
Recommended
More Related Content
Similar to Commputer organization and assembly .ppt
Similar to Commputer organization and assembly .ppt (20)
Recently uploaded
Recently uploaded (20)
Commputer organization and assembly .ppt
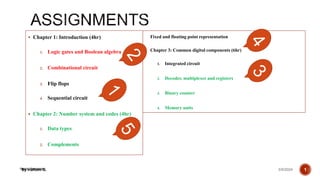
- 1. Henry Hexmoor Chapter 1: Introduction (4hr) 1. Logic gates and Boolean algebra 2. Combinational circuit 3. Flip flops 4. Sequential circuit Chapter 2: Number system and codes (4hr) 1. Data types 2. Complements 3/9/2024 By Haftom B. 1 Fixed and floating point representation Chapter 3: Common digital components (6hr) 1. Integrated circuit 2. Decoder, multiplexer and registers 3. Binary counter 4. Memory units
- 2. REGISTER TRANSFER AND MICROOPERATIONS 2 3/9/2024 By Haftom B.
- 3. CONTENTS Register Transfer Bus and Memory Transfers Arithmetic Microoperations Logic Microoperations Shift Microoperations Arithmetic Logic Shift Unit 3 3/9/2024 By Haftom B.
- 4. SIMPLE DIGITAL SYSTEMS Combinational and sequential circuits can be used to create simple digital systems. These are the low-level building blocks of a digital computer. Simple digital systems are frequently characterized in terms of the registers they contain, and the operations that they perform. Typically, What operations are performed on the data in the registers What information is passed between registers 4 3/9/2024 By Haftom B.
- 5. MICROOPERATIONS (1) The operations on the data in registers are called microoperations. The functions built into registers are examples of microoperations Shift Load Clear Increment … Register Transfer Language 5 3/9/2024 By Haftom B.
- 6. MICROOPERATION • An elementary operation performed (during one clock pulse), on the information stored in one or more registers. R f(R, R) f: shift, load, clear, increment, add, subtract, complement, and, or, xor, … ALU (f) Registers (R) 1 clock cycle Register Transfer Language 6 3/9/2024 By Haftom B.
- 7. ORGANIZATION OF A DIGITAL SYSTEM • Set of registers and their functions • Microoperations set : Set of allowable microoperations provided by the organization of the computer • Control signals that initiate the sequence of microoperations (to perform the functions) Definition of the (internal) organization of a computer Register Transfer Language 7 3/9/2024 By Haftom B.
- 8. REGISTER TRANSFER LEVEL(RTL) Viewing a computer, or any digital system, in this way is called the register transfer level RTL is used to describe CPU organization in high-level form. This is because we’re focusing on The system’s registers The data transformations in them, and The data transfers between them. Register Transfer Language 8 3/9/2024 By Haftom B.
- 9. REGISTER TRANSFER LANGUAGE Rather than specifying a digital system in words, a specific notation is used, register transfer language For any function of the computer, the register transfer language can be used to describe the (sequence of) microoperations RTL is used to express how the computer works Register transfer language A symbolic language not executed by computer A convenient tool for describing the internal organization of digital computers Can also be used to facilitate the design process of digital systems. Register Transfer Language 9 3/9/2024 By Haftom B.
- 10. DESIGNATION OF REGISTERS Registers are designated by capital letters, sometimes followed by numbers (e.g., A, R13, IR) Often the names indicate function: MAR - memory address register PC- program counter IR - instruction register Registers and their contents can be viewed and represented in various ways A register can be viewed as a single entity: Registers may also be represented showing the bits of data they contain. Register Transfer Language MAR 10 3/9/2024 By Haftom B.
- 11. DESIGNATION OF REGISTERS Register Transfer Language R1 Register Numbering of bits Showing individual bits Subfields PC(H) PC(L) 15 8 7 0 - a register - portion of a register - a bit of a register • Common ways of drawing the block diagram of a register •The clock is not included as a variable in RTL 7 6 5 4 3 2 1 0 R2 15 0 • Designation of a register 11 3/9/2024 By Haftom B.
- 12. REGISTER TRANSFER Copying the contents of one register to another is a register transfer A register transfer is indicated as R2 R1 In this case the contents of register R1 are copied (loaded) into register R2 A simultaneous transfer of all bits from the source R1 to the destination register R2, during one clock pulse Note that this is a non-destructive; i.e. the contents of R1 are not altered by copying (loading) them to R2 Register Transfer 12 3/9/2024 By Haftom B.
- 13. REGISTER TRANSFER A register transfer such as R3 R5 Implies that the digital system has the data lines from the source register (R5) to the destination register (R3) Parallel load in the destination register (R3) Control lines to perform the action Register Transfer 13 3/9/2024 By Haftom B.
- 14. CONTROL FUNCTIONS Often actions need to only occur if a certain condition is true This is similar to an “if” statement in a programming language In digital systems, this is often done via a control signal, called a control function If the signal is 1, the action takes place This is represented as: P: R2 R1 Which means “if P = 1, then load the contents of register R1 into register R2”, i.e., if (P = 1) then (R2 R1) Register Transfer 14 3/9/2024 By Haftom B.
- 15. HARDWARE IMPLEMENTATION OF CONTROLLED TRANSFERS Implementation of controlled transfer P: R2 R1 Block diagram Timing diagram Clock Register Transfer Transfer occurs here R2 R1 Control Circuit Load P n Clock Load t t+1 • The same clock controls the circuits that generate the control function and the destination register • Registers are assumed to use positive-edge-triggered flip-flops 15 3/9/2024 By Haftom B.
- 16. SIMULTANEOUS OPERATIONS If two or more operations are to occur simultaneously, they are separated with commas P: R3 R5, MAR IR Here, if the control function P = 1, load the contents of R5 into R3, and at the same time (clock), load the contents of register IR into register MAR Register Transfer 16 3/9/2024 By Haftom B.
- 17. BASIC SYMBOLS FOR REGISTER TRANSFERS Capital letters Denotes a register MAR, R2 & numerals Parentheses () Denotes a part of a register R2(0-7), R2(L) Arrow Denotes transfer of information R2 R1 Colon : Denotes termination of control function P: Comma , Separates two micro-operations A B, B A Symbols Description Examples Register Transfer 17 3/9/2024 By Haftom B.
- 18. CONNECTING REGISTRS In a digital system with many registers, it is impractical to have data and control lines to directly allow each register to be loaded with the contents of every possible other registers To completely connect n registers n(n-1) lines O(n2) cost This is not a realistic approach to use in a large digital system Instead, take a different approach Have one centralized set of circuits for data transfer – the bus Have control circuits to select which register is the source, and which is the destination Register Transfer 18 3/9/2024 By Haftom B.
- 19. BUS AND BUS TRANSFER • Bus is a path(of a group of wires) over which information is transferred, from any of several sources to any of several destinations. From a register to bus: BUS R 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 Register A Register B Register C Register D B C D 1 1 1 4 x1 MUX B C D 2 2 2 4 x1 MUX B C D 3 3 3 4 x1 MUX B C D 4 4 4 4 x1 MUX 4-line bus x y select 0 0 0 0 Register A Register B Register C Register D Bus lines Bus and Memory Transfers 19 3/9/2024 By Haftom B.
- 20. TRANSFER FROM BUS TO A DESTINATION REGISTER Three-State Bus Buffers Bus line with three-state buffers Reg. R0 Reg. R1 Reg. R2 Reg. R3 Bus lines 2 x 4 Decoder Load D0 D1 D2 D3 z w Select E (enable) Output Y=A if C=1 High-impedence if C=0 Normal input A Control input C Select Enable 0 1 2 3 S0 S1 A0 B0 C0 D0 Bus line for bit 0 Bus and Memory Transfers 20 3/9/2024 By Haftom B.
