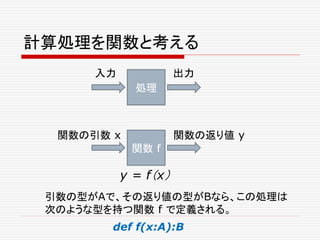
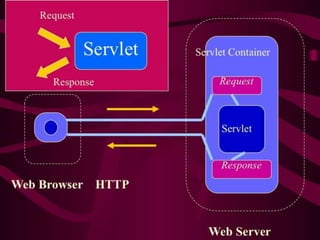
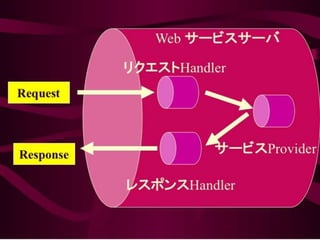
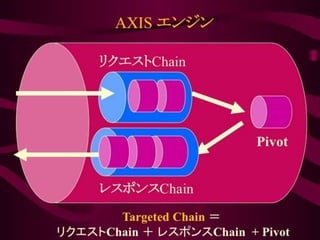
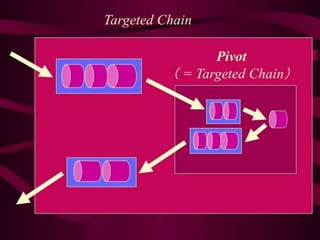
Most of oursystems are big “Future transformers”
- Marius Eriksen
3.
predictable performance isdifficult to achieve. In a predictable system,
worst-case performance is crucial; average performance not so much.
... predictable performance is difficult to achieve.
In a predictable system, worst-case performance
is crucial; average performance not so much.
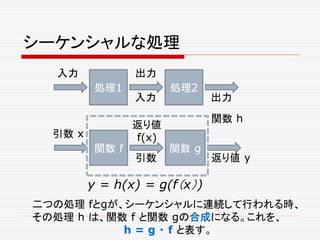
- Peter Schuller
4.
predictable performance isdifficult to achieve. In a predictable system,
worst-case performance is crucial; average performance not so much.
It’s with the intent of modeling a world where the
Twitters, Googles, and Facebooks are no longer
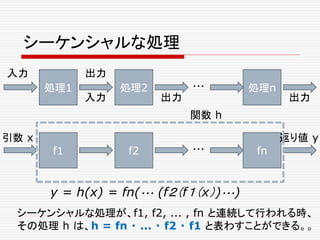
superpowers… just power
- Aurora
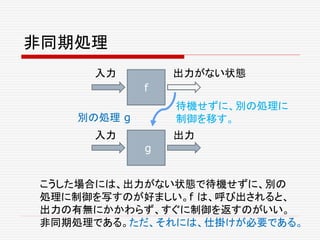
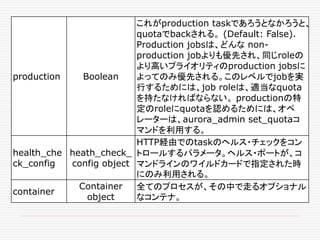
Futuresの値の取得 get
Futureは、ある種のコンテナーである。 traitFuture[A]
それは、empty, full, failedの三つの状態を取る。我々
は、それを待つことができる。その値は getで取得できる。
val f: Future[A]
val result = f()
f.get() match {
case Return(res) => ...
case Throw(exc) => ...
}
ただ、いつ get するのか? せっかく非同期にしたのに、
get の利用は、あまり意味がない
Filterは、積み重ねられる。
val timeout: Filter[…]
valauth: Filter[…]
val service: Service[…]
timeout andThen auth andThen service
def andThen[A](g: (R) ⇒ A): (T1) ⇒ A
Composes two instances of Function1 in a new
Function1, with this function applied first.
def compose[A](g: (A) ⇒ T1): (A) ⇒ R
Composes two instances of Function1 in a new
Function1, with this function applied last.
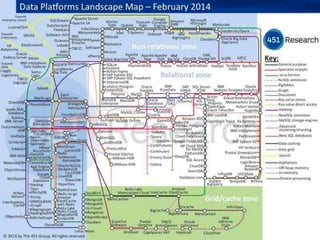
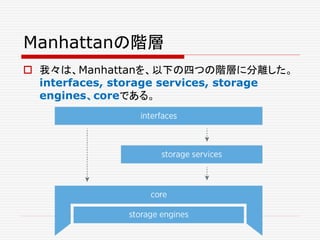
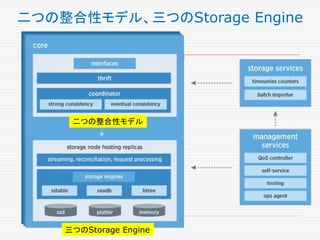
Manhattan, our real-time,
multi-tenantdistributed
database for Twitter scale
April 2, 2014 By Peter Schuller,
Core Storage Team
https://blog.twitter.com/2014/manhattan-
our-real-time-multi-tenant-distributed-
database-for-twitter-scale
抄訳
import sys
import time
defmain(argv):
SLEEP_DELAY = 10
# Python ninjas - ignore this blatant bug.
for i in xrange(100):
print("Hello world! The time is now: %s. Sleeping for %d secs" % (
time.asctime(), SLEEP_DELAY))
sys.stdout.flush()
time.sleep(SLEEP_DELAY)
if __name__ == "__main__":
main(sys.argv)
hello_world.py
The Mesosphere Datacenter
OperatingSystem
「自分のデータセンターやクラウドを、Mesosphere
データセンター・オペレーティング・システムで、自動
運転させる。時間とお金を節約して、ソフトウェアはよ
り早く配布する。」
https://mesosphere.com/
179.
A New Kindof Operating
