Download to read offline











![So, what are the problems ?
The previous pipeline is said to have been stalled for more than one clock cycle.
Any condition that causes a pipeline to stall is called a hazard.
Data hazard any condition in which either the source or the destination operands
of an instruction are not available at the time expected in the pipeline.
Instruction (control) hazard – a delay in the availability of an instruction causes the
pipeline to stall.[cache miss]
Structural hazard the situation when two instructions require the use of a given har
dware resource at the same time.](https://image.slidesharecdn.com/corepipeliningpresentation-200601035036/85/Core-pipelining-16-320.jpg)










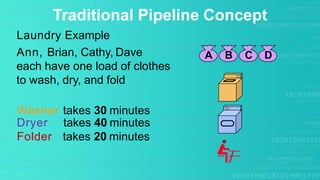
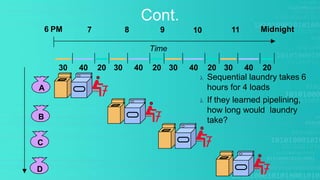
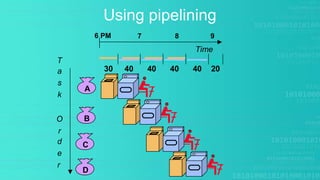
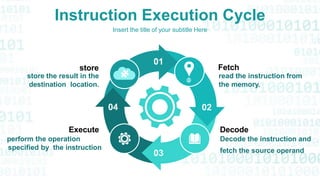
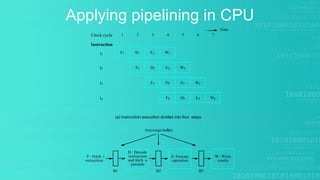
This presentation provides an overview of instruction pipelining in computer processors. It begins with defining pipelining as a process that allows storing, prioritizing, managing and executing tasks and instructions in an orderly process within a single processor. This allows faster throughput than processing instructions sequentially. The presentation then discusses how pipelining improves performance by overlapping the fetch, decode, execute, and write stages of instruction processing. It also identifies potential problems like data hazards that can occur and techniques like forwarding to handle hazards. In the end, the presentation demonstrates pipelined instruction processing and encourages questions.








































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)




![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)