- 21. BUS TRANSFER IN RTL Depending on whether the bus is to be mentioned explicitly or not, register transfer can be indicated as either or In the former case the bus is implicit, but in the latter, it is explicitly indicated Bus and Memory Transfers R2 R1 BUS R1, R2 BUS 21 3/9/2024 By Haftom B.
- 22. MEMORY RAM Memory (RAM) can be thought as a sequential circuits containing some number of registers These registers hold the words of memory Each of the r registers is indicated by an address These addresses range from 0 to r-1 Each register (word) can hold n bits of data Assume the RAM contains r = 2k words. It needs the following n data input lines n data output lines k address lines A Read control line A Write control line Bus and Memory Transfers data input lines data output lines n n k address lines Read Write RAM unit 22 3/9/2024 By Haftom B.
- 23. MEMORY TRANSFER Collectively, the memory is viewed at the register level as a device, M. Since it contains multiple locations, we must specify which address in memory we will be using This is done by indexing memory references Memory is usually accessed in computer systems by putting the desired address in a special register, the Memory Address Register (MAR, or AR) When memory is accessed, the contents of the MAR get sent to the memory unit’s address lines Bus and Memory Transfers AR Memory unit Read Write Data in Data out M 23 3/9/2024 By Haftom B.
- 24. MEMORY READ To read a value from a location in memory and load it into a register, the register transfer language notation looks like this: This causes the following to occur The contents of the MAR get sent to the memory address lines A Read (= 1) gets sent to the memory unit The contents of the specified address are put on the memory’s output data lines These get sent over the bus to be loaded into register R1 Bus and Memory Transfers R1 M[MAR] 24 3/9/2024 By Haftom B.
- 25. MEMORY WRITE To write a value from a register to a location in memory looks like this in register transfer language: This causes the following to occur The contents of the MAR get sent to the memory address lines A Write (= 1) gets sent to the memory unit The values in register R1 get sent over the bus to the data input lines of the memory The values get loaded into the specified address in the memory Bus and Memory Transfers M[MAR] R1 25 3/9/2024 By Haftom B.
- 26. SUMMARY OF R. TRANSFER MICROOPERATIONS Bus and Memory Transfers A B Transfer content of reg. B into reg. A AR DR(AD) Transfer content of AD portion of reg. DR into reg. AR A constant Transfer a binary constant into reg. A ABUS R1, Transfer content of R1 into bus A and, at the same time, R2 ABUS transfer content of bus A into R2 AR Address register DR Data register M[R] Memory word specified by reg. R M Equivalent to M[AR] DR M Memory read operation: transfers content of memory word specified by AR into DR M DR Memory write operation: transfers content of DR into memory word specified by AR 26 3/9/2024 By Haftom B.
- 27. MICROOPERATIONS • Computer system microoperations are of four types: 1. Register transfer microoperations Already Discussed 2. Arithmetic microoperations 3. Logic microoperations 4. Shift microoperations Arithmetic Microoperations 27 3/9/2024 By Haftom B.
- 28. ARITHMETIC MICROOPERATIONS The basic arithmetic microoperations are Addition Subtraction Increment Decrement The additional arithmetic microoperations are Add with carry Subtract with borrow Transfer/Load etc. … Arithmetic Microoperations 28 3/9/2024 By Haftom B.
- 29. Henry Hexmoor SUMMARY OF TYPICAL ARITHMETIC MICRO-OPERATIONS R3 R1 + R2 Contents of R1 plus R2 transferred to R3 R3 R1 - R2 Contents of R1 minus R2 transferred to R3 R2 R2’ Complement the contents of R2 R2 R2’+ 1 2's complement the contents of R2 (negate) R3 R1 + R2’+ 1 subtraction R1 R1 + 1 Increment R1 R1 - 1 Decrement 29 3/9/2024 By Haftom B.
- 30. FA B0 A0 S0 C0 FA B1 A1 S1 C1 FA B2 A2 S2 C2 FA B3 A3 S3 C3 C4 Binary Adder-Subtractor FA B0 A0 S0 C0 C1 FA B1 A1 S1 C2 FA B2 A2 S2 C3 FA B3 A3 S3 C4 M Binary Incrementer HA x y C S A0 1 S0 HA x y C S A1 S1 HA x y C S A2 S2 HA x y C S A3 S3 C4 Binary Adder Arithmetic Microoperations 30 3/9/2024 By Haftom B.
- 31. S1 S0 0 1 2 3 4x1 MUX X0 Y0 C0 C1 D0 FA S1 S0 0 1 2 3 4x1 MUX X1 Y1 C1 C2 D1 FA S1 S0 0 1 2 3 4x1 MUX X2 Y2 C2 C3 D2 FA S1 S0 0 1 2 3 4x1 MUX X3 Y3 C3 C4 D3 FA Cout A0 B0 A1 B1 A2 B2 A3 B3 0 1 S0 S1 Cin S1 S0 Cin Y Output Microoperation 0 0 0 B D = A + B Add 0 0 1 B D = A + B + 1 Add with carry 0 1 0 B’ D = A + B’ Subtract with borrow 0 1 1 B’ D = A + B’+ 1 Subtract 1 0 0 0 D = A Transfer A 1 0 1 0 D = A + 1 Increment A 1 1 0 1 D = A - 1 Decrement A 1 1 1 1 D = A Transfer A Arithmetic Microoperations 31 3/9/2024 By Haftom B.
- 32. LOGIC MICROOPERATIONS Specify binary operations on the strings of bits in registers Logic microoperations are bit-wise operations, i.e., they work on the individual bits of data useful for bit manipulations on binary data useful for making logical decisions based on the bit value There are, in principle, 16 different logic functions that can be defined over two binary input variables However, most systems only implement four of these AND (), OR (), XOR (), Complement/NOT The others can be created from combination of these Logic Microoperations 0 0 0 0 0 … 1 1 1 0 1 0 0 0 … 1 1 1 1 0 0 0 1 … 0 1 1 1 1 0 1 0 … 1 0 1 A B F0 F1 F2 … F13 F14 F15 32 3/9/2024 By Haftom B.
- 33. LIST OF LOGIC MICROOPERATIONS • List of Logic Microoperations - 16 different logic operations with 2 binary vars. - n binary vars → functions 2 2 n • Truth tables for 16 functions of 2 variables and the corresponding 16 logic micro- operations Boolean Function Micro- Operations Name x 0 0 1 1 y 0 1 0 1 Logic Microoperations 0 0 0 0 F0 = 0 F 0 Clear 0 0 0 1 F1 = xy F A B AND 0 0 1 0 F2 = xy' F A B’ 0 0 1 1 F3 = x F A Transfer A 0 1 0 0 F4 = x'y F A’ B 0 1 0 1 F5 = y F B Transfer B 0 1 1 0 F6 = x y F A B Exclusive-OR 0 1 1 1 F7 = x + y F A B OR 1 0 0 0 F8 = (x + y)' F A B)’ NOR 1 0 0 1 F9 = (x y)' F (A B)’ Exclusive-NOR 1 0 1 0 F10 = y' F B’ Complement B 1 0 1 1 F11 = x + y' F A B 1 1 0 0 F12 = x' F A’ Complement A 1 1 0 1 F13 = x' + y F A’ B 1 1 1 0 F14 = (xy)' F (A B)’ NAND 1 1 1 1 F15 = 1 F all 1's Set to all 1's 33 3/9/2024 By Haftom B.
- 34. HARDWARE IMPLEMENTATION OF LOGIC MICROOPERATIONS 0 0 F = A B AND 0 1 F = AB OR 1 0 F = A B XOR 1 1 F = A’ Complement S1 S0 Output -operation Function table Logic Microoperations B A S S F 1 0 i i i 0 1 2 3 4 X 1 MUX Select 34 3/9/2024 By Haftom B.
