
Recommended
More Related Content
Similar to ContentMine Architecture
Similar to ContentMine Architecture (20)
More from petermurrayrust
More from petermurrayrust (20)
Recently uploaded
Recently uploaded (20)
ContentMine Architecture
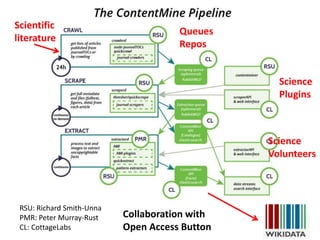
- 1. RSU: Richard Smith-Unna PMR: Peter Murray-Rust CL: CottageLabs Queues Repos Scientific literature Science Plugins Science Volunteers Collaboration with Open Access Button
- 2. quickscrape Crawl Feed Norma Index & Transform PDF XML URL DOI Scientific literature Repositories DOC CSV sHTML Plugins Regex SequencesSpecies Bespoke Scrapers XPathPer-Journal Taggers Per- Journal MetadataChemistry Phylogenetics Farming AMI BadHTML OCR Diagrams Open NORMA-lized Scientific Literature + Facts CANARY pipeline CAT-alogue index
- 4. Starting points • Search/Crawl/Feed-> PMCID,DOI,URL -> quickscrape -> CMDir(PDF,HTML,XML,images/,meta) -> Norma -> CMDir(sHTML|TXT|SVG) good • PDF,XML,HTML -> Norma -> CMDir(PDF,rawHTML,TXT,images/,meta?) -> NormaOCR -> CMDir(sHTML,TXT,SVG) variable
- 5. Conversions • Paper-> Scanned -> TIFF (avoid) • PDF,TIFF,PNG -> Tesseract-N -> HTML, SVG fast, variable • PDF -> PDF2SVG-N -> sHTML, SVG, images/. slow, accurate-ish • PDF -> PDF2TXT-N -> TXT fast, variable • PDF -> PDF2Image-N -> PNG fast, accurate
- 6. Raw HTML Not wellformed Bad character semantics ScholarlyHTML Well-formed XHTML PNG Tagged Sections Captioned Figures Tables Captioned Tables XML HtmlTidy Jsoup HtmlUnit XSLT1/2 XSLT1/2 NORMA Per-journal Stylesheets
- 7. End points • Norma -> CMDir(OpenSHTML-SVG) • Norma -> CMDir(sHTML. sections) -> AMI -> all text + species, chemistry, sequences) • Norma -> CMDir(TXT (unsectioned)) -> AMI -> bagOfWords, regex, • Norma -> CMDir(PNG) -> AMI -> phylo, bar/xy- plots, • Norma -> CMDir(SVG) -> AMI -> phylo, bar/xy- plots, chemistry
- 8. PDF Non-Unicode Pixel glyphs No words No structures ScholarlyHTML SVG High-level graphics PDF2SVG characters Sentences Paras tables PNG OCR Tagged Sections SVGBuilder Captioned Figures NORMA XSLT1/2
- 9. NORMALIZE Norma Convert PDF,XML To sHTML Tag sections Normalized Scientific Literature AMI Index Transform Extract Search PDF2SVG XSL stylesheets Taggers normalization Parameters “Permanent” Filestore Temporary Filestore Extracted facts indexes Plugins Regex