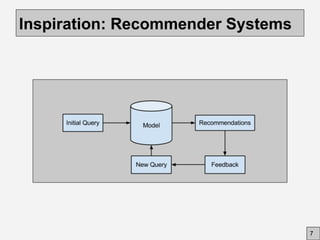
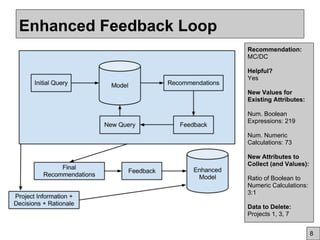
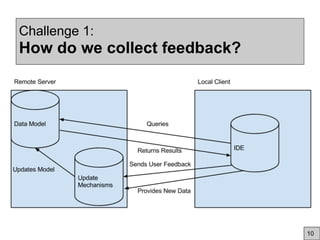
This document discusses using community feedback to improve software engineering data quality over time. It proposes using a dynamic data model where human feedback enhances static data sets, similar to how Wikipedia evolves. Key challenges are how to collect feedback, integrate it with AI, and motivate user participation through incentives, usability and trust. The goal is to lower costs while building a stronger evidence base that adapts to changing conditions through a synergistic human-AI approach.