- 35. APPLICATIONS OF LOGIC MICROOPERATIONS Logic microoperations can be used to manipulate individual bits or a portions of a word in a register Consider the data in a register A. In another register, B, is bit data that will be used to modify the contents of A Selective-set A A + B Selective-complement A A B Selective-clear A A • B’ Mask (Delete) A A • B Clear A A B Insert A (A • B) + C Etc.….. Logic Microoperations 35 3/9/2024 By Haftom B.
- 36. SELECTIVE SET In a selective set operation, the bit pattern in B is used to set certain bits in A 1 1 0 0 At 1 0 1 0 B 1 1 1 0 At+1 (A A + B) If a bit in B is set to 1, that same position in A gets set to 1, otherwise that bit in A keeps its previous value Logic Microoperations 36 3/9/2024 By Haftom B.
- 37. SELECTIVE COMPLEMENT In a selective complement operation, the bit pattern in B is used to complement certain bits in A 1 1 0 0 At 1 0 1 0 B 0 1 1 0 At+1 (A A B) If a bit in B is set to 1, that same position in A gets complemented from its original value, otherwise it is unchanged Logic Microoperations 37 3/9/2024 By Haftom B.
- 38. SELECTIVE CLEAR In a selective clear operation, the bit pattern in B is used to clear certain bits in A 1 1 0 0 At 1 0 1 0 B 0 1 0 0 At+1 (A A B’) If a bit in B is set to 1, that same position in A gets set to 0, otherwise it is unchanged Logic Microoperations 38 3/9/2024 By Haftom B.
- 39. MASK OPERATION In a mask operation, the bit pattern in B is used to clear certain bits in A 1 1 0 0 At 1 0 1 0 B 1 0 0 0 At+1 (A A B) If a bit in B is set to 0, that same position in A gets set to 0, otherwise it is unchanged Logic Microoperations 39 3/9/2024 By Haftom B.
- 40. CLEAR OPERATION In a clear operation, if the bits in the same position in A and B are the same, they are cleared in A, otherwise they are set in A 1 1 0 0 At 1 0 1 0 B 0 1 1 0 At+1 (A A B) Logic Microoperations 40 3/9/2024 By Haftom B.
- 41. INSERT OPERATION An insert operation is used to introduce a specific bit pattern into A register, leaving the other bit positions unchanged This is done as 1. A mask operation to clear the desired bit positions, followed by 2. An OR operation to introduce the new bits into the desired positions Example Suppose you wanted to introduce 1010 into the low order four bits of A: 1101 1000 1011 0001 A (Original) 1101 1000 1011 1010 A (Desired) 1101 1000 1011 0001 A (Original) 1111 1111 1111 0000 Mask 1101 1000 1011 0000 A (Intermediate) 0000 0000 0000 1010 Added bits 1101 1000 1011 1010 A (Desired) Logic Microoperations 41 3/9/2024 By Haftom B.
- 42. LOGICAL SHIFT In a logical shift the serial input to the shift is a 0. A right logical shift operation: A left logical shift operation: In a Register Transfer Language, the following notation is used shl for a logical shift left shr for a logical shift right Examples: R2 shr R2 R3 shl R3 Shift Microoperations 0 0 42 3/9/2024 By Haftom B.
- 43. CIRCULAR SHIFT In a circular shift the serial input is the bit that is shifted out of the other end of the register. A right circular shift operation: A left circular shift operation: In a RTL, the following notation is used cil for a circular shift left cir for a circular shift right Examples: R2 cir R2 R3 cil R3 Shift Microoperations 43 3/9/2024 By Haftom B.
- 44. LOGICAL VERSUS ARITHMETIC SHIFT A logical shift fills the newly created bit position with zero: • An arithmetic shift fills the newly created bit position with a copy of the number’s sign bit: CF 0 CF 44 3/9/2024 By Haftom B.
- 45. ARITHMETIC SHIFT An left arithmetic shift operation must be checked for the overflow Shift Microoperations 0 V Before the shift, if the leftmost two bits differ, the shift will result in an overflow • In a RTL, the following notation is used –ashl for an arithmetic shift left –ashr for an arithmetic shift right –Examples: »R2 ashr R2 »R3 ashl R3 sign bit 45 3/9/2024 By Haftom B.
- 46. HARDWARE IMPLEMENTATION OF SHIFT MICROOPERATIONS Shift Microoperations S 0 1 H0 MUX S 0 1 H1 MUX S 0 1 H2 MUX S 0 1 H3 MUX Select 0 for shift right (down) 1 for shift left (up) Serial input (IR) A0 A1 A2 A3 Serial input (IL) 46 3/9/2024 By Haftom B.
- 47. S3 S2 S1 S0 Cin Operation Function 0 0 0 0 0 F = A Transfer A 0 0 0 0 1 F = A + 1 Increment A 0 0 0 1 0 F = A + B Addition 0 0 0 1 1 F = A + B + 1 Add with carry 0 0 1 0 0 F = A + B’ Subtract with borrow 0 0 1 0 1 F = A + B’+ 1 Subtraction 0 0 1 1 0 F = A - 1 Decrement A 0 0 1 1 1 F = A TransferA 0 1 0 0 X F = A B AND 0 1 0 1 X F = A B OR 0 1 1 0 X F = A B XOR 0 1 1 1 X F = A’ Complement A 1 0 X X X F = shr A Shift right A into F 1 1 X X X F = shl A Shift left A into F Shift Microoperations Arithmetic Circuit Logic Circuit C C 4 x 1 MUX Select 0 1 2 3 F S3 S2 S1 S0 B A i A D A E shr shl i+1 i i i i+1 i-1 i i 47 3/9/2024 By Haftom B.