System
Mesosphere データセンター・オペレーティング・システ
ム (DCOS)は、新しい種類のオペレーティング・システム
である。それは、物理サーバー、クラウド・ベースのデータ
センターのサーバーをまたいで、その上で、あらゆるバー
ジョンのLinuxが走る。
Killer Apps User Interface Programmable
Datacenter
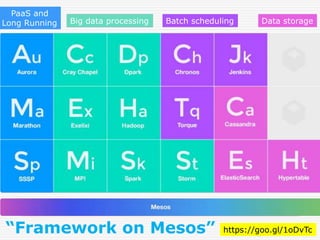
PaaS and
Long RunningBig data processing Batch scheduling Data storage
“Framework on Mesos” https://goo.gl/1oDvTc
187.
Mesos利用の拡大
-- Mesosphere Blogタイトルから --
The Mesosphere Datacenter Operating System
is now generally available
Get Mesos-DNS up and running in under 5
minutes using Docker
Building real-time data flows with Kafka on
Mesos
Cassandra on Mesos: Performance +
Reliability
Deploying Kubernetes on Mesos
It’s easier than ever to scale like Google
without being Google
https://mesosphere.com/blog/
188.
Mesos利用の拡大
-- Mesoshere Blogタイトルから --
Launching thousands of Docker containers
with DCOS on Azure
Join the DCOS public beta on Microsoft Azure
and AWS
Apple details how it rebuilt Siri on Mesos
Making Kubernetes a first-class citizen on the
DCOS
MySQL on Mesos: today’s database meets
tomorrow’s datacenter
https://mesosphere.com/blog/
189.
“Mesosphereは、Googleスケールの計算能力を万
人にもたらす。”
Abdur Chowdhury, FormerChief Scientist, Twitter
“Mesosphereは、クラウド・コンピューティングの避
けられない運命だ。”
Brad Silverberg, Fuel Capital
“Mesosphereは、開発者にとってのブレークスルー
だ。数千のDropletでさえ、一つのコンピュータのよう
に管理するその能力は、とてもエキサイティングなも
のだ。”
Ben Uretsky, CEO and Co-founder of DigitalOcean
Google, Borgの情報公開
今年の4月、Googleは、Borgの情報を初めて公開した。
“Large-scalecluster management at Google
with Borg” https://goo.gl/aN03bI
この発表に対して、Auroraのアーキテクトのコメントを含
む記事が、出ている。“Google Lifts the Veil on
Borg, Revealing Apache Aurora’s
Heritage”http://goo.gl/Nv8ZIQ
僕には謎だったBorgの名前の由来だが、それは、Star Trekに
登場する「宇宙種族のひとつ。蜂や蟻をモチーフにした社会的集
合意識を持っているとされ、中央制御装置としてのQueenがいる
」とのこと。Facebookで友人から教えてもらった。納得。
193.
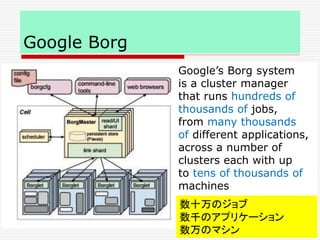
Google Borg
Google’s Borgsystem
is a cluster manager
that runs hundreds of
thousands of jobs,
from many thousands
of different applications,
across a number of
clusters each with up
to tens of thousands of
machines
数十万のジョブ
数千のアプリケーション
数万のマシン
Scheduler
offerRescinded
/**
* オファーが、もはや有効でない場合に呼び出される。
* (例えば、スレーブが失われたり、他のフレームワークがリソースを
*オファーにつかった場合とか) どんな理由であれ、オファーが撤回され
* ないならl(メッセージが落ちる、あるいは、フレームワークが失敗する等で)
* フレームワークはost or another framework used resources in the offer). If for
* 妥当ではないオファーを使ってタスクを起動しようとしたフレームワークは、
* このタスクについて、TASK_LOSTステータス更新を受け取る。
*/
def offerRescinded(
driver: SchedulerDriver,
offerId: OfferID): Unit = {
log.info("Scheduler.offerRescinded [%s]" format offerId.getValue)
}



















