Download to read offline





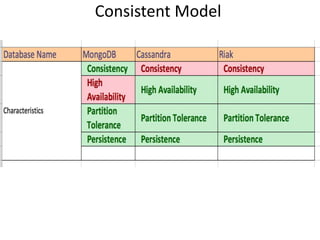





Bansilal Haudakari is a Sun Certified Enterprise Architect with expertise in NoSQL databases, focusing on various data models such as document, key-value, column, and graph models. The presentation covers key considerations for NoSQL, including data and query models, scalability, APIs, and operational costs, alongside specific databases like MongoDB, Redis, HBase, and Neo4j. It emphasizes the importance of consistent models, commercial support, and community strength in NoSQL implementations.