- 48. Henry Hexmoor Bitwise Multiplication: SHL can perform multiplication by powers of 2. o Shifting any operand left by n bits multiplies the operand by 2n. o For example, shifting the integer 5 left by 1 bit yields the product o of 5 x 21 = 10: mov dl,5 dl= 00000101 shl dl,1 dl=00001010 o Exercise what will be the value of the Dl=5 in decimal after SHl by 3 is performed o mov dl,5 dl= 00000101 shl dl,3 dl=_______________ 3/9/2024 By Haftom B. 48
- 49. Henry Hexmoor o Bitwise Division: Logically shifting an unsigned integer right by n bits divides the operand by 2n. In the following statements, we divide 32 by 21, producing 16: mov dl,32 ; dl=100000 shr dl,1 ; dl=010000 cf=0 Exercise , write an assembly program that divide 32 by 23 using SHR: mov dl,32 ; dl=______________ shr dl,3 ; dl=______________ cf=______ 3/9/2024 By Haftom B. 49
- 50. Henry Hexmoor 3/9/2024 By Haftom B. 50
- 51. BASIC COMPUTER ORGANIZATION AND DESIGN 51 Chapter 5:
- 52. 5-1 INSTRUCTION CODES The Internal organization of a digital system is defined by the sequence of microoperations it performs on data stored in its registers The user of a computer can control the process by means of a program A program is a set of instructions that specify the operations, operands, and the processing sequence 52 Computer Organization and Architecture
- 53. CONT.… A computer instruction is a binary code that specifies a sequence of micro-operations for the computer. Each computer has its unique instruction set Instruction codes and data are stored in memory The computer reads each instruction from memory and places it in a control register The control unit interprets the binary code of the instruction and proceeds to execute it by issuing a sequence of micro-operations 53 Computer Organization and Architecture
- 54. CONT.… An Instruction code is a group of bits that instructs the computer to perform a specific operation (sequence of microoperations). It is divided into parts (basic part is the operation part) The operation code of an instruction is a group of bits that defines certain operations such as add, subtract, shift, and complement 54 Computer Organization and Architecture
- 55. CONT.. The number of bits required for the operation code depends on the total number of operations available in the computer 2n (or little less) distinct operations n bit operation code 55 Computer Organization and Architecture
- 56. CONT.. An operation must be performed on some data stored in processor registers or in memory An instruction code must therefore specify not only the operation, but also the location of the operands (in registers or in the memory), and where the result will be stored (registers/memory) 56 Computer Organization and Architecture
- 57. CONT.. Memory words can be specified in instruction codes by their address Processor registers can be specified by assigning to the instruction another binary code of k bits that specifies one of 2k registers Each computer has its own particular instruction code format Instruction code formats are conceived by computer designers who specify the architecture of the computer 57 Computer Organization and Architecture
- 58. STORED PROGRAM ORGANIZATION An instruction code is usually divided into operation code, operand address, addressing mode, etc. The simplest way to organize a computer is to have one processor register (accumulator AC) and an instruction code format with two parts (op code, address) 58 Computer Organization and Architecture
- 59. STORED PROGRAM ORGANIZATION 59 Opcode Address Instruction Format Binary Operand Operands (data) Processor register (Accumulator AC) Memory 4096x16 15 12 11 0 15 0 Instruction s (program) 15 0 0 15 CoSc2022: Computer Organization and Architecture
- 60. 5-1 INSTRUCTION CODES INDIRECT ADDRESS There are three Addressing Modes used for address portion of the instruction code: Immediate: the operand is given in the address portion (constant) Move 05 H Direct: the address points to the operand stored in the memory LDA 2500h Indirect: the address points to the pointer (another address) stored in the memory that references the operand in memory Mov A,M One bit of the instruction code can be used to distinguish between direct & indirect addresses 60 Computer Organization and Architecture
- 61. CONT.. 61 Opcode Address Instruction Format 15 14 12 0 I 11 0 ADD 457 22 Operand 457 1 ADD 300 35 1350 300 Operand 1350 + AC + AC Direct Address Indirect address Effective address Computer Organization and Architecture
- 62. 5-2 COMPUTER REGISTERS Computer instructions are normally stored in consecutive memory locations and executed sequentially one at a time. The control reads an instruction from a specific address in memory and executes it, and so on This type of sequencing needs a counter to calculate the address of the next instruction after execution of the current instruction is completed 62 Computer Organization and Architecture
- 63. 5-2 COMPUTER REGISTERS CONT. It is also necessary to provide a register in the control unit for storing the instruction code after it is read from memory The computer needs processor registers for manipulating data and a register for holding a memory address 63 Computer Organization and Architecture
- 64. 64 List of BC Registers DR 16 Data Register Holds memory operand AR 12 Address Register Holds address for memory AC 16 Accumulator Processor register IR 16 Instruction Register Holds instruction code PC 12 Program Counter Holds address of instruction TR 16 Temporary Register Holds temporary data INPR 8 Input Register Holds input character OUTR 8 Output Register Holds output character Registers in the Basic Computer 11 0 PC 15 0 IR 15 0 TR 7 0 OUTR 15 0 DR 15 0 AC 11 0 AR INPR 0 7 Memory 4096 x 16 Computer Organization and Architecture
- 65. 65 S2 S1 S0 Bus Memory unit 4096 x 16 LD INR CLR Address Read Write AR LD INR CLR PC LD INR CLR DR LD INR CLR AC Adder and logic E INPR IR LD LD INR CLR TR OUTR LD Clock 16-bit common bus 7 1 2 3 4 5 6 Computer Registers Common Bus System Computer Organization and Architecture
- 66. 5-2 COMPUTER REGISTERS COMMON BUS SYSTEM S2S1S0: Selects the register/memory that would use the bus LD (load): When enabled, the particular register receives the data from the bus during the next clock pulse transition E (extended AC bit): flip-flop holds the carry DR, AC, IR, and TR: have 16 bits each AR and PC: have 12 bits each since they hold a memory address 66 Computer Organization and Architecture
- 67. CONT.. When the contents of AR or PC are applied to the 16-bit common bus, the four most significant bits are set to zeros When AR or PC receives information from the bus, only the 12 least significant bits are transferred into the register INPR and OUTR: communicate with the eight least significant bits in the bus 67 Computer Organization and Architecture
- 68. CONT.. INPR: Receives a character from the input device (keyboard,…etc) which is then transferred to AC OUTR: Receives a character from AC and delivers it to an output device (say a Monitor) Five registers have three control inputs: LD (load), INR (increment), and CLR (clear) 68 Computer Organization and Architecture
- 69. 5-2 COMPUTER REGISTERS MEMORY ADDRESS The input data and output data of the memory are connected to the common bus But the memory address is connected to AR Therefore, AR must always be used to specify a memory address By using a single register for the address, we eliminate the need for an address bus that would have been needed otherwise 69 Computer Organization and Architecture
- 70. 5-2 COMPUTER REGISTERS MEMORY ADDRESS CONT. Register Memory: Write operation Memory Register: Read operation (note that AC cannot directly read from memory!!) Note that the content of any register can be applied onto the bus and an operation can be performed in the adder and logic circuit during the same clock cycle 70 Computer Organization and Architecture
- 71. 5-2 COMPUTER REGISTERS MEMORY ADDRESS CONT. The transition at the end of the cycle transfers the content of the bus into the destination register, and the output of the adder and logic circuit into the AC For example, the two microoperations DR←AC and AC←DR (Exchange) can be executed at the same time 71 Computer Organization and Architecture
- 72. 5-2 COMPUTER REGISTERS MEMORY ADDRESS CONT. 1- place the contents of AC on the bus (S2S1S0=100) 2- enabling the LD (load) input of DR 3- Transferring the contents of the DR through the adder and logic circuit into AC 4- enabling the LD (load) input of AC All during the same clock cycle The two transfers occur upon the arrival of the clock pulse transition at the end of the clock cycle 72 CoSc2022: Computer Organization and Architecture