![Futureと関数の非同期化
f
g
入力
入力
別の処理 g
Futureが返ったら、別の
処理にただちに、制御を移す。
Futureが返る
Futureが返る
h
入力
別の処理 h
Futureが返る
Futureが返ったら、別の
処理にただちに、制御を移す。
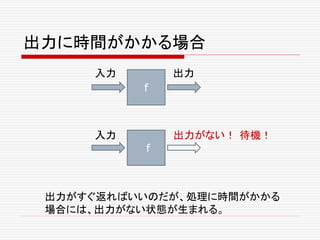
もし、関数が
Futureを返
すなら、関数
は、非同期に
できる。
非同期型
def f(x:A):Future[B]
同期型
def f(x:A):B](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-30-320.jpg)
![Futuresの値の取得 get
Futureは、ある種のコンテナーである。 trait Future[A]
それは、empty, full, failedの三つの状態を取る。我々
は、それを待つことができる。その値は getで取得できる。
val f: Future[A]
val result = f()
f.get() match {
case Return(res) => ...
case Throw(exc) => ...
}
ただ、いつ get するのか? せっかく非同期にしたのに、
get の利用は、あまり意味がない](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-31-320.jpg)
![scala> import com.twitter.util.{Future,Promise}
import com.twitter.util.{Future, Promise}
// すでに解決済みのFutureを作る。
scala> val f6 = Future.value(6)
f6: com.twitter.util.Future[Int] = com.twitter.util.ConstFuture@c63a8af
scala> f6.get()
res0: Int = 6
// 失敗となるFutureを作る
scala> val fex = Future.exception(new Exception)
fex: com.twitter.util.Future[Nothing] = com.twitter.util.ConstFuture@38dd
ab20
scala> fex.get()
java.lang.Exception
... stack trace ...
Futureのgetを実験する](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-32-320.jpg)
![// 解決されていないPromiseを作る
scala> val pr7 = new Promise[Int]
pr7: com.twitter.util.Promise[Int] = Promise@1994943491(...)
scala> pr7.get()
...console hangs, waiting for future to resolve... Ctrl-C Execution
interrupted by signal.
scala> pr7.setValue(7)
scala> pr7.get()
res1: Int = 7
scala>
Futureのgetを実験する](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-33-320.jpg)
![Futureのコールバック
「私に電話するな。私がかける。」 とMr. Futureはいう。
( Hollywood principle )
val f: Future[String]
f onSuccess {
s => log.info(s)
} onFailure {
exc => log.error(exc)
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-34-320.jpg)
![Promises
Futures はread-onlyだが (初期化の時に、一回だけ、書
かれる)、Promiseは、何回でも書き込み可能である
val p: Promise[Int]
val f: Future[Int] = p
Success:
p.setValue(1)
Failure:
p.setException(new MyExc)](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-35-320.jpg)

