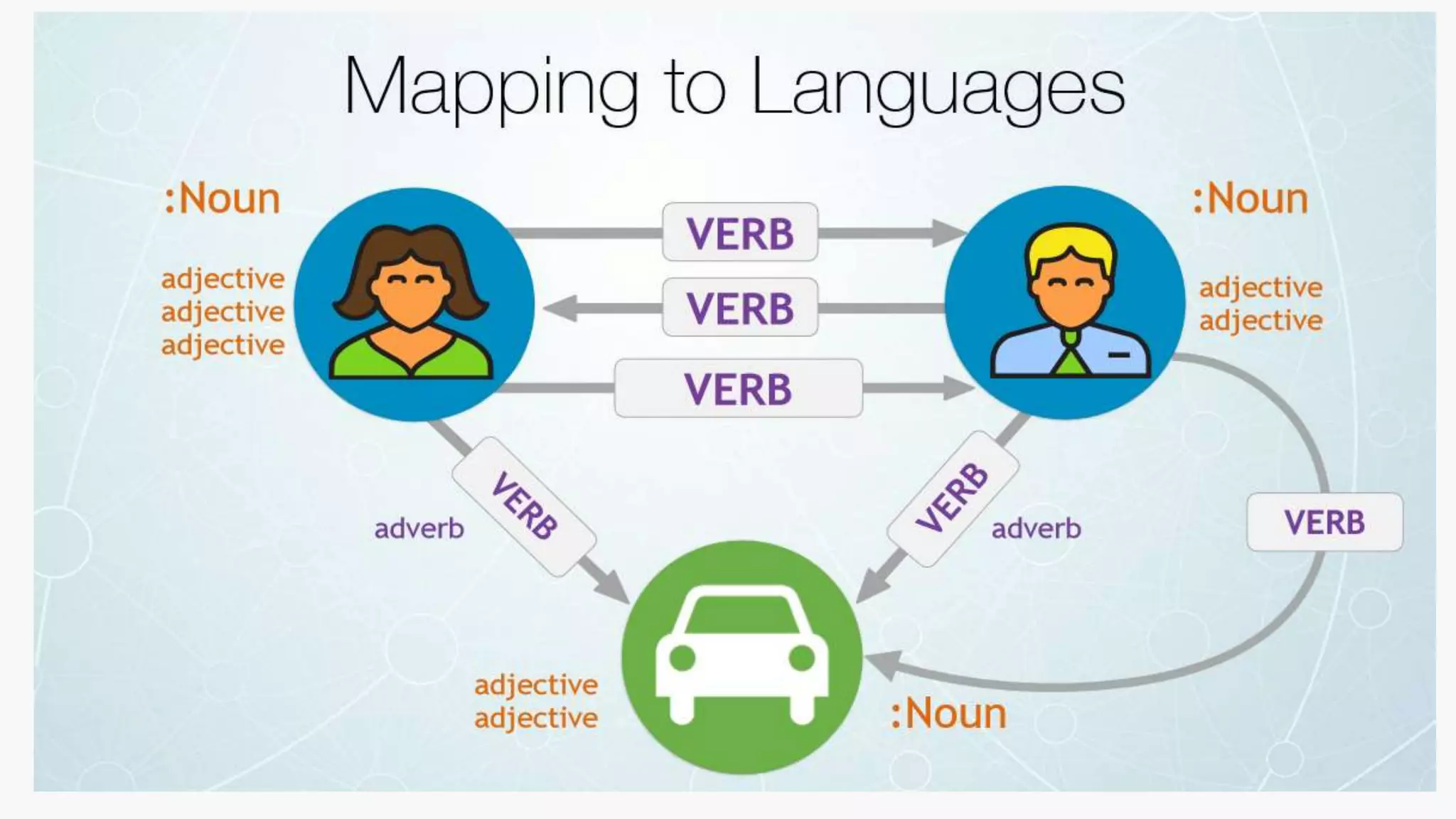
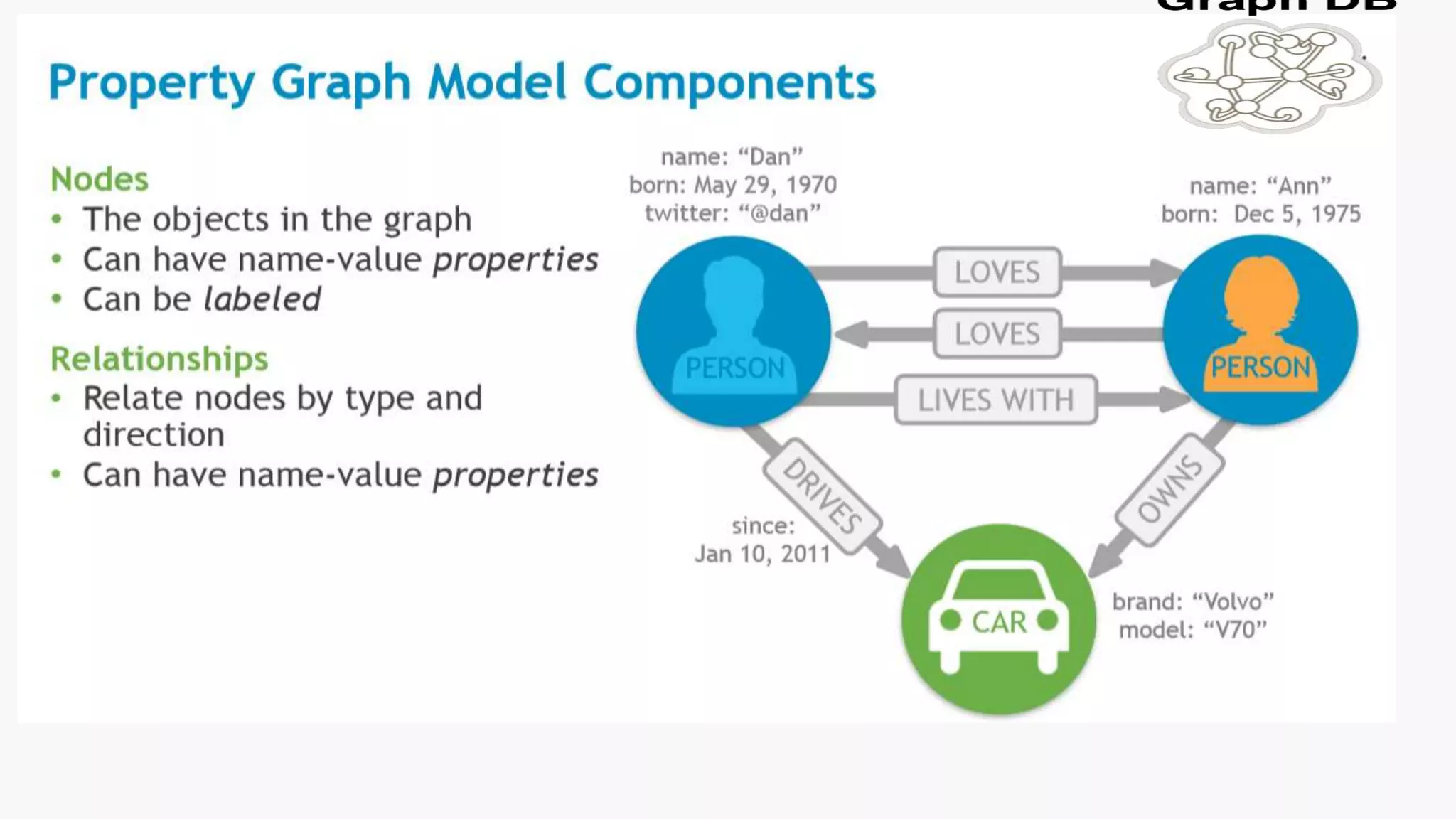


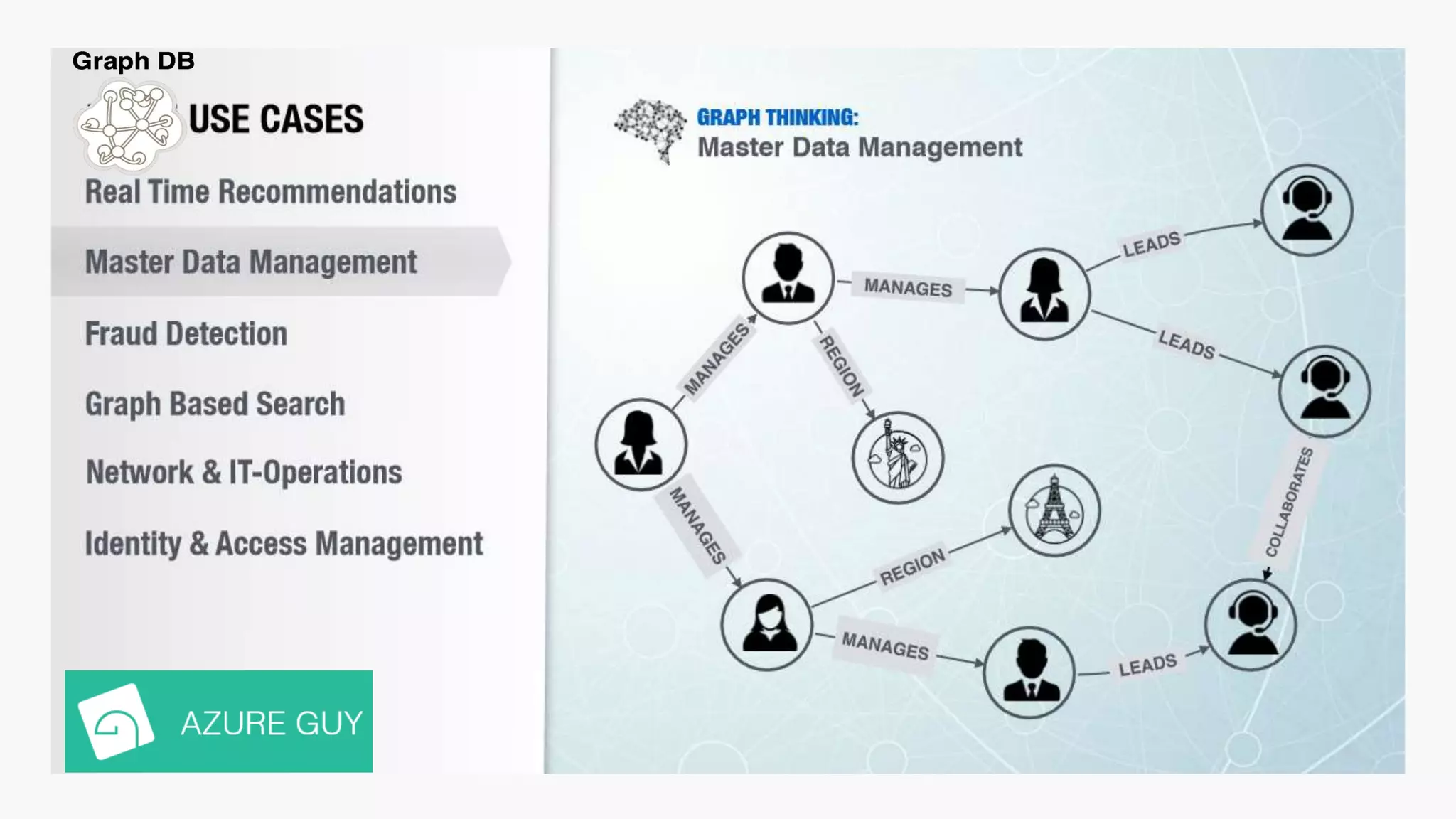
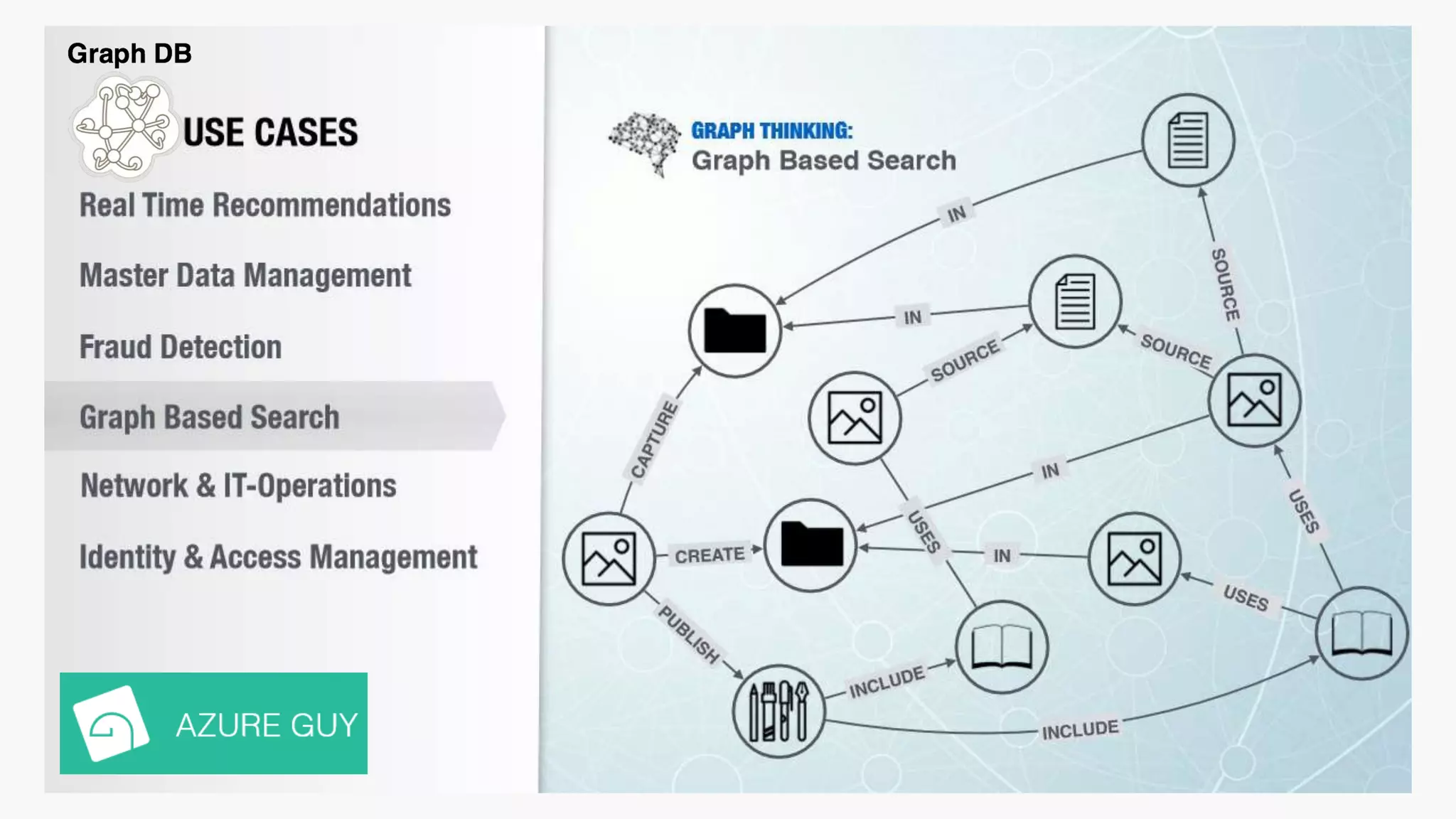