- 73. 5-3 COMPUTER INSTRUCTIONS 73 Memory-Reference Instructions (OP-code = 000 ~ 110) Basic Computer Instruction code format 15 14 12 11 0 I Opcode Address Register-Reference Instructions (OP-code = 111, I = 0) Input-Output Instructions (OP-code =111, I = 1) 15 12 11 0 Register operation 0 1 1 1 15 12 11 0 I/O operation 1 1 1 1 CoSc2022: Computer Organization and Architecture
- 74. BASIC COMPUTER INSTRUCTIONS 74 Hex Code Symbol I = 0 I = 1 Description AND 0xxx 8xxx AND memory word to AC ADD 1xxx 9xxx Add memory word to AC LDA 2xxx Axxx Load AC from memory STA 3xxx Bxxx Store content of AC into memory BUN 4xxx Cxxx Branch unconditionally BSA 5xxx Dxxx Branch and save return address ISZ 6xxx Exxx Increment and skip if zero CLA 7800 Clear AC CLE 7400 Clear E CMA 7200 Complement AC CME 7100 Complement E CIR 7080 Circulate right AC and E CIL 7040 Circulate left AC and E INC 7020 Increment AC SPA 7010 Skip next instr. if AC is positive SNA 7008 Skip next instr. if AC is negative SZA 7004 Skip next instr. if AC is zero SZE 7002 Skip next instr. if E is zero HLT 7001 Halt computer INP F800 Input character to AC OUT F400 Output character from AC SKI F200 Skip on input flag SKO F100 Skip on output flag ION F080 Interrupt on IOF F040 Interrupt off
- 75. 5-3 COMPUTER INSTRUCTIONS INSTRUCTION SET COMPLETENESS The set of instructions are said to be complete if the computer includes a sufficient number of instructions in each of the following categories: Arithmetic, logical, and shift instructions Instructions for moving information to and from memory and processor registers Program control instructions together with instructions that check status conditions Input & output instructions 75 Computer Organization and Architecture
- 76. 5-4 TIMING & CONTROL The timing for all registers in the basic computer is controlled by a master clock generator. The clock pulses are applied to all flip-flops and registers in the system, including the flip-flops and registers in the control unit The clock pulses do not change the state of a register unless the register is enabled by a control signal (i.e., Load) 76 Computer Organization and Architecture
- 77. 5-4 TIMING & CONTROL The control signals are generated in the control unit and provide control inputs for the multiplexers in the common bus, control inputs in processor registers, and microoperations for the accumulator There are two major types of control organization: Hardwired control Microprogrammed control 77 Computer Organization and Architecture
- 78. 5-4 TIMING & CONTROL In the hardwired organization, the control logic is implemented with gates, flip-flops, decoders, and other digital circuits. In the microprogrammed organization, the control information is stored in a control memory (if the design is modified, the microprogram in control memory has to be updated) D3T4: SC←0 78 CoSc2022: Computer Organization and Architecture
- 79. 79 I The Control Unit for the basic computer Hardwired Control Organization Instruction register (IR) 15 14 13 12 11 - 0 3 x 8 decoder 7 6 5 4 3 2 1 0 Control logic gates D0 15 14 . . . . 2 1 0 4 x 16 Sequence decoder 4-bit sequence counter (SC) Increment (INR) Clear (CLR) Clock Other inputs Control outputs D T T 7 15 0 Computer Organization and Architecture
- 80. 80 Clock T0 T1 T2 T3 T4 T0 T0 T1 T2 T3 T4 D3 CLR SC - Generated by 4-bit sequence counter and 4x16 decoder - The SC can be incremented or cleared. - Example: T0, T1, T2, T3, T4, T0, T1, . . . Assume: At time T4, SC is cleared to 0 if decoder output D3 is active. D3T4: SC 0 Computer Organization and Architecture
- 81. 5-4 TIMING & CONTROL CONT. A memory read or write cycle will be initiated with the rising edge of a timing signal Assume: memory cycle time < clock cycle time! So, a memory read or write cycle initiated by a timing signal will be completed by the time the next clock goes through its positive edge The clock transition will then be used to load the memory word into a register The memory cycle time is usually longer than the processor clock cycle wait cycles 81 Computer Organization and Architecture
- 82. 5-4 TIMING & CONTROL CONT. T0: AR←PC Transfers the content of PC into AR if timing signal T0 is active T0 is active during an entire clock cycle interval During this time, the content of PC is placed onto the bus (with S2S1S0=010) and the LD (load) input of AR is enabled The actual transfer does not occur until the end of the clock cycle when the clock goes through a positive transition This same positive clock transition increments the sequence counter SC from 0000 to 0001 The next clock cycle has T1 active and T0 inactive 82 Computer Organization and Architecture
- 83. 5-5 INSTRUCTION CYCLE A program is a sequence of instructions stored in memory The program is executed in the computer by going through a cycle for each instruction (in most cases) Each instruction in turn is subdivided into a sequence of sub- cycles or phases 83 Computer Organization and Architecture
- 84. 5-5 INSTRUCTION CYCLE CONT. Instruction Cycle Phases: 1- Fetch an instruction from memory 2- Decode the instruction 3- Read the effective address from memory if the instruction has an indirect address 4- Execute the instruction This cycle repeats indefinitely unless a HALT instruction is encountered 84 Computer Organization and Architecture
- 85. 5-5 INSTRUCTION CYCLE FETCH AND DECODE Initially, the Program Counter (PC) is loaded with the address of the first instruction in the program The sequence counter SC is cleared to 0, providing a decoded timing signal T0 After each clock pulse, SC is incremented by one, so that the timing signals go through a sequence T0, T1, T2, and so on 85 CoSc2022: Computer Organization and Architecture
- 86. 5.6 MEMORY REFERENCE INSTRUCTIONS 86 Symbol Operation Decoder Symbolic Description AND D0 AC AC M[AR] ADD D1 AC AC + M[AR], E Cout LDA D2 AC M[AR] STA D3 M[AR] AC BUN D4 PC AR BSA D5 M[AR] PC, PC AR + 1 ISZ D6 M[AR] M[AR] + 1, if M[AR] + 1 = 0 then PC PC+1 CoSc2022: Computer Organization and Architecture
- 87. CONT.. 87 - The effective address of the instruction is in AR and was placed there during timing signal T2 when I = 0, or during timing signal T3 when I = 1 - Memory cycle is assumed to be short enough to be completed in a CPU cycle - The execution of MR Instruction starts with T4 AND to AC D0T4: DR M[AR] Read operand D0T5: AC AC DR, SC 0 AND with AC ADD to AC D1T4: DR M[AR] Read operand D1T5: AC AC + DR, E Cout, SC 0 Add to AC and store carry in E
- 88. MEMORY REFERENCE INSTRUCTIONS. LDA: Load to AC D2T4: DR M[AR] D2T5: AC DR, SC 0 STA: Store AC D3T4: M[AR] AC, SC 0 BUN: Branch Unconditionally D4T4: PC AR, SC 0 BSA: Branch and Save Return Address M[AR] PC, PC AR + 1 Computer Organization and Architecture
- 89. 89 BSA: executed in a sequence of two micro-operations: D5T4:M[AR] PC, AR AR + 1 D5T5:PC AR, SC 0 ISZ: Increment and Skip-if-Zero D6T4:DR M[AR] D6T5:DR DR + 1 D6T6: M[AR] DR, if (DR = 0) then (PC PC + 1), SC 0 Cont.. Computer Organization and Architecture
- 90. 90 Memory-reference instruction DR M[AR] DR M[AR] DR M[AR] M[AR] AC SC 0 AND ADD LDA STA AC AC DR SC <- 0 AC AC + DR E Cout SC 0 AC DR SC 0 D T 0 4 D T 1 4 D T 2 4 D T 3 4 D T 0 5 D T 1 5 D T 2 5 PC AR SC 0 M[AR] PC AR AR + 1 DR M[AR] BUN BSA ISZ D T 4 4 D T 5 4 D T 6 4 DR DR + 1 D T 5 5 D T 6 5 PC AR SC 0 M[AR] DR If (DR = 0) then (PC PC + 1) SC 0 D T 6 6 Computer Organization and Architecture
- 91. 5-9 DESIGN OF BASIC COMPUTER 1. A memory unit: 4096 x 16. 2. Registers: AR, PC, DR, AC, IR, TR, OUTR, INPR, and SC 3. Flip-Flops (Status): I, S, E, R, IEN, FGI, and FGO 4. Decoders: 1. a 3x8 Opcode decoder 2. a 4x16 timing decoder 5. Common bus: 16 bits 6. Control logic gates 7. Adder and Logic circuit: Connected to AC 91 Computer Organization and Architecture
- 92. 5-9 DESIGN OF BASIC COMPUTERCONT. The control logic gates are used to control: Inputs of the nine registers Read and Write inputs of memory Set, Clear, or Complement inputs of the flip-flops S2, S1, S0 that select a register for the bus AC Adder and Logic circuit 92 Computer Organization and Architecture
- 93. 5-9 DESIGN OF BASIC COMPUTERCONT. Control of registers and memory The control inputs of the registers are LD (load), INR (increment), and CLR (clear) To control AR We scan table 5-6 to find out all the statements that change the content of AR: R’T0: AR PC LD(AR) R’T2: AR IR(0-11) LD(AR) D’7IT3: AR M[AR] LD(AR) RT0: AR 0 CLR(AR) D5T4: AR AR + 1 INR(AR) 93 Computer Organization and Architecture