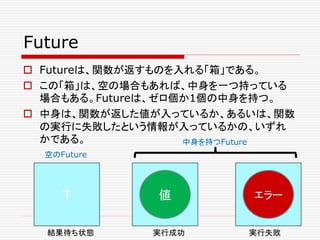
![サンプルのシナリオ
getThumbnail
ここでは、与えられたURLから Webページを取得し、つ
づいて、そのWebページの最初の画像リンクから画像を
取得する処理 getThumbnail を考えてみよう。
基本的なデータ型として、Webpageを次のように定義し
よう。要は、Webページは、画像リンク(imagelinks)とリ
ンク(links)からなり、それぞれは、文字列(URL)の
Sequence(リストと思っていい)だということ。
trait Webpage {
def imageLinks: Seq[String]
def links: Seq[String] ...
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-37-320.jpg)

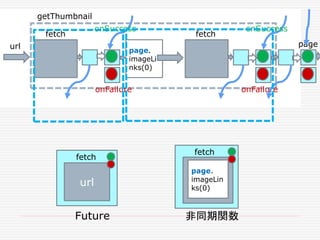
![非同期型のシナリオ
getThumbnail
Futureを使った同期型では、こんな感じになる。中間の
部分の処理は、大して時間かからなそうなので、内部に組
み込んだ。
def fetch(url: String):Future[Webpage]
def getThumbnailSync(url:String):Future[Webpage]
page.
imageLi
nks(0)
fetch fetch
url
getThumbnail
page
onSuccess onSuccess
onFailure onFailure](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-39-320.jpg)
![非同期型のシナリオ
getThumbnail のコード
def getThumbnail(url: String): Future[Webpage] = {
val promise = new Promise[Webpage]
fetch(url) onSuccess { page =>
fetch(page.imageLinks(0)) onSuccess { p =>
promise.setValue(p)
} onFailure { exc =>
promise.setException(exc)
}
} onFailure { exc =>
promise.setException(exc)
}
promise
}
これは、よくあるCallback Hellのパターンだ。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-40-320.jpg)
![getThumbnailをflatMapで実装
def getThumbnail(url: String): Future[Webpage] =
fetch(url) flatMap {
page => fetch(page.imageLinks(0))
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-41-320.jpg)

![回り道
CollectionのflatMap
flatMapコンビネーターは、非常に汎用的なツールである。
trait Seq[A] {
def flatMap[B](f: A => Seq[B]): Seq[B] ...
その名前が示唆する様に、それは、mapとflattenの組み合
わせである。
def flatMap[B](f: A => Seq[B]) = map(f).flatten](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-43-320.jpg)
![flatMapで、何ができるか?
拡張:
Seq(1,2,3,4) flatMap { x => Seq(x, -x)}
== Seq(Seq(1,-1)),Seq(2,-2),Seq(3,-3),Seq(4,-4).flatten
== Seq(1,-1,2,-2,3,-3,4,-4)
条件:
Seq(1,2,3,4) flatMap { x =>
if (x%2 == 0) Seq(x)
else Seq()
}
== Seq(Seq(2),Seq(4)).flatten
== Seq(2,4)
Seq[Seq[int]]を、Seq[int]に変える](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-44-320.jpg)
![FutureのflatMap
trait Future[A] {
def flatMap[B](f: A => Future[B]): Future[B] ...
Future[Future[T]]を、Future[T]に変える](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-45-320.jpg)
![flatMapが助けになる?
我々は、次のような関数を定義しようとしている。
def getThumbnail(url: String): Future[Webpage]
最初にページを取り込んで、最初のイメージのリンクを見つけ、
そのリンクからイメージを取り込む。
この操作のいずれかが失敗すれば、このgetThumbnailも失
敗する。
trait Future[A] {
... def flatMap[B](f: A => Future[B]): Future[B]](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-46-320.jpg)
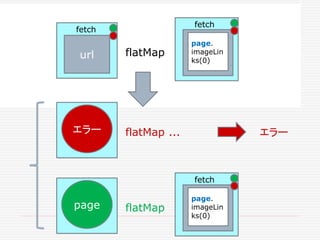
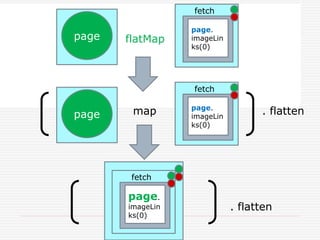
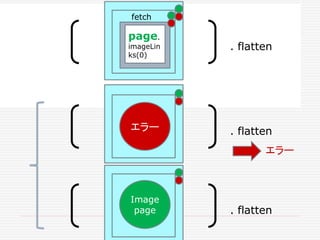
![. flatten
Image
page
Image
page
Future flatmap 非同期関数
で、新しいFutureが返る
flatMapで、Future[Future[T]]
が、Future[T]に変わる](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-51-320.jpg)
![getThumbnailをflatMapで実装
def getThumbnail(url: String): Future[Webpage] =
fetch(url) flatMap {
page => fetch(page.imageLinks(0))
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-52-320.jpg)
![失敗はどうなるのか?
これらは、合成も上手く行く。また、それは、回復可能でなければな
らない。flatMap には、その双対が必要である。flatMapは、成功
した値の上に働き、rescueは、例外を処理する。
trait Future[A] {
...
def rescue[B](f: Exception => Future[B]): Future[B]
エラーの回復は、次のようになる
val f = fetch(url) rescue {
case ConnectionFailed => ....
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-53-320.jpg)


