Download to read offline







![Mark I Perceptron [1950]
13](https://image.slidesharecdn.com/convolutionalneuralnetworks-180612133837/75/Convolutional-neural-networks-13-2048.jpg)



![Neocognitron [Fukushima 1980]
23](https://image.slidesharecdn.com/convolutionalneuralnetworks-180612133837/75/Convolutional-neural-networks-22-2048.jpg)
![LeNet-5 [LeCun, Bottou, Bengio, Haffner 1998]
24](https://image.slidesharecdn.com/convolutionalneuralnetworks-180612133837/75/Convolutional-neural-networks-23-2048.jpg)
![AlexNet [Krizheveskhy, Hinton, Sustsker 2012]
25](https://image.slidesharecdn.com/convolutionalneuralnetworks-180612133837/75/Convolutional-neural-networks-24-2048.jpg)
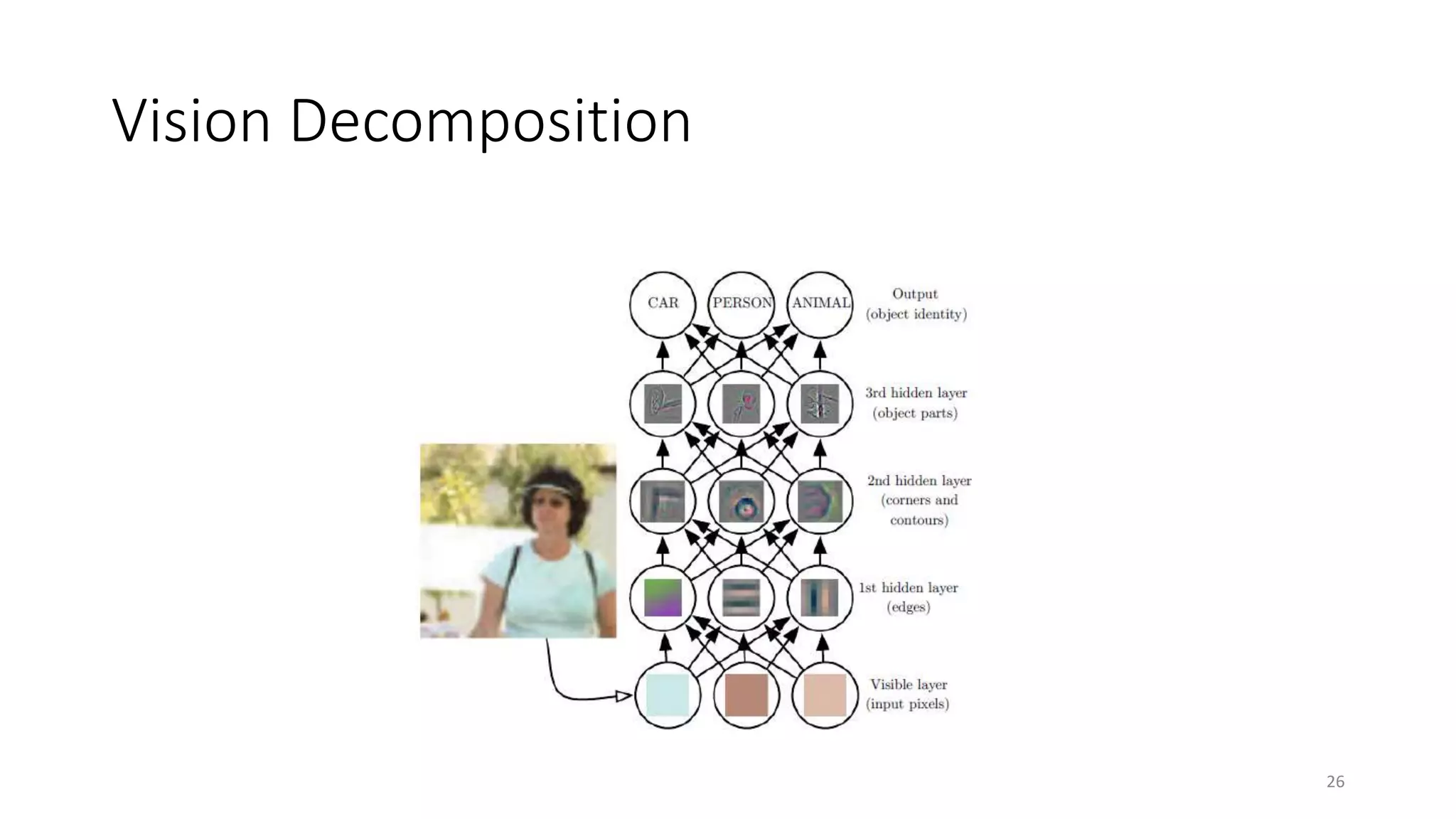
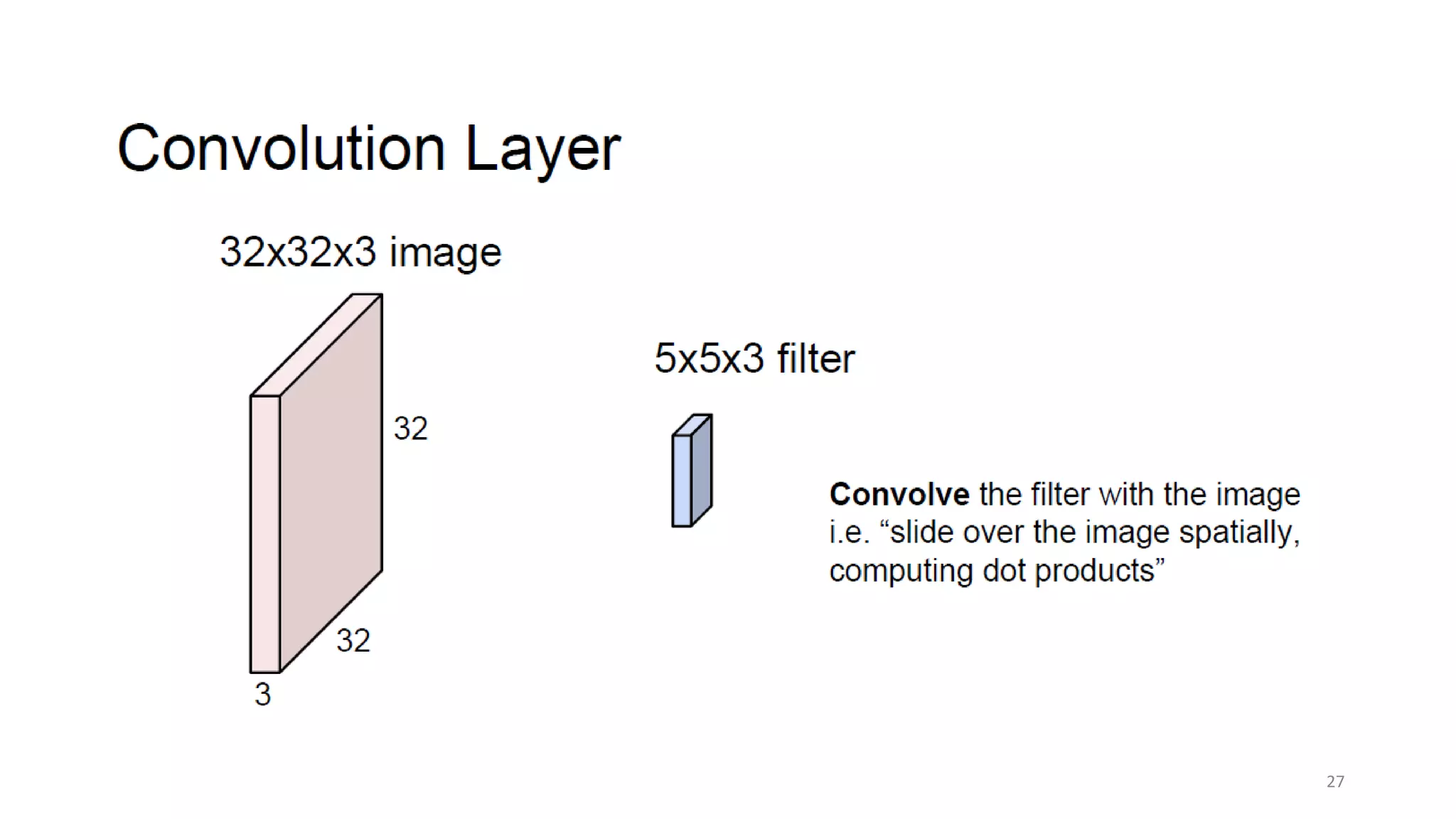
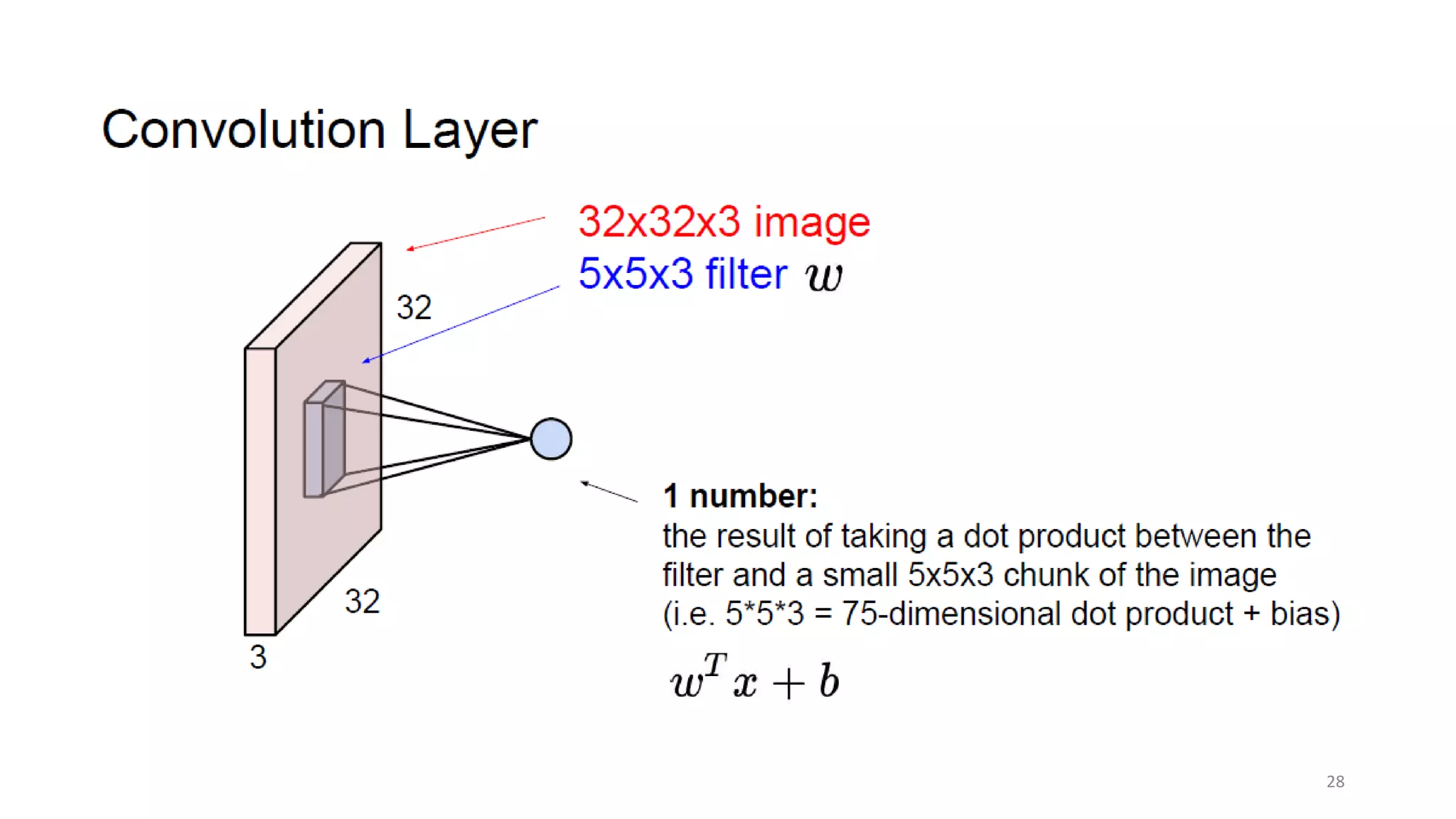
