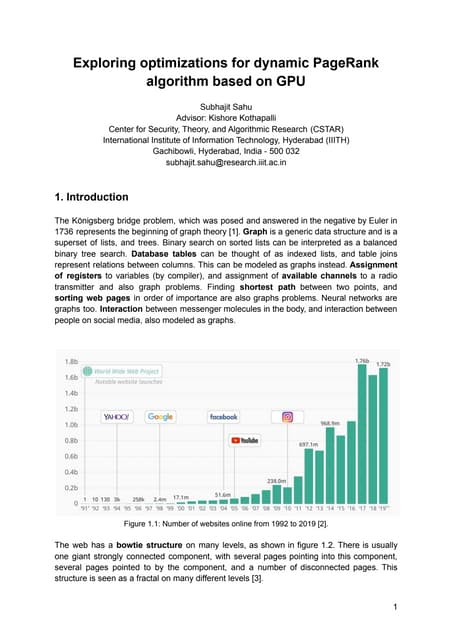
This document summarizes a project on implementing and evaluating parallel algorithms for connected components labeling on graphs using CPU (OpenMP) and GPU (CUDA). It studied different graph types and architectures. It proposed a simple autotuning approach to choose the best technique for a given graph by characterizing graphs based on features and employing the best algorithm. It discussed motivations, definitions, basic algorithms, optimizations, experiments on datasets, and future work including more sophisticated autotuning and heterogeneous algorithms.