![flatMapの利用 もう一つの例
例えば、Future[User]があったとしよう。そして、特定の
ユーザーが失格になっていることを示す
Future[Boolean]が必要だとしよう。あるユーザーが失
格になっているかどうかを決めるisBanned APIがある。
ただ、これは非同期APIなので、flatMapを利用すること
ができる。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-56-320.jpg)
![scala> import com.twitter.util.{Future,Promise}
import com.twitter.util.{Future, Promise}
scala> class User(n: String) { val name = n }
defined class User
scala> def isBanned(u: User) = { Future.value(false) }
isBanned: (u: User)com.twitter.util.Future[Boolean]
scala> val pru = new Promise[User]
pru: com.twitter.util.Promise[User] = Promise@897588993(...)
// apply isBanned to future
scala> val futBan = pru flatMap isBanned
futBan: com.twitter.util.Future[Boolean] = Promise@1733189548(...)
scala> futBan.get()
...REPL hangs, futBan not resolved yet... Ctrl-C Execution interrupted
by signal.
scala> pru.setValue(new User("prudence"))
scala> futBan.get()
res45: Boolean = false
scala>](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-57-320.jpg)


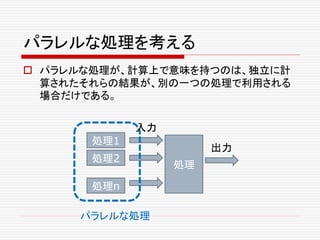
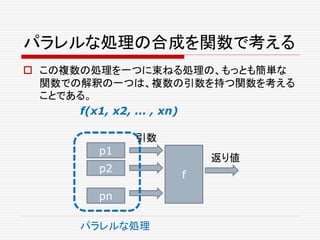

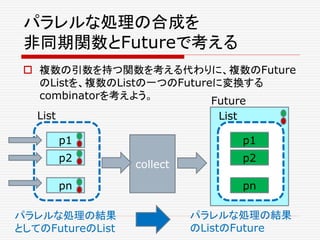
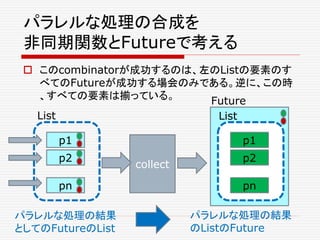
:
Future[Seq[A]]
def join(fs: Seq[Future[_]]):
Future[Unit]
def select(fs: Seq[Future[A]]) :
Future[(Try[A], Seq[Future[A]])]
}
パラレルな処理の合成](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-65-320.jpg)
![先の、ページから最初の画像ページを取り出すプログラムを、少
し修正して、あるページの全ての画像ページを取り出すプログラ
ムを作ることができる。
def getThumbnails(url: String):
Future[Seq[Webpage]] =
fetch(url) flatMap { page =>
Future.collect(
page.imageLinks map { u => fetch(u) }
)
}
ページから、すべての画像
ページを取り出すプログラム
a1
a2
・
・
an
a1
a2
・
・
an
collect
fan-out](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-66-320.jpg)
![単純な Web Crawler
def crawl(url: String): Future[Seq[Webpage]] =
fetch(url) flatMap { page =>
Future.collect(
page.links map { u => crawl(u) }
) map { pps => pps.flatten }
}
(* Apocryphal ほんとかな?)](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-67-320.jpg)

![Services
futureが、いかに並行プラグラミングに利用できるかを見てき
た。ここでは、ネットワーク・プログラミングが、いかに、この図式
に当てはまるかを見ることにしよう。
RPCは、どうだろうか?
リクエストを送る
しばらく待つ
成功か、失敗か
これは、関数である。
type Service[Req, Rep] = Req => Future[Rep]](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-69-320.jpg)

![Server
同様に Finagle serverはServiceをネットワークに
“exports”する。serverは、二つの部分を持つ。
1. Serviceを実装した関数:Reqを受け取り、Future[Rep]
を返す。
2. 入ってくるReqをどう“listen”するかの設定。例えば、
HTTPのリクエストを、80番ポートで待つ等。
こうして、Serviceのロジックと、ネットワーク上どのようにデー
タが流れるかの設定は、分離される。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-71-320.jpg)
![Client
Finaglのclientは、ネットワークからServiceを “imports”
する。概念的には、Finagle clientは、二つの部分からなる。
1. Serviceを利用する関数: リクエスト Req を送り、帰って
来たFuture[Rep]を処理する。
2. リクエストをどう送るかの設定。例えば、次のような設定
api.twitter.comのポート80に、HTTPで送る。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-72-320.jpg)

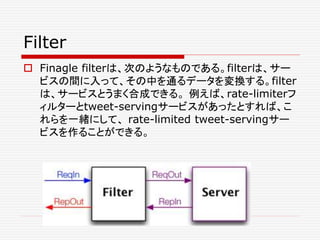
![Filterは、serviceを変形する。 それらは、service generic な機能
を提供できる。例えば、rate-limitingをサポートすべき複数のサー
ビスがあったとする。一つのrate-limitingフィルターを書けば、それ
をすべてのサービスに適用できる。Filterは、また、サービスを異なっ
たフェーズに分解するのにいい働きをする。
単純なproxyは、次のような形をしているだろう。ここで、
rewriteReq と rewriteRes は、プロトコルの変換を提供する。
class MyService(client: Service[..]) extends
Service[HttpRequest, HttpResponse] {
def apply(request: HttpRequest) = {
client(rewriteReq(request)) map { res =>
rewriteRes(res)
}
}
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-75-320.jpg)