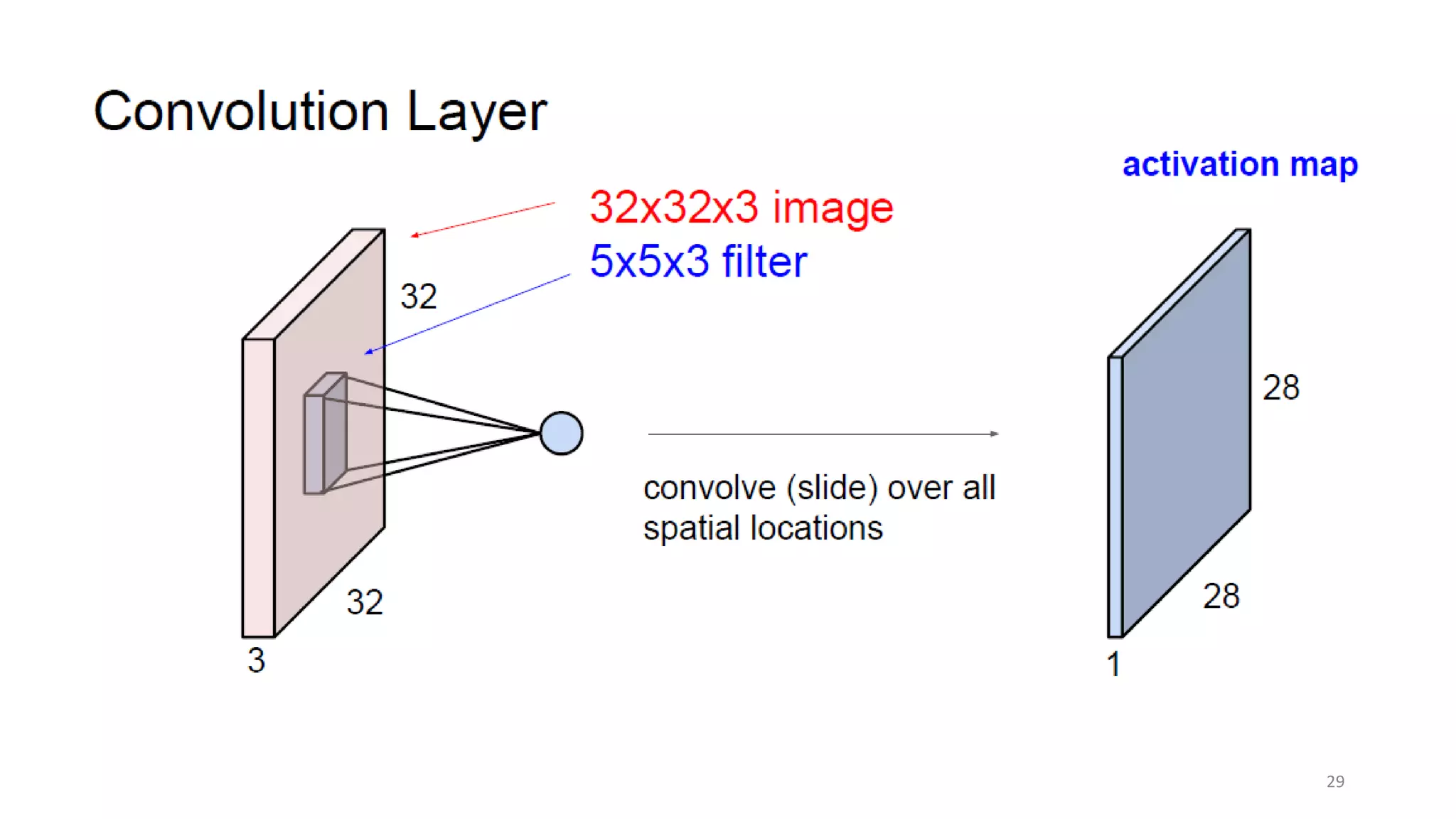
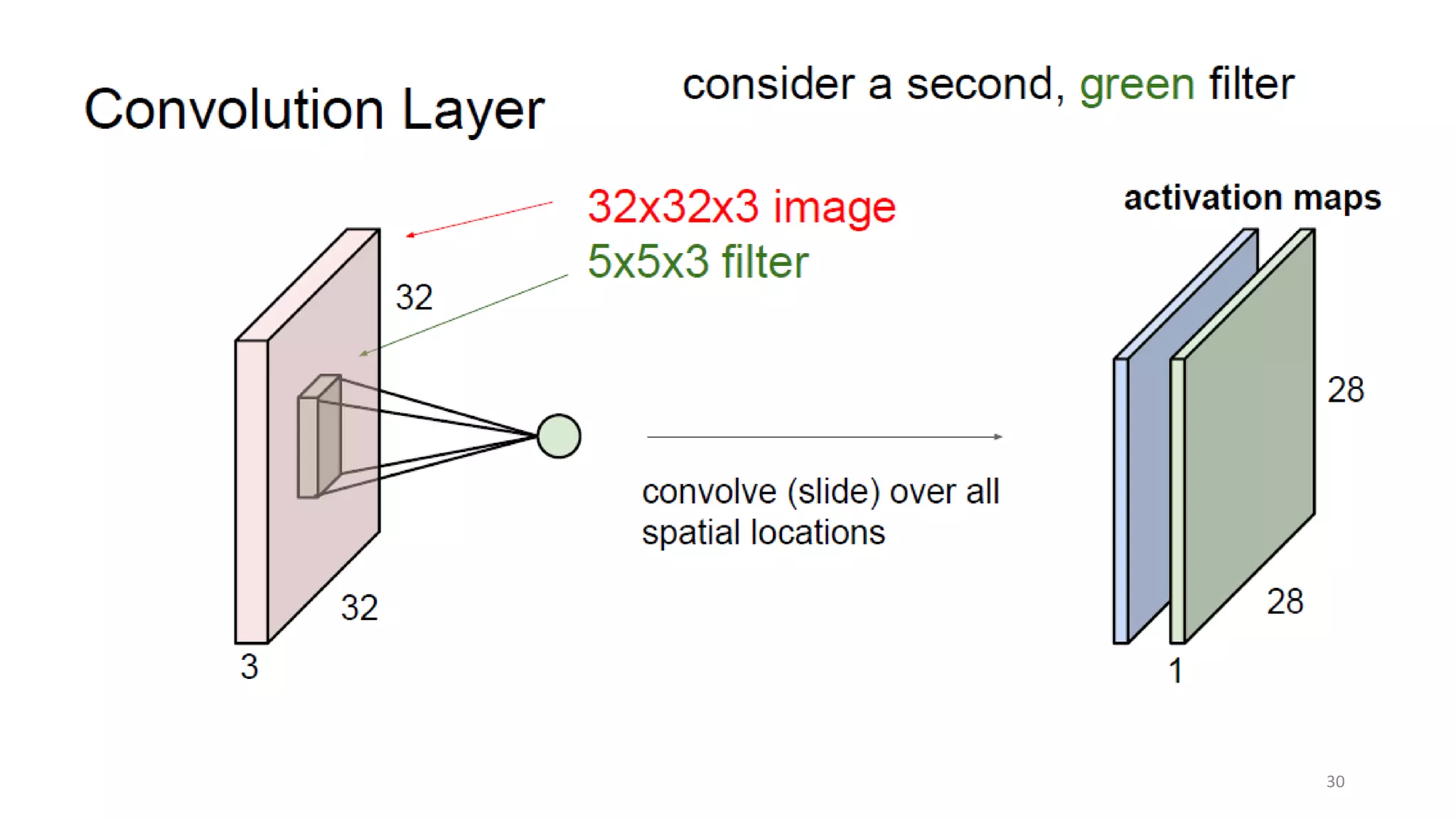
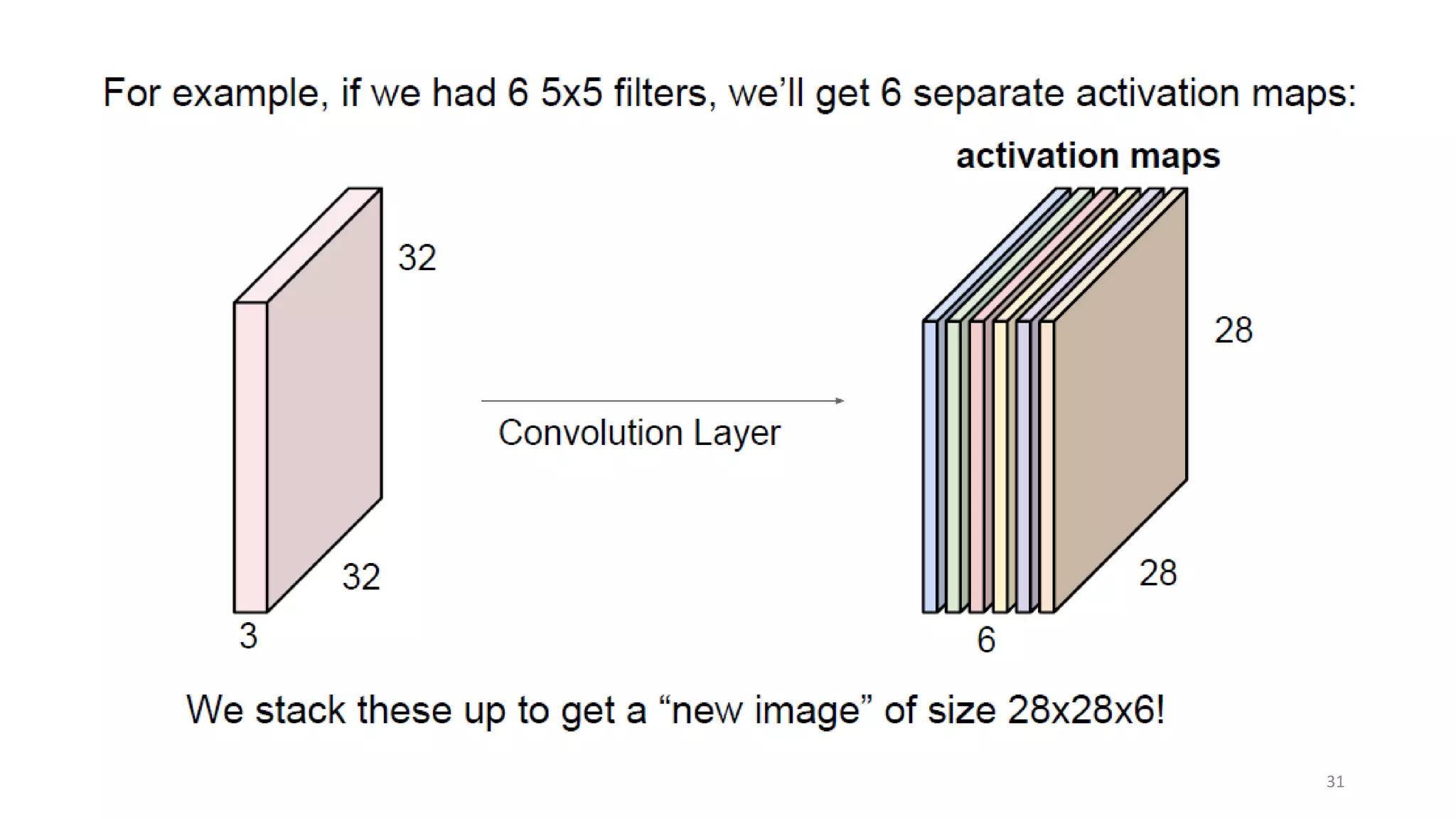
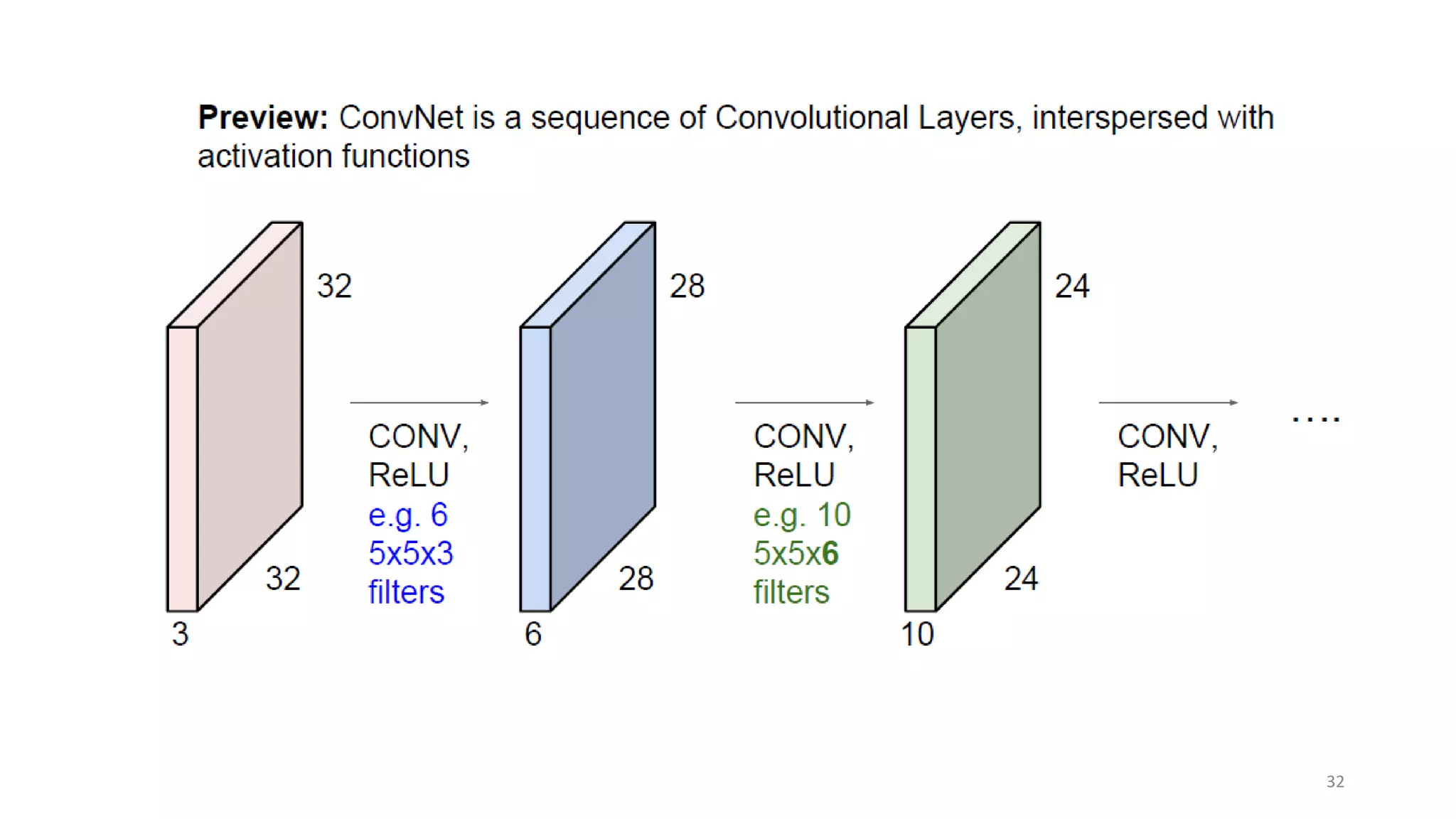
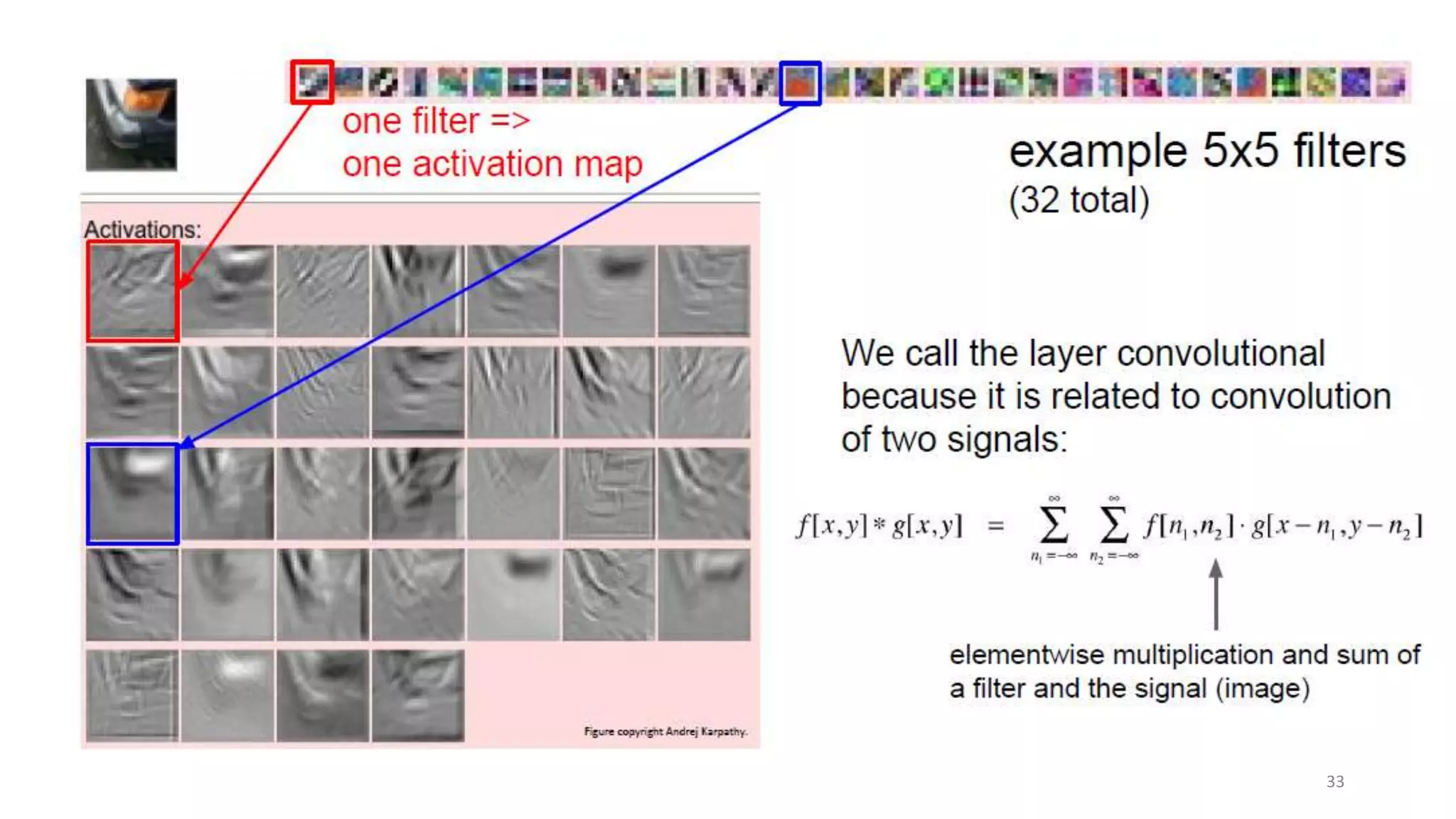
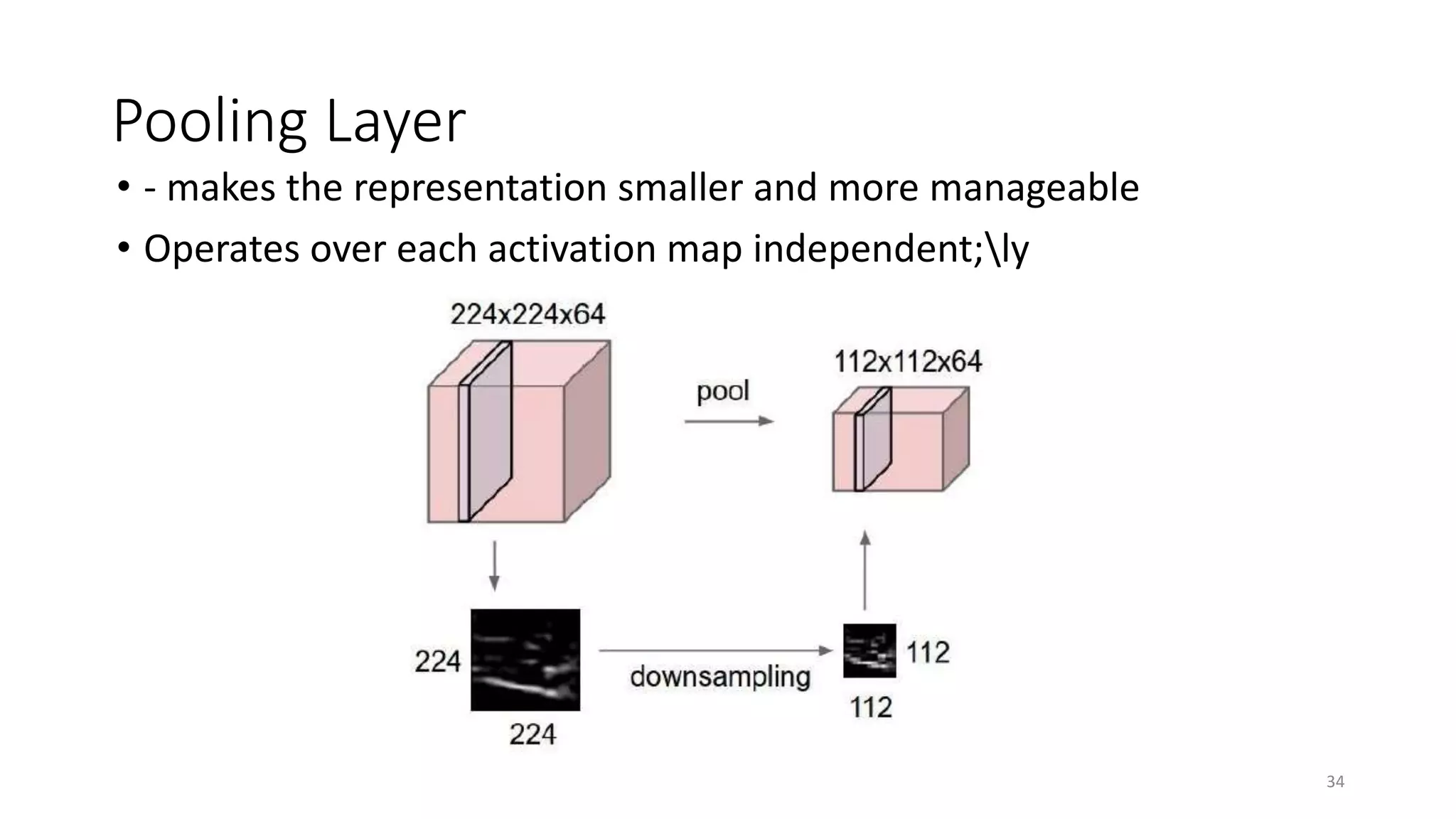
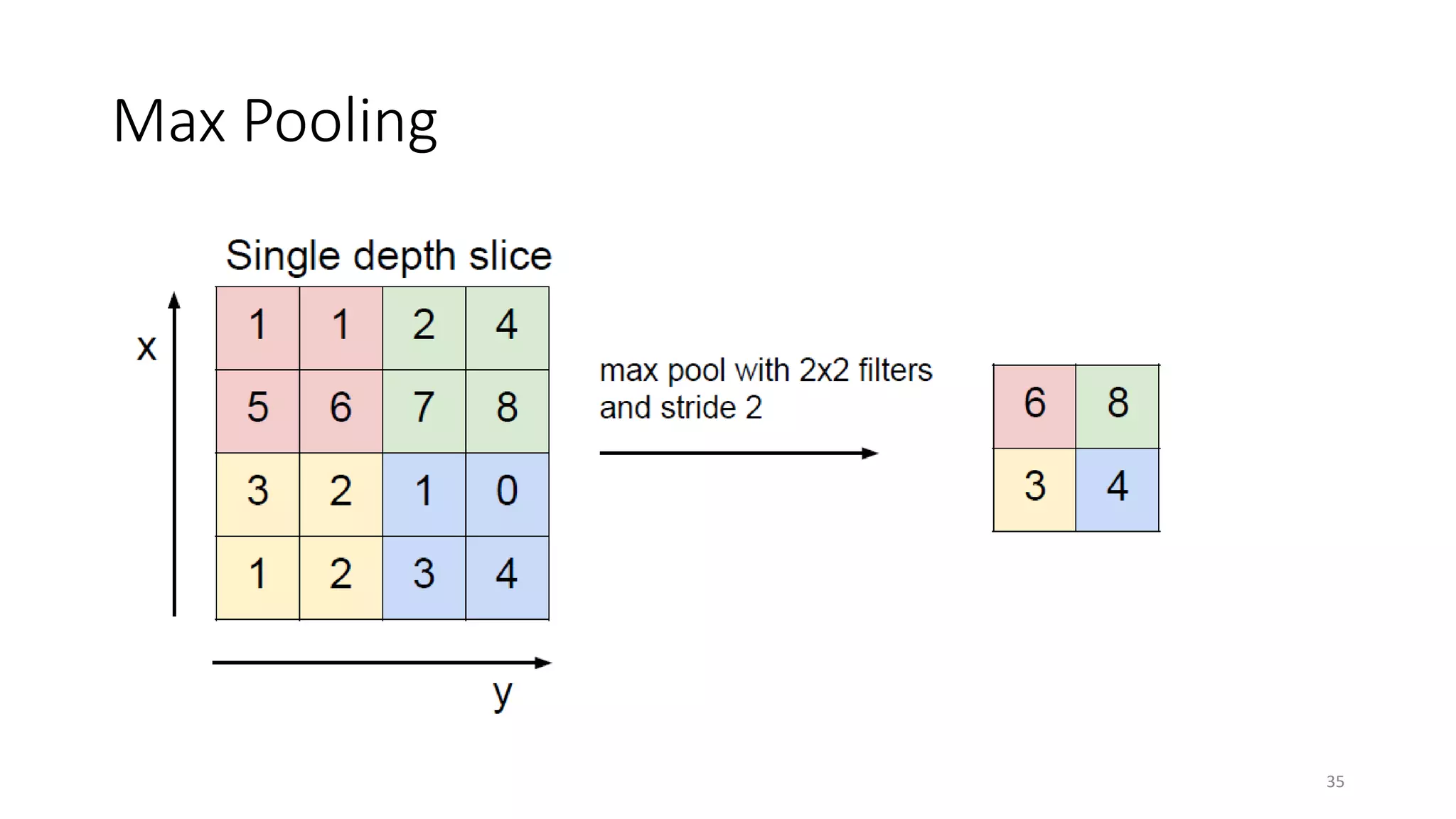






