Download to read offline



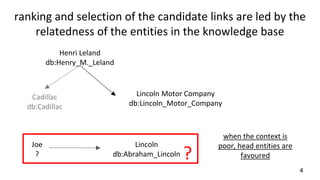
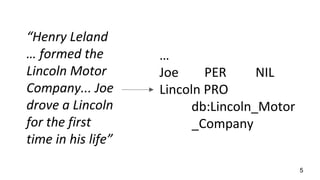
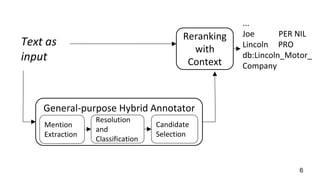
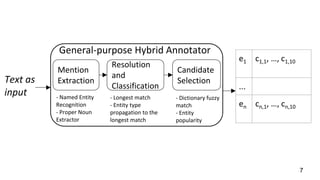


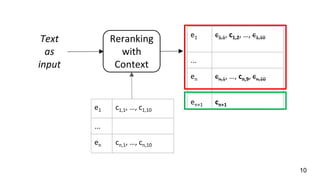






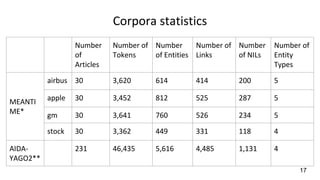
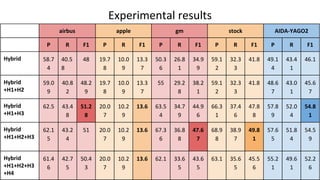




This document describes a context-enhanced adaptive entity linking approach. It summarizes three existing entity linking approaches: linguistic, end-to-end, and hybrid. It then presents a general-purpose hybrid annotator for entity linking that uses mention extraction, candidate selection, and resolution/typing. The approach is improved by reranking entities with contextual heuristics like coherence, domain relevance, and semantic typing. Experimental results on news corpora show the contextual reranking improves over the baseline, especially when using domain relevance heuristics. Future work involves better modeling genres/topics and investigating dynamic adaptability in different contexts.










































































