- 94. 5-9 DESIGN OF BASIC COMPUTERCONT. 94 AR LD INR CLR Clock To bus From bus D' I T T R T D5 T 7 3 2 0 4 Control Gates associated with AR Computer Organization and Architecture
- 95. 5-9 DESIGN OF BASIC COMPUTER CONT. To control the Read input of the memory we scan the table again to get these: D0T4: DR M[AR] D1T4: DR M[AR] D2T4: DR M[AR] D6T4: DR M[AR] D7′IT3: AR M[AR] R′T1: IR M[AR] Read = R′T1 + D7′IT3 + (D0 + D1 + D2 + D6 )T4 95 Computer Organization and Architecture
- 96. 5-9 DESIGN OF BASIC COMPUTERCONT. Control of Single Flip-flops (IEN for example) pB7: IEN 1 (I/O Instruction) pB6: IEN 0 (I/O Instruction) RT2: IEN 0 (Interrupt) where p = D7IT3 (Input/Output Instruction) If we use a JK flip-flop for IEN, the control gate logic will be as shown in the following slide: 96 Computer Organization and Architecture
- 97. 5-9 DESIGN OF BASIC COMPUTER CONT. J K Q(t+1) 0 0 Q(t) 0 1 0 1 0 1 1 1 Q’(t) 97 D I T3 7 J K Q IEN p B 7 B 6 T2 R JK FF Characteristic Table Computer Organization and Architecture
- 98. 5-10 DESIGN OF ACCUMULATOR LOGIC 98 Circuits associated with AC All the statements that change the content of AC 16 16 8 Adder and logic circuit 16 AC From DR From INPR Control gates LD INR CLR 16 To bus Clock D0T5: AC AC DR AND with DR D1T5: AC AC + DR Add with DR D2T5: AC DR Transfer from DR pB11: AC(0-7) INPR Transfer from INPR rB9: AC AC’ Complement rB7 : AC shr AC, AC(15) E Shift right rB6 : AC shl AC, AC(0) E Shift left rB11 : AC 0 Clear rB5 : AC AC + 1 Increment
- 99. 5-10 DESIGN OF ACCUMULATOR LOGIC 99 Gate structures for controlling the LD, INR, and CLR of AC AC LD INR CLR Clock To bus 16 From Adder and Logic 16 AND ADD LDA INPR COM SHR SHL INC CLR D0 D1 D2 B11 B9 B7 B6 B5 B11 r p T5 T5 Computer Organization and Architecture
- 100. ADDER AND LOGIC CIRCUIT 100 AND ADD LDA INPR COM SHR SHL J K Q AC(i) LD FA C C From INPR bit(i) DR(i) AC(i) AC(i+1) AC(i-1) i i i+1 I CoSc2022: Computer Organization and Architecture
- 101. Chapter Six Central Processing Unit 3/9/2024 Prepared By Haftom B. 101
- 102. Contents 3/9/2024 Prepared By Haftom B. 102 Central processing unit (4hr) 1. General register organization 2. Stack organization 3. Instruction formats 4. Addressing modes 5. Data transfer and manipulation 6. Characteristics of RISC and CISC
- 103. 6.1 Central Processing Unit (CPU) 3/9/2024 Prepared By Haftom B. 103 The part of the computer that performs the bulk of data processing operations is called the Central processing unit and is referred to as the CPU. It is the heart of computer system. The CPU is made up of three major parts, Register The Arithmetic and Logic unit (ALU) The control unit
- 104. Cont.. 3/9/2024 Prepared By Haftom B. 104 The register set stores intermediate data used during the execution of the instructions. The Arithmetic and Logic unit (ALU) performs the required micro-operations for executing the instructions. The control unit supervises the transfer of information among the registers and instructs the arithmetic and logic units as to which operation to perform.
- 105. Cont.. 3/9/2024 Prepared By Haftom B. 105 The CPU performs a variety of functions dictated by the type of instructions that are incorporated in the computer. Computer architecture is sometimes defined as the computer structure and behavior as seen by the programmer that uses machine language instructions. This includes the Instruction formats, Addressing modes, The instruction sets and the General organizations of the CPU registers.
- 106. 6.2 General register organization 3/9/2024 Prepared By Haftom B. 106 We have shown that memory locations are needed for storing Pointers, Counters, Return addresses, Temporary results and Partial product during multiplication. It is more convenient and more efficient to store these intermediate values in processor register.
- 107. Cont.… 3/9/2024 Prepared By Haftom B. 107 When a large number of registers are included in the CPU, it is most efficient to connect them through a common bus system. The registers communicate with each other not only for direct data transfers, but also while performing various micro-operations. it is also necessary to provide a common unit that can perform all the arithmetic, logic shift micro-operations in the processor.
- 108. Cont.. 3/9/2024 Prepared By Haftom B. 108 For example, to perform the operation R1 R2 + R3, the control must provide binary selection variables to the following selector inputs: 1. MUX A selector (SELA): to place the content of R2 into bus A. 2. MUX B selector (SELB): to place the content of R3 into bus B. 3. ALU operation selector (OPR): to provide the arithmetic addition A +B. 4. Decoder destination selector (SELD): to transfer the content of output bus in to R1. The four control selection variables are generated in the control unit and must be available at the beginning of a clock cycle.
- 109. Diagrams Representations 3/9/2024 Prepared By Haftom B. 109
- 110. Example of Micro Operations Encoding of register selection fields 3/9/2024 Prepared By Haftom B. 110
- 111. Examples of Micro-Operations for the CPU 3/9/2024 Prepared By Haftom B. 111
- 112. 6.3 Stack Organization 3/9/2024 Prepared By Haftom B. 112 A useful feature that is included in the CPU of most computers is a stack or last- in, first-out (LIFO) list. A stack is a storage device that stores information in such a manner that the item stored last is the first item retrieved. The stack in digital computers is essentially a memory unit with an address register that can count only (after an initial value is loaded into it). The register that holds the address for the stack is called a stack pointer (SP) because its value always points at the top in the stack.
- 113. Cont.. 3/9/2024 Prepared By Haftom B. 113 The two operations of a stack are the insertion and deletion of items. The operation of the insertion is called PUSH (or push-down) because it can be thought of as the result of pushing a new item on top. The operation of deletion is called POP (or pop-up) because it can be thought as the result of removing one item so that the stack pops up. However, nothing is pushed or popped in a computer stack. In computers, these operations are simulated by incrementing or decrementing the stack pointer register.
- 114. Example 3/9/2024 Prepared By Haftom B. 114 A new item is inserted with the push operation as follows: SP SP - 1 M[SP]DR the pop operation as follows: DRM[SP] SPSP + 1
- 115. Cont.. 3/9/2024 Prepared By Haftom B. 115 The two micro-operations needed for either the push or pop are: 1. An access to memory through SP and 2. Updating SP.
- 116. 6.4 Instruction Formats 3/9/2024 Prepared By Haftom B. 116 A computer will usually have a variety of instruction code formats. The bits of the instruction are divided into groups called Fields. The most common fields found in instruction formats are: 1. An operation code field that specifies the operation to be performed 2. An address field that designate a memory address or a processor register 3. A mode field that specifies the way the operand or the effective address is determined
- 117. Cont.. 3/9/2024 Prepared By Haftom B. 117 Computers may have instruction of several lengths containing varying number of addresses. The number of address field in the instruction format of a computer depends on the internal organization of its registers. Most computers fall into one of three types CPU organizations. 1. Single accumulator organization 2. General register organization 3. Stack organization
- 118. Single accumulator organization 3/9/2024 Prepared By Haftom B. 118 In this organization all operations are performed with an implied accumulator register. The instruction format in this type of computer uses one address field. For example, the instruction that specifies an arithmetic addition is defined by an assembly language: ADD X, where X is the address of the operand. Which results ACX+M(X) AC is the accumulator register and M[X] symbolizes the memory word located at address X.
- 119. General register organization 3/9/2024 Prepared By Haftom B. 119 The instruction format in a computer with a general register organization type needs two or three register address fields. e.g. ADD R1, R2, R3 R1 R2 + R3. e.g. ADD R1, R2 denotes R1 R1 + R2. Only register addresses for R1 and R2 need be specified in this instruction. e.g. ADD R1, X denotes R1 R1 + M[x]. It has two address fields, one for register R1 and the other for the memory address X.