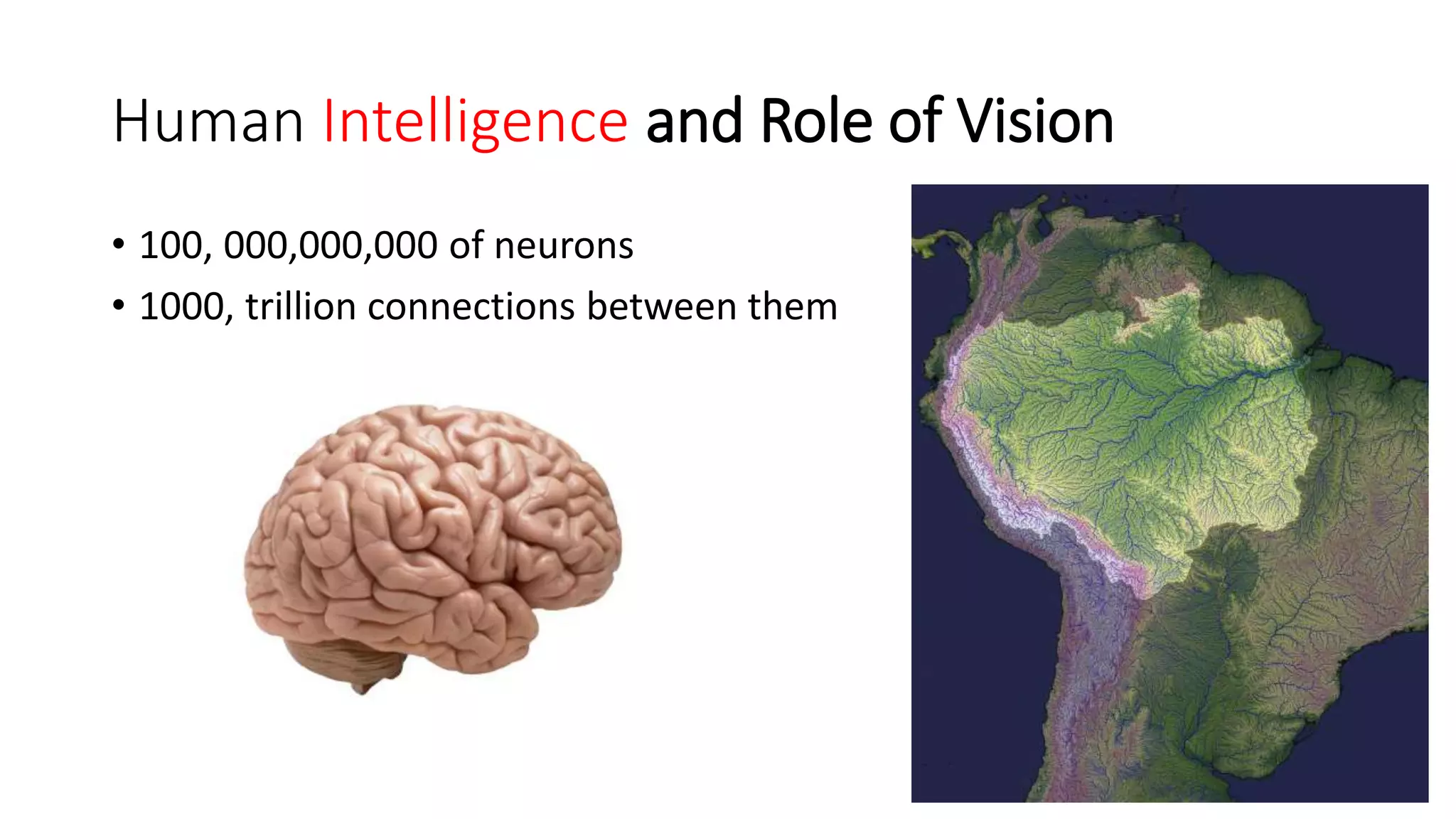
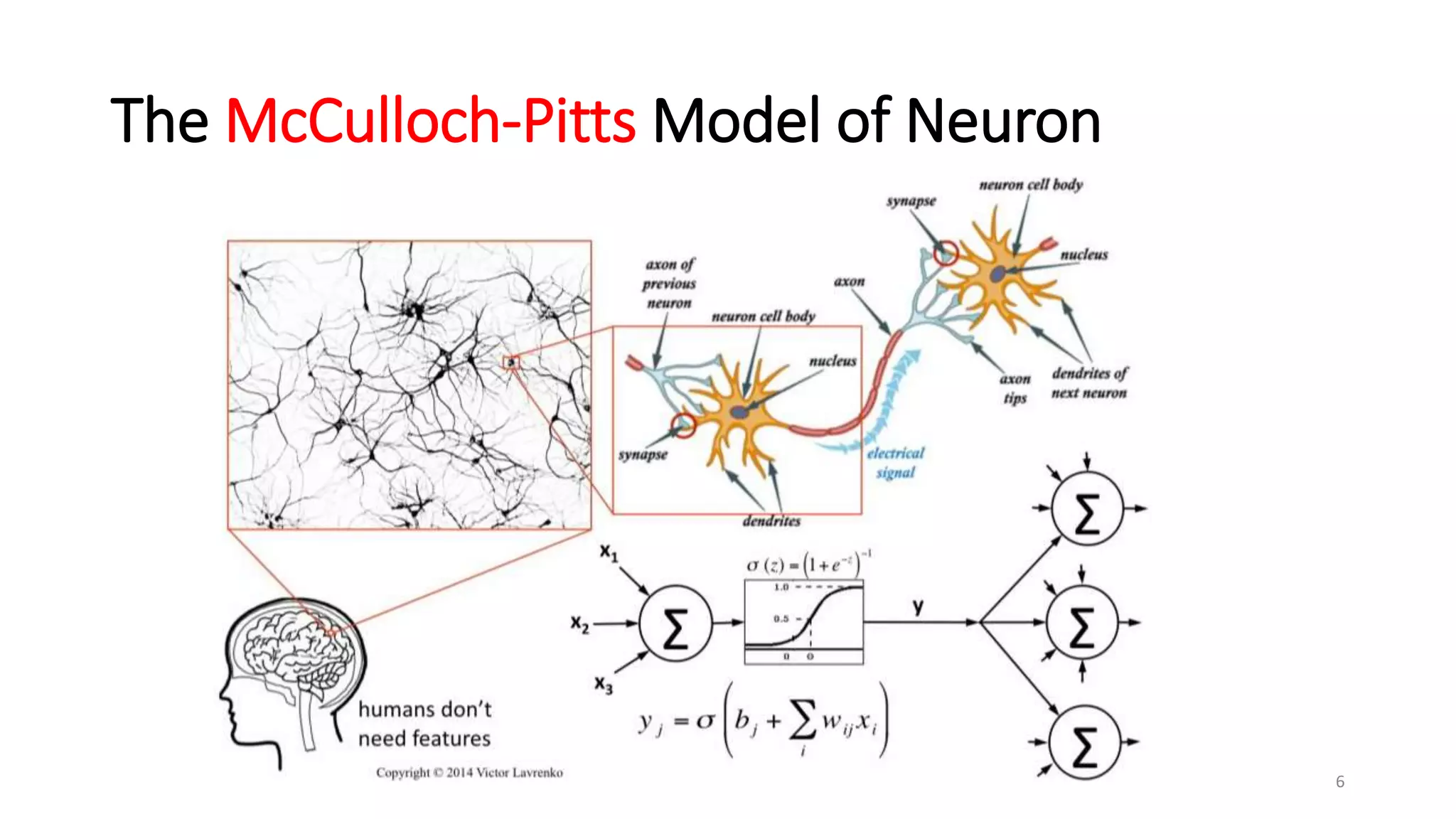
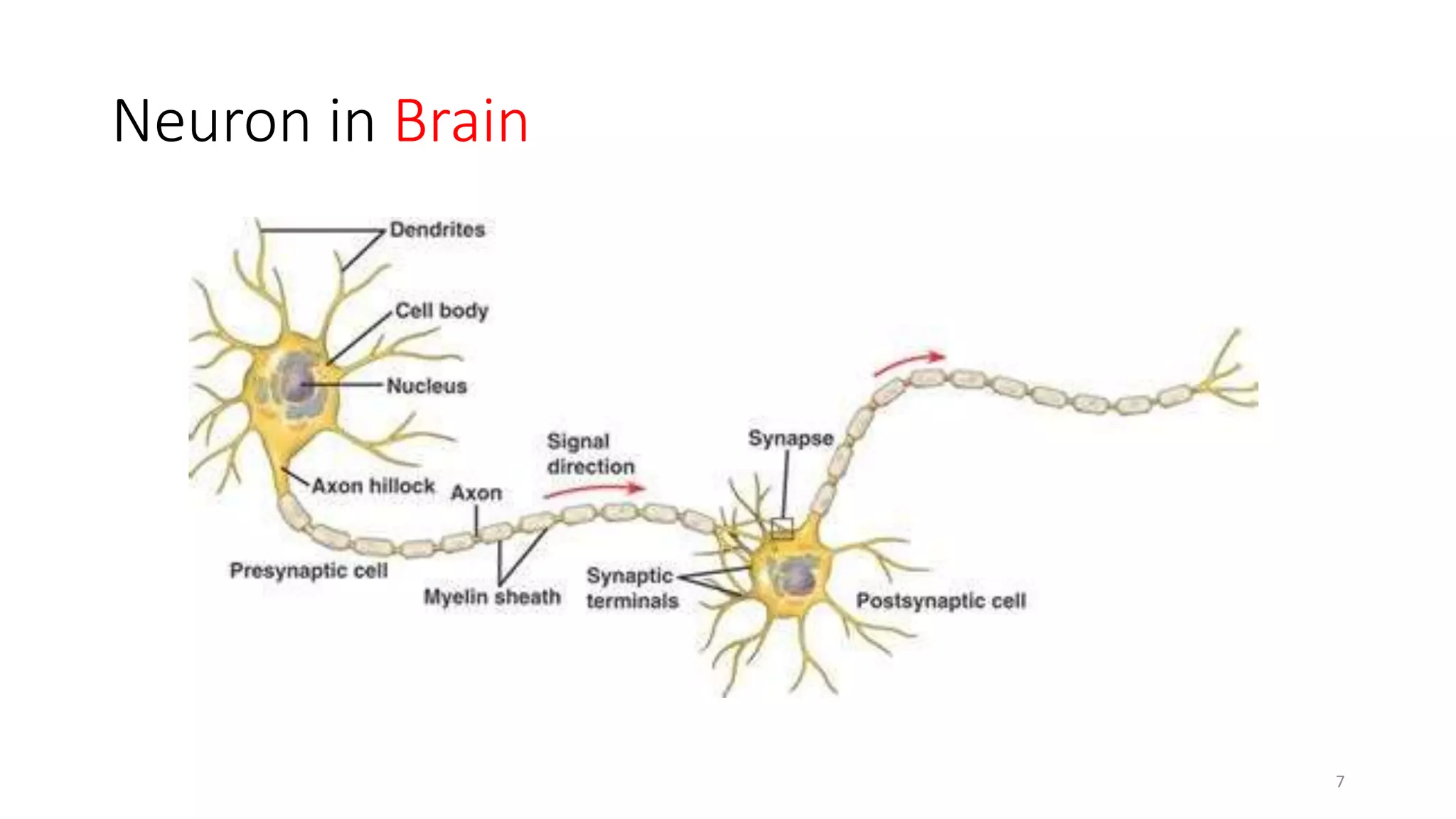
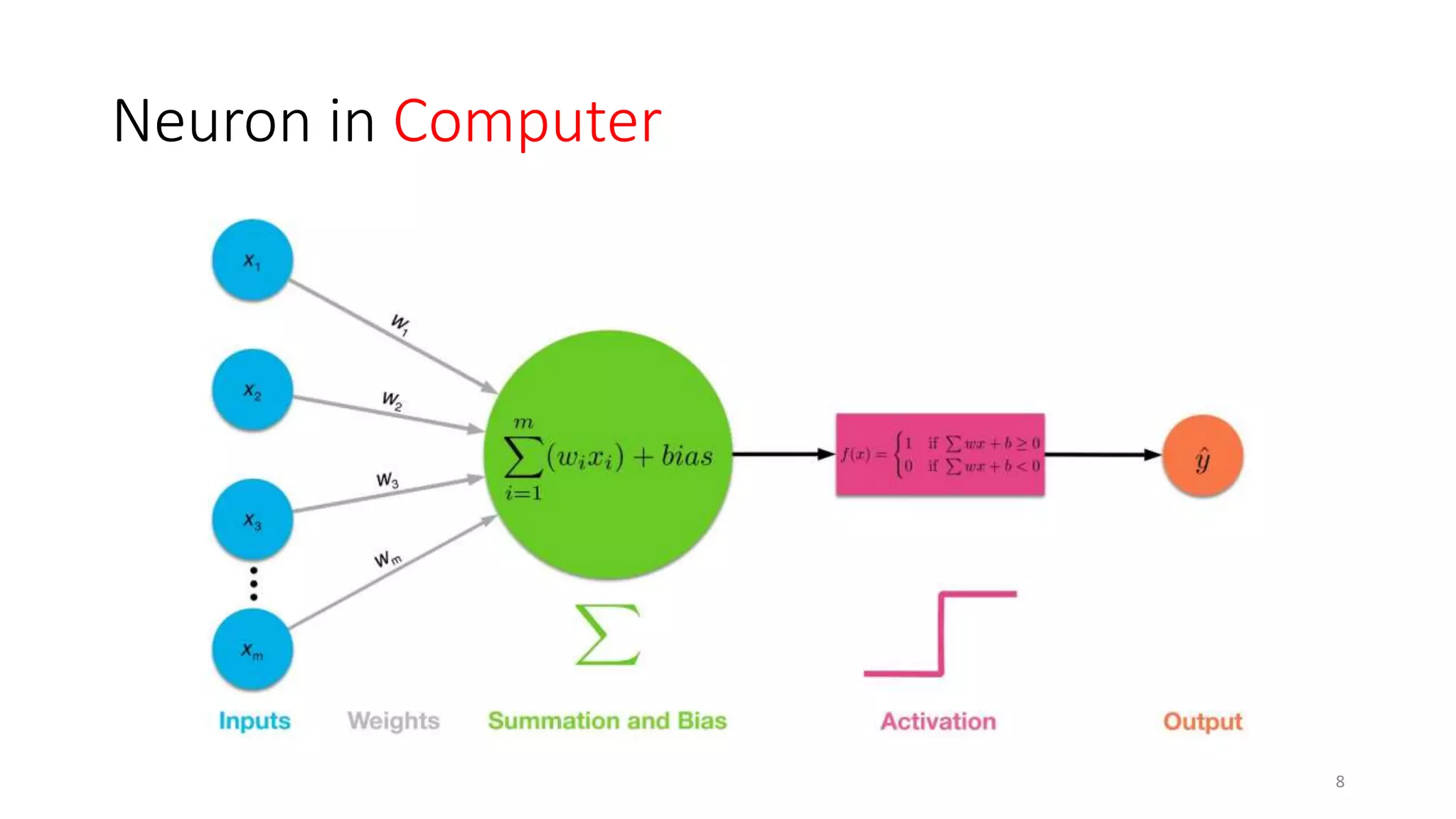
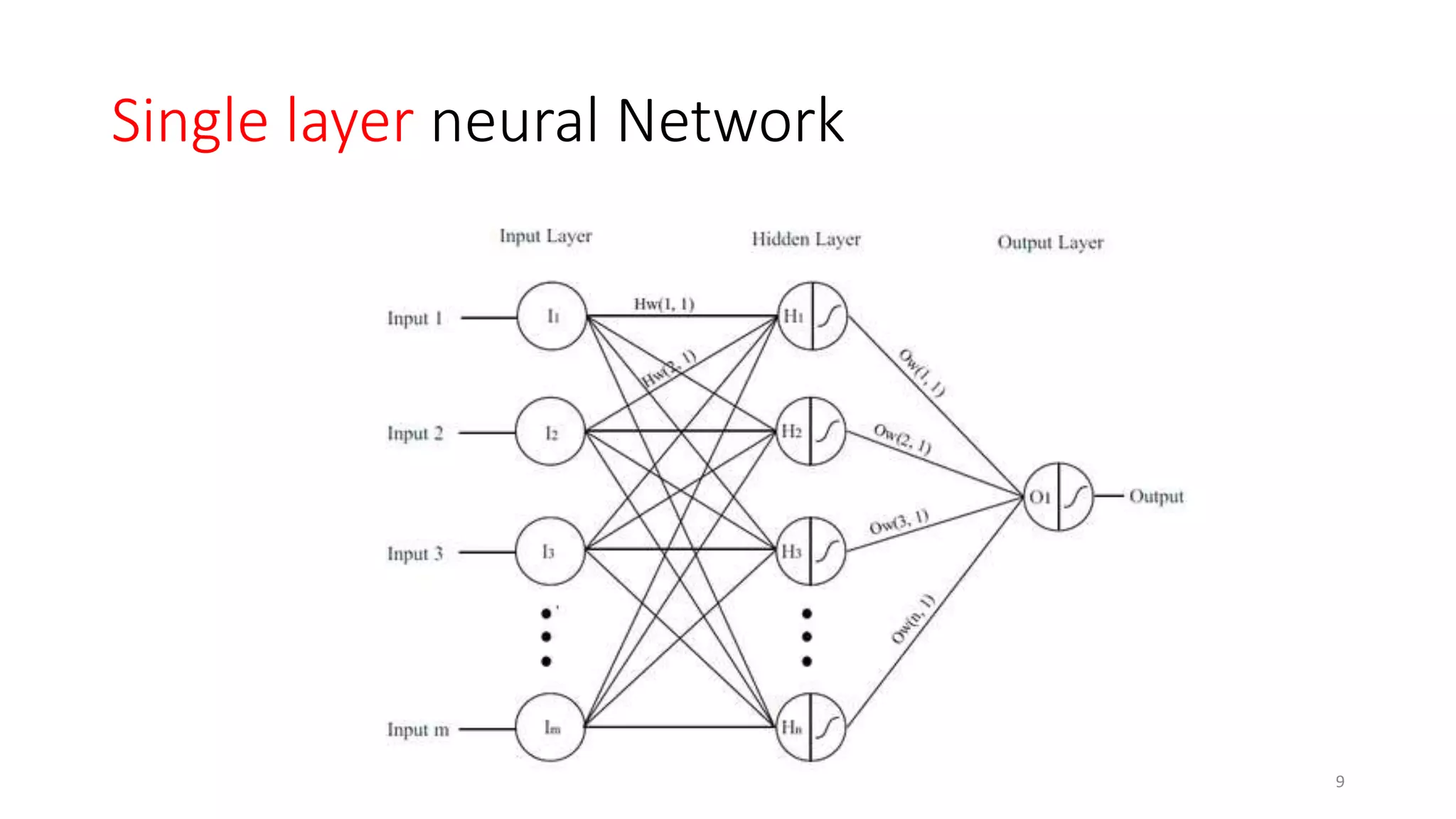
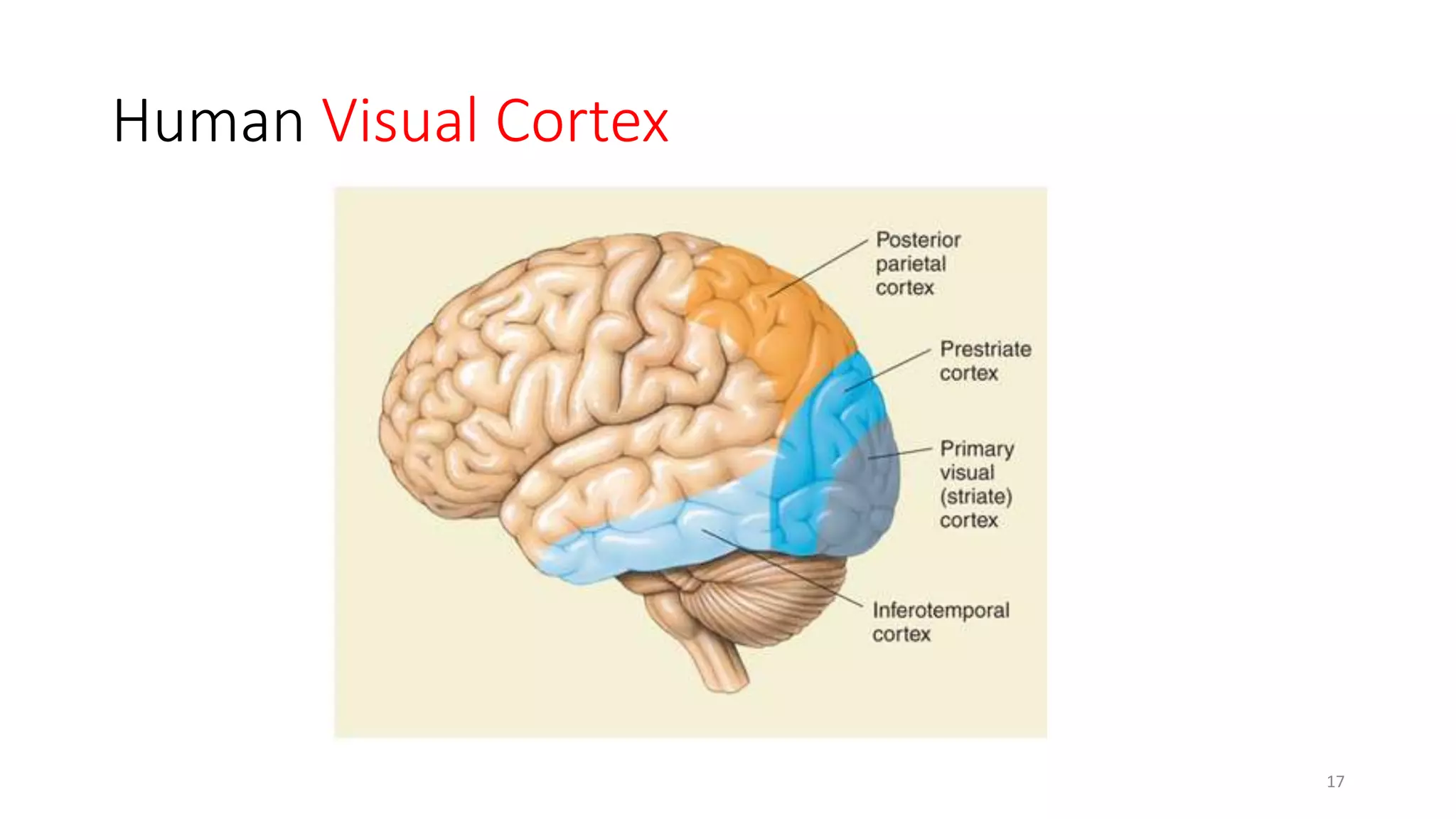