![Filterは、積み重ねられる。
val timeout: Filter[…]
val auth: Filter[…]
val service: Service[…]
timeout andThen auth andThen service
def andThen[A](g: (R) ⇒ A): (T1) ⇒ A
Composes two instances of Function1 in a new
Function1, with this function applied first.
def compose[A](g: (A) ⇒ T1): (A) ⇒ R
Composes two instances of Function1 in a new
Function1, with this function applied last.](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-77-320.jpg)


![Clients
val client = ClientBuilder()
.name("loadtest")
.codec(Http)
.hosts("google.com:80,..")
.build()
client は、 Service[HttpReq, HttpRep] である。
client(HttpRequest(GET, "/"))](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-80-320.jpg)

![それらをまとめると
新しい処理を追加したくなったとしよう。それは簡単である。
val backupReq: Filter[…] = { (req, service) =>
val reqs = Seq(
service(req),
timer.doLater(delay) { service(req)).flatten }
)
Future.select(reqs) flatMap {
case (Return(res), Seq(other)) =>
other.cancel()
Future.value(res)
case (Throw(_), Seq(other)) => other
}
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-82-320.jpg)
![[昔話]
SOAとRPCを振り返る
SOA「サービス指向アーキテクチャー」やRPCやモジ
ュラーなコンポーネントの歴史は古い。ここでは、
2002年に筆者が行った講演の一部を紹介する。「サ
ービス」概念の抽象化と実装の変化を振り返るのは、
興味深い。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-83-320.jpg)






















































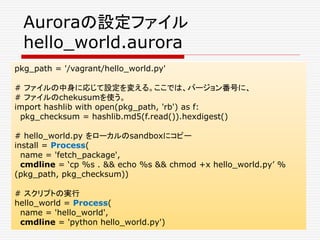
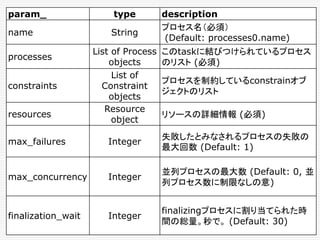
![# taskの記述
# installとhello_worldをシーケンシャルに実行する。
hello_world_task = SequentialTask(
processes = [install, hello_world],
resources = Resources (cpu = 1, ram = 1*MB, disk=8*MB))
# jobの記述
jobs = [
Service (
cluster = 'devcluster',
environment = 'devel',
role = 'www-data',
name = 'hello_world',
task = hello_world_task
)
]
Auroraの設定ファイル
hello_world.aurora (続き)](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-151-320.jpg)

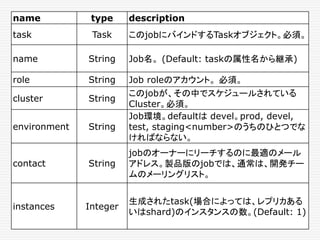
![Auroraの設定ファイルがしていること
最後に、Jobの定義。Jobは、利用可能なマシン上に
Taskをスケジュールする。この例では、JobはJobリスト
の唯一のメンバーだが、configファイルでは、一つ以上の
Jobを指定できる。
jobs = [
Service(
cluster = ‘devcluster’,
environment = ‘devel’,
role = ‘www-data’,
name = ‘hello_world’,
task = hello_world_task
)
]](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-153-320.jpg)
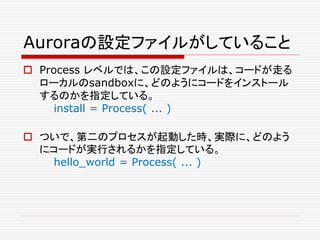