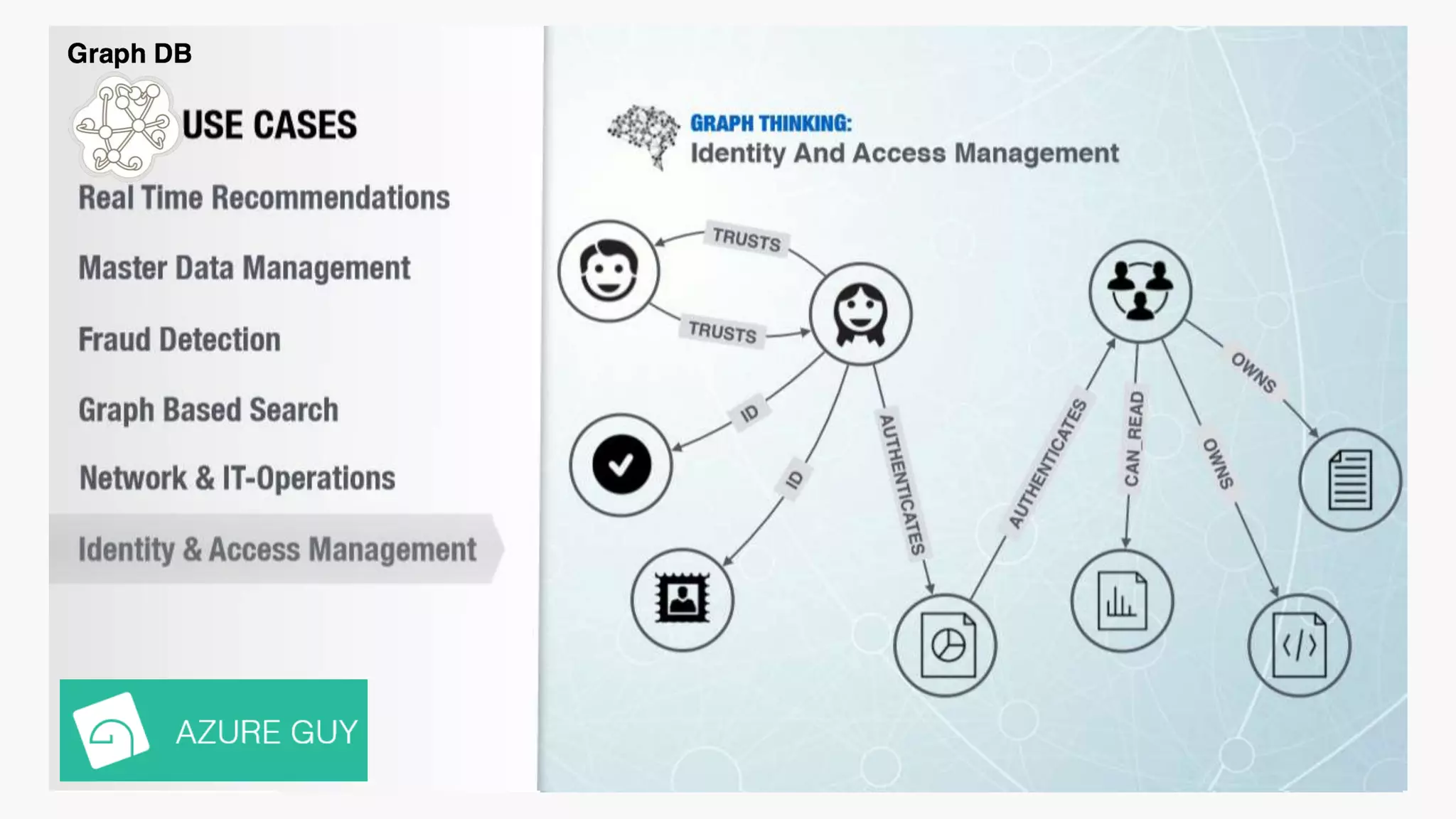




SQL databases use a relational model and are vertically scalable, while NoSQL databases are non-relational, horizontally scalable, and support semi-structured or unstructured data. NoSQL databases provide eventual consistency and are easier for programmers to use compared to SQL databases, which support atomic transactions but can be more difficult for programmers. Common types of NoSQL databases include document, graph, key-value pair, and column-oriented databases.

































