- 120. Stack-organization 3/9/2024 Prepared By Haftom B. 120 Computers with stack-organization would have PUSH and POP instructions which require an address field. E.g. PUSH X will push the word at address X to the top of the stack. Operation-type (e.g. ADD) instructions do not need an address field in stack- organized computers. This is because the operation is performed on the two items that are on top of the stack.
- 121. Full examples using one, Two- Address and three Instruction 3/9/2024 Prepared By Haftom B. 121 The program in assembly language that evaluates X = (A+B) * (C+D) ADDR1,A,B R1 M[A]+M[B] ADDR2,C,D R2 M[C]+M[D] MULX,R1,R2 M[X] R1*R2 MOV R1, A R1 M[A] ADD R1, B R1 R1 + M[B] MOV R2, C R2 M[C] ADD R2, D R2 R2 + M[D] MUL R1, R2 R1 R1 * R2 MOV X, R1 M[X] R1 LOAD A AC M[A] ADD B AC AC + M[B] STORE T M[T] AC LOAD C AC M[C] ADD D AC AC + M[D] MUL T AC AC * M[T] STORE X M[X] AC
- 122. RISC Instructions 3/9/2024 Prepared By Haftom B. 122 RISC stands for reduced instruction set computer. A program for a RISC-type CPU consists of LOAD and STORE instructions that have one memory and one register address and computational-type instructions that have three addresses with all three specifying processor registers.
- 123. The following is a program to evaluate X = (A+B) (C+D). 3/9/2024 Prepared By Haftom B. 123 LOAD R1, A R1 M[A] LOAD R2, B R2 M[B] LOAD R3, C R3 M[C] LOAD R4, D R4 M[D] ADD R1, R1, R2 R1 R1 + R2 ADD R3, R3, R4 R3 R3 + R4 MUL R1, R1, R3 R1 R1* R3 STORE X, R1 M[X] R1
- 124. 6.5 Addressing Mode 3/9/2024 Prepared By Haftom B. 124 The way the operands are chosen during program execution is dependent on the addressing mode of the instruction. The addressing mode specifies a rule for interpreting or modifying the address field of the instruction before the operand is actually referenced. Computers use addressing mode techniques for the purpose of accommodating one or both of the following provisions. 1. To give programming versatility to the user by providing such facilities as pointers to memory, counters for loop control, indexing of data and program relocation. 2. To reduce the number of bits in the addressing field of the instruction
- 125. Cont.. 3/9/2024 Prepared By Haftom B. 125 The availability of the addressing modes gives the experienced assembly language programmer flexibility for writing programs that are more efficient with respect to the number of instructions and execution time.
- 126. Cont.. 3/9/2024 Prepared By Haftom B. 126 The control unit of a computer is designed to go through an instruction cycle that is divided into three major phases. 1. Fetch the instruction from memory (PC) 2. Decode the instruction 3. Execute the instruction
- 127. Types of Addressing Modes 3/9/2024 Prepared By Haftom B. 127 Implied Mode operands are specified implicitly example complement accumulator Immediate Mode operand is specified in the instruction itself immediate value assigning Register Mode operands are in registers that reside within the CPU Register Indirect Mode Mode the instruction specifies a register in the CPU whose contents give the address of the operand in memory
- 128. Cont.. 3/9/2024 Prepared By Haftom B. 128 Auto-increment and Auto-decrement Mode the register is incremented or decremented after (or before) its value is used to access memory. Direct Addressing Mode Direct addressing is a scheme in which the address specifies which memory word or register contains the operand. Example: LOAD R1, 100 Indirect Addressing Mode the address field of the instruction gives the address where the effective address is stored in memory Relative Addressing mode content of program counter is added to the address part of the instruction in order to obtain the effective address.
- 129. 6.6 Data Transfer and Manipulation 3/9/2024 Prepared By Haftom B. 129 Computers provide an extensive set of instruction to give the user the flexibility to carry out various computational tasks. Most computer instructions can be classified in to three categories. 1. Data transfer instruction. 2. Data manipulation instruction 3. Program control instruction
- 130. 1. Data transfer instruction: 3/9/2024 Prepared By Haftom B. 130 Data transfer instructions move data from place to place in the computer to another without changing the data content. The most common transfers are between memory and processor registers, between processor register and input or output, and between the processor registers themselves.
- 131. 2. Data Manipulation: 3/9/2024 Prepared By Haftom B. 131 Data manipulation instructions perform operations on data and provide the computational capabilities for the computer. The data manipulation instructions in a typical computer are usually divided into three basic types. 1. Arithmetic instruction 2. Logical and bit manipulation 3. Shift instruction
- 132. Cont.. 3/9/2024 Prepared By Haftom B. 132 Arithmetic Instruction: The four basic arithmetic operations are addition, subtraction, multiplication and division. Most computers provide instructions for all four operations. Some small computers have only addition and possibly subtraction instructions. The multiplication and division must then be generated by means of software subroutines. The four basic arithmetic operations are sufficient for formulating solution to scientific problems when expressed in terms of numerical analysis methods.
- 133. Cont.. 3/9/2024 Prepared By Haftom B. 133 Logical and Bit Manipulation Instructions: Logical instructions perform binary operations on strings of bits stored in registers. They are useful for manipulating individual bits or a group of bits that represent binary–coded information. The logical instructions consider each bit of the operands separately and treat it as a Boolean variable. By proper application of the logical instructions it is possible to change bit values, to clear a group of bits or to insert new bit values into the operands stored in registers or memory words.
- 134. Cont.. 3/9/2024 Prepared By Haftom B. 134 Shift Instruction: Instructions to shift the content of an operand are quite useful and are often provided in several variations. Shifts are operations in which the bits of a word are moved to the left or right. The bit shifted in at the end of the word determines the type of shift used. Shift instructions may specify either logical shifts, arithmetic shifts, or rotate type operations. In either case the shift may be to the right or to the left.
- 135. Reduced Instruction Set computer (RISC) 3/9/2024 Prepared By Haftom B. 135 The instruction set chosen for a particular computer determines the way that machine language programs are constructed. Early computers had small and simple instruction sets, forced mainly by the need to minimize the hardware to implement them. Many computers have instruction sets that include more than 100 and sometimes even more than 200 instructions. These computers also employ a variety of data types and a large number of addressing modes
- 136. Cont.. 3/9/2024 Prepared By Haftom B. 136 A computer with a large number of instructions is classified as a complex instruction set computer, abbreviated as CISC. In the early 1980_s, a number of computer designers recommended that computers use fewer instructions with simple constructs so they can be executed much faster within the CPU without having to use memory as often. This type of computer is classified as a Reduced Instruction Set Computer (RISC).