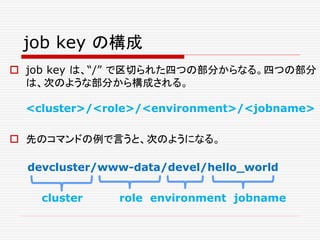

![clusterの定義
このjob keyの指定は、よく見ると、この例では、
*.aurora のAurora設定ファイルが、
jobs = [
Service( ... )
...
]
の中で、Serviceのパラメータに設定されたものと重複し
ている。(jobをTaskに結びつける、task = ... というパ
ラメータを除いては)
それぞれのパラメーターの説明は、これから、おいおいす
ることにして、まず、先頭のclusterは、どのように定義さ
れているのだろうか?](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-158-320.jpg)
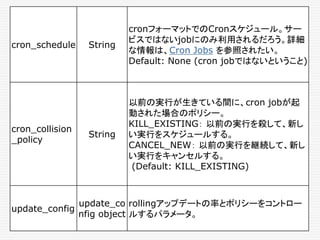
![clusterの設定
/etc/aurora/clusters.json
clusterの設定は、/etc/aurora/clusters.json というファ
イルの中で行われている。こんな中身だ。
[{ “name”: “devcluster”,
“zk”: “192.168.33.7”,
“scheduler_zk_path”: “/aurora/scheduler”,
“auth_mechanism”: “UNAUTHENTICATED”
}]](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-159-320.jpg)


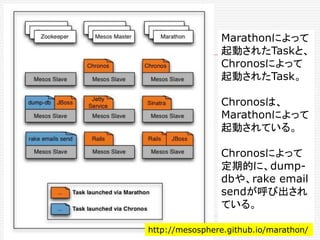
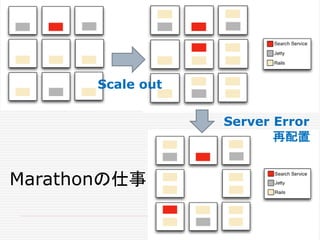

























![[余談]
大規模分散システムのパワーを、
誰が、どのように利用するのか?
21世紀初頭のGoogleの登場は、大規模分散システ
ムが、そのパワーを現した画期だった。あれから、もう
15年がたつ。ただ、その当時には、Googleだけしか
それができなかった。大規模分散システムのパワーを
、誰が、どのように利用するのかについて、次の変化
が起きつつあるように見える。](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-190-320.jpg)





![$ vagrant ssh
Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-23-generic
x86_64)
Documentation: https://help.ubuntu.com/ Welcome to your Vagrant-
built virtual machine.
Last login: Fri Jan 3 02:18:55 2014 from 10.0.2.2
vagrant@precise64:~$ aurora job create devcluster/www-
data/devel/hello_world /vagrant/hello_world.aurora
INFO] Creating job hello_world
INFO] Response from scheduler: OK (message: 1 new tasks pending
for job www-data/devel/hello_world)
INFO] Job url: http://precise64:8081/scheduler/www-
data/devel/hello_world
...
...
実行結果](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-198-320.jpg)
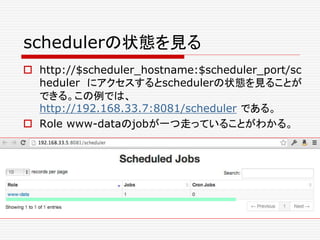
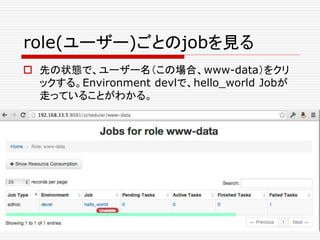
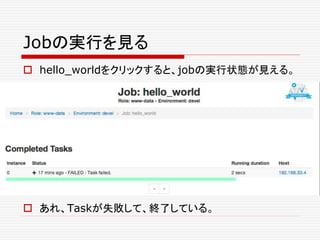
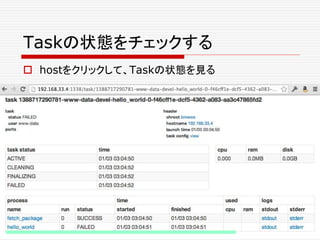
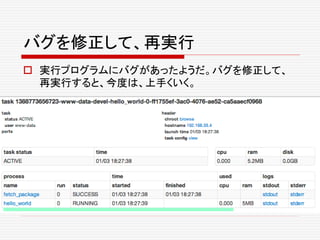
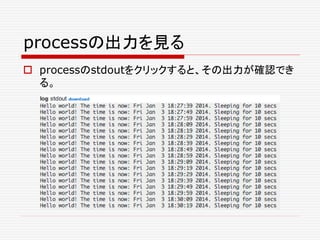
![jobを殺す
aurora job killall ...
次のようにして、投入したjobを殺せる。
vagrant@precise64:~$ aurora job killall
devcluster/www-data/devel/hello_world
INFO] Killing tasks for job: devcluster/www-
data/devel/hello_world
INFO] Response from scheduler: OK (message:
Tasks killed.)
INFO] Job url:
http://precise64:8081/scheduler/www-
data/devel/hello_world
vagrant@precise64:~$](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-205-320.jpg)
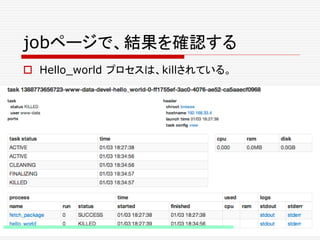