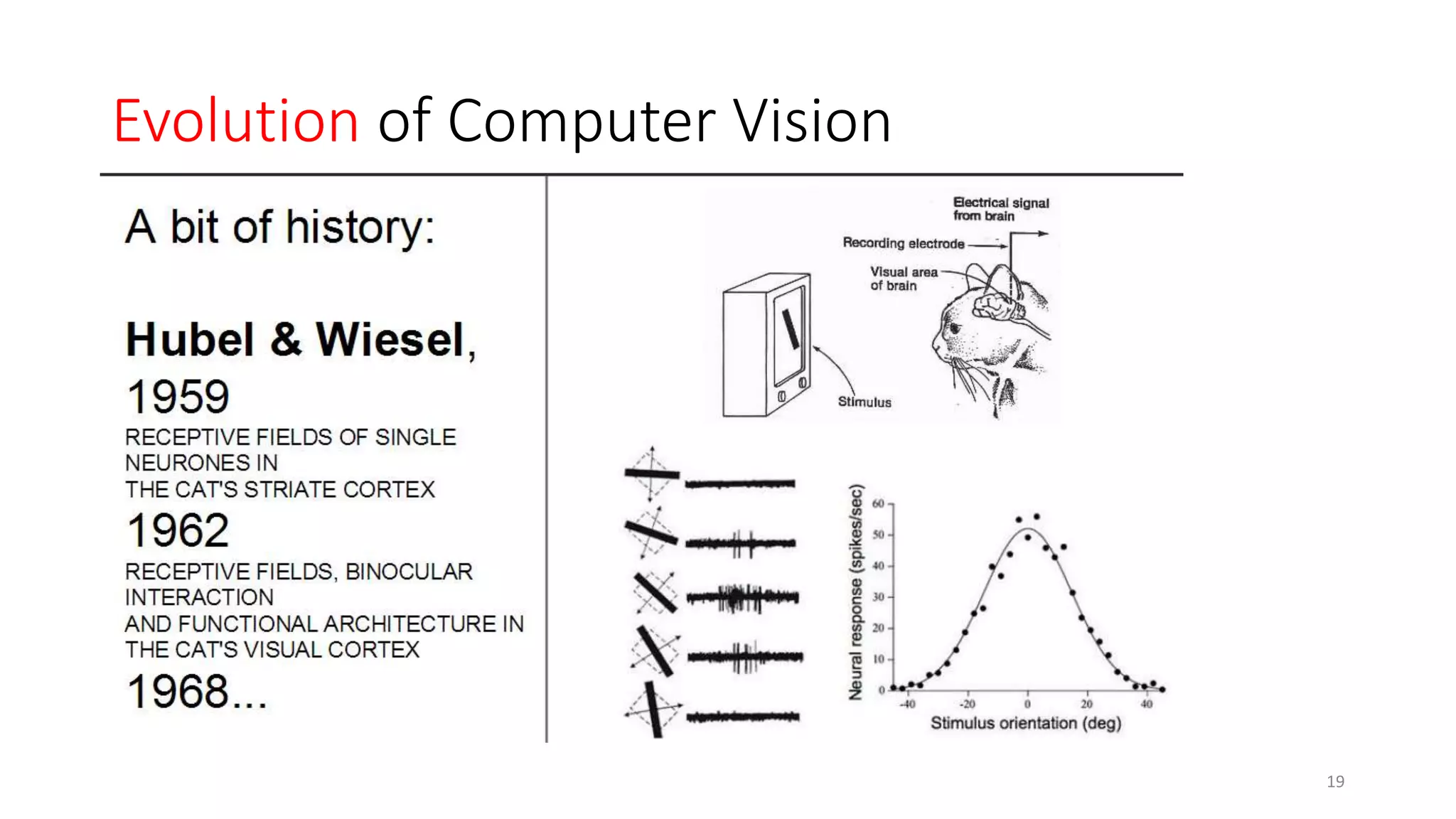
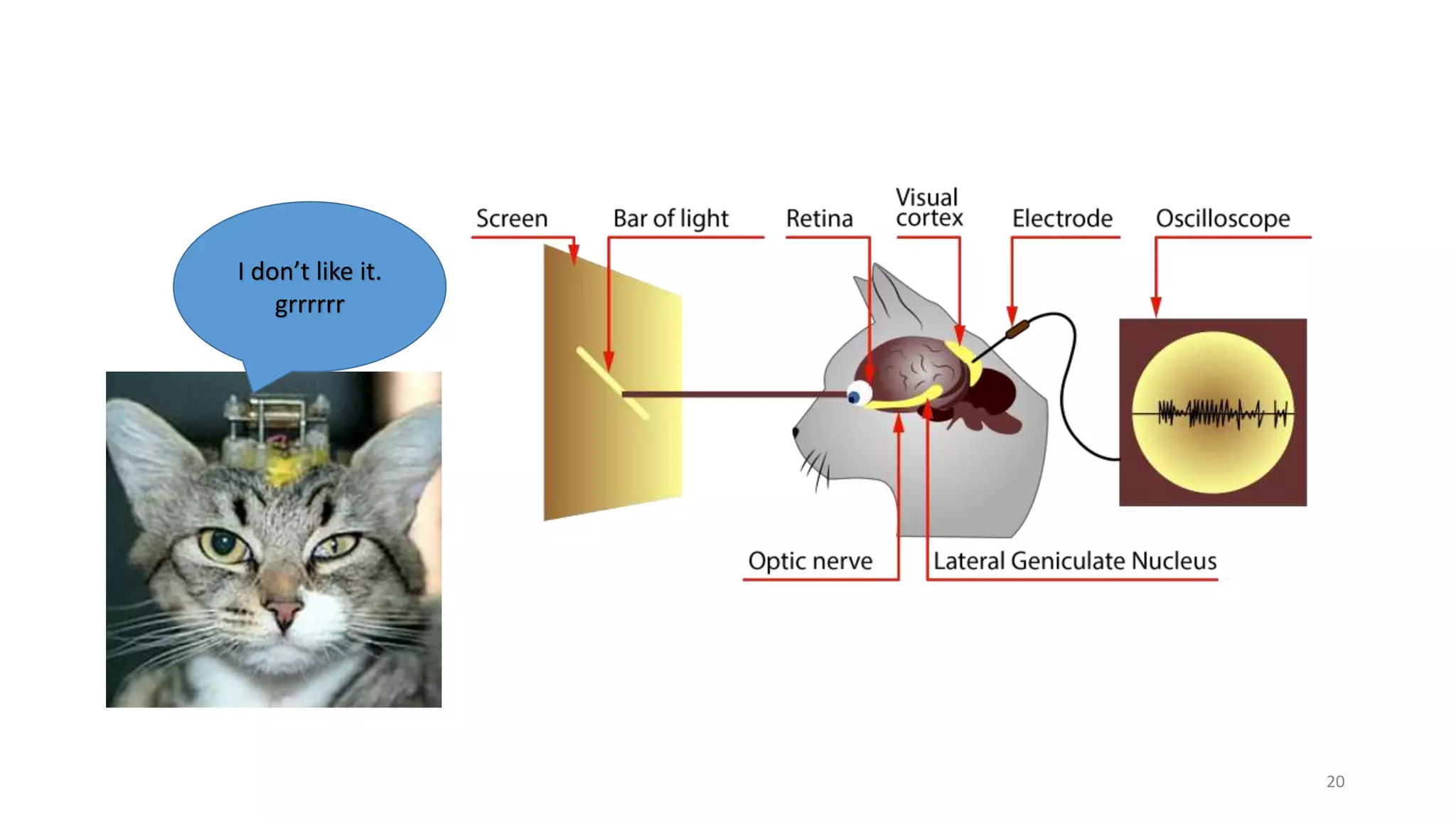
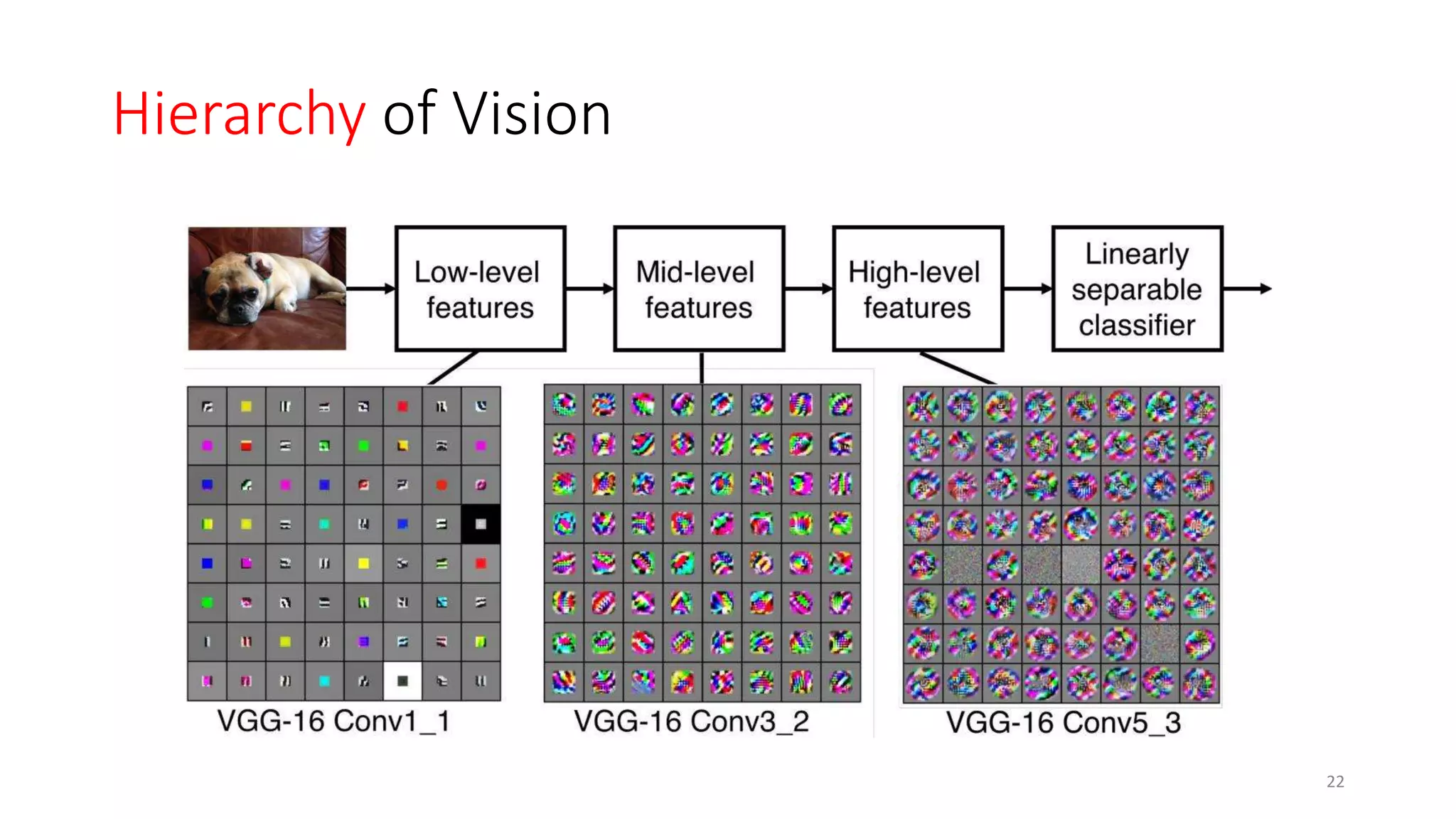
Computer vision aims to make sense of the vast amounts of visual data on the internet. It has applications for autonomous vehicles to interpret images of the road. The human visual system has over 100 billion neurons and 1000 trillion connections that allow us to perceive the world. Computer vision systems draw inspiration from the human visual cortex, with convolutional neural networks that mimic the visual hierarchy in the brain. While systems have improved at tasks like image classification, computers still lack the human ability to understand context and assign meaning based on surroundings.






















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












