Download as PDF, PPTX











![Customers trust Confluent to connect to IBM
Mainframes
17
Saved on costs, stayed
compliant and reimagined
customer experiences
“… rescue data off of the
mainframe, … saving RBC fixed
infrastructure costs (OPEX). RBC
stayed compliant with bank
regulations and business logic,
and is now able to create new
applications using the same
event-based architecture.”
Case study
Reduced demand on
mainframes and accelerated
the delivery of new
solutions
“… our mainframe systems
represent a significant
component of our budget... The
UDP platform [built with Confluent]
enabled us to lower costs by
offloading work to the forward
cache and reducing demand on
our mainframe systems.”
Case study
Built a foundation for
next-gen applications to
drive digital
transformation
“… plays a critical role to
transform from monolithic,
mainframe-based ecosystem to
microservices based ecosystem
and enables a low-latency data
pipeline to drive digital
transformation.”
Online webinar](https://image.slidesharecdn.com/confluentpartnertechtalkwithsva-230607103813-c3a2a28d/85/Confluent-Partner-Tech-Talk-with-SVA-17-320.jpg)









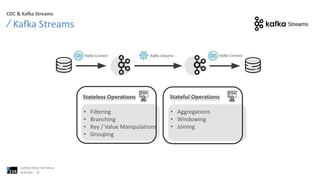


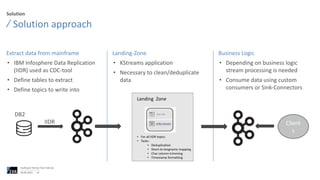







The document discusses best practices for debugging client applications, specifically in the context of Confluent offerings and mainframe data management. It highlights the challenges associated with mainframes, such as high costs and complex business logic, and outlines solutions for real-time data access and processing using Confluent's Kafka Streams and change data capture (CDC) technologies. The content emphasizes the benefits of integrating mainframe data into modern applications to enhance efficiency and facilitate digital transformation.























































