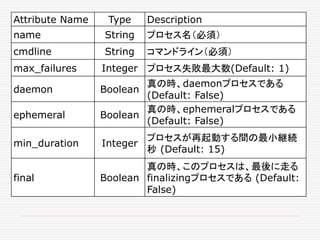



![FrameworkInfo
https://github.com/apache/mesos/blob/master/include/mes
os/mesos.proto
message FrameworkInfo {
required string user = 1;
required string name = 2;
optional FrameworkID id = 3;
optional double failover_timeout = 4 [default = 0.0];
optional bool checkpoint = 5 [default = false];
optional string role = 6 [default = "*"];
optional string hostname = 7;
optional string principal = 8;
optional string webui_url = 9;
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-218-320.jpg)




![Scheduler
resourceOffers
(あるいは、フレームワークが、すでにこれらのリソース
を使ってタスクを起動していたとすれば、これらのタス
クは、TASK_LOSTの状態で失敗するだろう。メッセー
ジを見て欲しい)
def resourceOffers(
driver: SchedulerDriver, offers: JList[Offer]): Unit = {
log.info("Scheduler.resourceOffers")
// print and decline all received offers
offers foreach { offer =>
log.info(offer.toString)
driver declineOffer offer.getId
}
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-224-320.jpg)
![Scheduler
offerRescinded
/**
* オファーが、もはや有効でない場合に呼び出される。
* (例えば、スレーブが失われたり、他のフレームワークがリソースを
* オファーにつかった場合とか) どんな理由であれ、オファーが撤回され
* ないならl(メッセージが落ちる、あるいは、フレームワークが失敗する等で)
* フレームワークはost or another framework used resources in the offer). If for
* 妥当ではないオファーを使ってタスクを起動しようとしたフレームワークは、
* このタスクについて、TASK_LOSTステータス更新を受け取る。
*/
def offerRescinded(
driver: SchedulerDriver,
offerId: OfferID): Unit = {
log.info("Scheduler.offerRescinded [%s]" format offerId.getValue)
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-225-320.jpg)

![Scheduler
frameworkMessage
/**
* executorが、メッセージを送った時に呼び出される。これらの
* メッセージは、best effortである。フレームワークが、なんらかの
* 信頼できるやり方で、メッセージを再送信するのを期待しないこと
*/
def frameworkMessage(
driver: SchedulerDriver,
executorId: ExecutorID,
slaveId: SlaveID,
data: Array[Byte]): Unit = {
log.info("Scheduler.frameworkMessage")
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-227-320.jpg)

![Scheduler
slaveLost
/**
* スレーブがunreachableになった時呼び出される。
* (マシンの失敗、ネットワークの分断等)ほとんどのフレームワーク
* は、このスレーブで起動されたタスクは、他のスレーブに
* リスケジュールされる必要がある。
*/
def slaveLost(
driver: SchedulerDriver,
slaveId: SlaveID): Unit = {
log.info("Scheduler.slaveLost: [%s]" format slaveId.getValue)
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-229-320.jpg)
![Scheduler
executorLost
/**
* executorが、exited/terminated になった時に呼び出される。
* 実行中のすべてのタスクは、TASK_LOSTのステータスになり、
* 自動的に(魔法のように)更新される。
*/
def executorLost(
driver: SchedulerDriver,executorId: ExecutorID, slaveId: SlaveID,
status: Int): Unit = {
log.info("Scheduler.executorLost: [%s]" format executorId.getValue)
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-230-320.jpg)
![Scheduler
error
/**
* schedulerあるいはそのドライバーに、修復不可能なエラーが
* 起きた時に呼び出される。ドライバーは、これが呼び出される以前に
* 中止する。
*/
def error(driver: SchedulerDriver, message: String): Unit = {
log.info("Scheduler.error: [%s]" format message)
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-231-320.jpg)




![Executor
frameworkMessage
/**
* このexecutorに、フレームワークのメッセージが届いた時に
* 呼び出される。これらのメッセージは best effort である。これらが、
* なんらかの信頼できるスタイルで再送信されることを期待しないこと
*/
def frameworkMessage(driver: ExecutorDriver, data: Array[Byte]): Unit = {
log.info("Executor.frameworkMessage")
}](https://image.slidesharecdn.com/twitter-150622231612-lva1-app6891/85/Twitter-236-320.jpg)


























































![[Basic 9] 並列処理 / 排他制御](https://cdn.slidesharecdn.com/ss_thumbnails/basic-091-180306131603-thumbnail.jpg?width=640&height=640&fit=bounds)
