- 137. CISC characteristics 3/9/2024 Prepared By Haftom B. 137 Large number of instructions – typically from 100 to 250 instructions Some instructions that perform specialized tasks and are used infrequently A large variety of addressing modes – typically from 5 to 20 different modes Variable length instruction formats Instructions that manipulate operands in memory
- 138. RISC characteristics 3/9/2024 Prepared By Haftom B. 138 Relatively few instructions Relatively few addressing modes Memory access limited to load and store instructions All operations done within the register of the CPU Fixed length, easily decoded instruction format Single cycle instruction execution Hard-wired rather than micro-programmed control A relatively large number of registers in the processor Use overlapped register windows to speed up procedure call and return Efficient instruction pipeline Compiler support for efficient transmission high-level language programs into machine language programs
- 139. Thanks The End 3/9/2024 Prepared By Haftom B. 139
- 141. Memory is unit used for storage, and retrieval of data and instructions. A typical computer system is equipped with a hierarchy of memory subsystems, some internal to the system and some external. Internal memory systems are accessible by the CPU directly and external memory systems are accessible by the CPU through an I/O module prepared by haftom B. 141
- 142. Memory systems are classified according to their the following characteristics 1. Location: The classification of memory is done according to the location of the memory as: Registers: The CPU requires its own local memory in the form of registers and also control unit requires local memories which are fast accessible. Internal (main): is often associated with the main memory (RAM) External (secondary): consists of peripheral storage devices like Hard disks, magnetic tapes, etc. prepared by haftom B. 142
- 143. 2. Capacity: Storage capacity is one of the important aspects of the memory. It is measured in bytes. Since the capacity of memory in a typical memory is very large, the prefixes kilo (K), mega (M), and giga(G). A kilobyte is 210 = 1024 bytes, a megabyte is 220 bytes, and a giga byte is 230 bytes. prepared by haftom B. 143
- 144. 3. Unit of Transfer: Unit of transfer for internal memory is equal to the number of data lines into and out of memory module. Word: For internal memory, unit of transfer is equal to the number of data lines into and out of the memory module. Block: For external memory, data are often transferred in much larger units than a word, and these are referred to as blocks. prepared by haftom B. 144
- 145. 4. Access Method Sequential: Tape units have sequential access. Data are generally stored in units called “records”. Data is accessed sequentially; Random: Each addressable location in memory has a unique addressing mechanism. The time to access a given location is independent of the sequence of prior accesses and constant. Any location can be selected at random and directly addressed and accessed. Main memory and cache systems are random access. prepared by haftom B. 145
- 146. 5. Performance Access time: For random-access memory, this is the time it takes to perform a read or write operation: Transfer rate: This is the rate at which data can be transferred into or out of a memory unit. prepared by haftom B. 146
- 147. 6. Physical Type Semiconductor: Main memory, cache. RAM, ROM. Magnetic: Magnetic disks (hard disks), magnetic tape units. Optical: CD, DVD. prepared by haftom B. 147
- 148. 7. Physical Characteristics Volatile/nonvolatile: In a volatile memory, information decays naturally or is lost when electrical power is switched off. Erasable/nonerasable: Nonerasable memory cannot be altered (except by destroying the storage unit). ROM’s are nonerasable. prepared by haftom B. 148
- 149. A computer system is equipped with a hierarchy of memory subsystems. There are several memory types with very different physical properties. The important characteristics of memory devices are cost per bit, access time, data transfer rate, alterability and compatibility with processor technologies. prepared by haftom B. 149
- 150. prepared by haftom B. 150
- 151. 1. Main Memory The main memory (RAM) stores data and instructions In active use RAMs are built from semiconductor materials. Semiconductor memories fall into two categories, 1. SRAMs (static RAMs) 2. DRAMs (dynamic RAMs). prepared by haftom B. 151
- 152. I. DYNAMIC RAM (DRAM) is made with cells that store data as charge on capacitors. The presence or absence of charge in a capacitor is interpreted as a binary 1 or 0. II. STATIC RAM (SRAM) binary values are stored using traditional flip-flop logic-gate. A static RAM will hold its data as long as power is supplied to it. Static RAM’s are faster than dynamic RAM’s. prepared by haftom B. 152
- 153. ROM: The data is actually wired in the factory. The data can never be altered. PROM: Programmable ROM. It can only be programmed once after its fabrication. It requires special device to program. prepared by haftom B. 153
- 154. EPROM: Erasable Programmable ROM. It can be programmed multiple times. Whole capacity need to be erased by ultraviolet radiation before a new programming activity. It cannot be partially programmed. EEPROM: Electrically Erasable Programmable ROM. Erased and programmed electrically. It can be partially programmed. Write operation takes considerably longer time compared to read operation. prepared by haftom B. 154
- 155. Cache memory is a small, high-speed RAM buffer located between the CPU and main memory. Cache memory holds a copy of the instructions (instruction cache) or data (operand or data cache) currently being used by the CPU. The main purpose of a cache is to accelerate your computer while keeping the price of the computer low. prepared by haftom B. 155
- 156. High speed SRAM A memory that can be accessed more quicker than the regular main memory of Ram It is also called CPU Memory The performance of the cache memory is measured in terms of Hit Ratio prepared by haftom B. 156
- 157. prepared by haftom B. 157
- 158. Cache memory woks under three different configurations 1. Direct mapped cache 2. Fully associative cache 3. Set associative cache mapping prepared by haftom B. 158
- 159. 1. DIRECT MAPPED CACHE Has each block mapped to exactly one cache memory location. prepared by haftom B. 159
- 160. Similar to direct mapping in structure But allows block to be mapped to any Location rather than a predefined cache memory Location prepared by haftom B. 160
- 161. each cache location can have more than one pair of tag + data items. more flexible mapping of the fully associative cache. prepared by haftom B. 161
- 162. Are used when there is no available space in a cache in which to place a data. Four of the most common algor 1. Least Recently Used (LRU): selects for replacement the item that has been least recently used by the CPU. 2. First-In-First-Out (FIFO): selects for replacement the item that has been in the cache from the longest time. 3. Least Frequently Used (LRU): The LRU algorithm selects for replacement the item that has been least frequently used by the CPU. 4. Random: The random algorithm selects for replacement the item randomly. prepared by haftom B. 162
- 163. The term virtual memory refers to something which appears to be present but actually it is not. The virtual memory technique allows users to use more memory for a program than the real memory of a computer. virtual memory is the concept that gives the illusion to the user that they will have main memory equal to the capacity of secondary storage media. prepared by haftom B. 163
- 164. A programmer can write a program which requires more memory space than the capacity of the main memory. Such a program is executed by virtual memory technique. The program is stored in the secondary memory. The memory management unit (MMU) transfers the currently needed part of the program from the secondary memory to the main memory for execution. The movement of instructions and data between the main memory and the secondary memory is called Swapping. prepared by haftom B. 164
- 165. also referred to as secondary storage) refer to as auxiliary storage, secondary storage, secondary memory, external storage or external memory is the non-volatile memory lowest-cost, highest- capacity, and slowest-access storage in a computer system. It is where programs and data kept for long-term storage or when not in immediate use. prepared by Haftom B. 165
- 166. Auxiliary memory is not directly accessible by the CPU; large data files, documents, programs and back up information that supplied to primary memory from auxiliary memory over a high-bandwidth channel, which will use whenever necessary. Auxiliary memory holds data for future use, and that retains information even the power fails. prepared by haftom B. 166
- 167. A type of computer memory from which items may be retrieved by matching some part of their content, rather than by specifying their address. also called associative storage or Content- addressable memory (CAM). Associative memory is much slower than RAM, and is rarely encountered in mainstream computer designs. prepared by haftom B. 167
- 168. Computer Organization & Architecture Chapter 8:Input / Output Organization 3/9/2024 Prepared Haftom B 168 ADMAS UNIVERSITY Department of Computer Science
- 169. External Devices The input/output subsystem of a computer, referred to as I/O, provides an efficient mode of communication between the central system and the outside environment. Programs and data must be entered into computer memory for processing and results obtained from computations must be recorded or displayed for users. A computer serves no useful purpose without the ability to receive information from an outside source and to transmit results in a meaningful form. I/O operations are accomplished through a wide assortment of external devices that provide a means of exchanging data between the external environment and the computer. 3/9/2024 Prepared Haftom B 169
- 170. External Devices Cont.… An external device attaches to the computer by a link to an I/O module. The link is used to exchange control, status, and data between the I/O module and the external device. An external device connected to an I/O module also called Interface is often referred to as a peripheral device or simply a peripheral. 3/9/2024 Prepared Haftom B 170
- 171. 3/9/2024 Prepared Haftom B 171
- 172. External Devices Cont.… 3/9/2024 Prepared Haftom B 172 Input/output interface Problems Wide variety of peripherals and Delivering different amounts of data per second Work at different speeds Send/receive data in different formats. All slower than CPU and RAM. Hence I/O modules are used as a solution
- 173. Classification of External devices • External devices broadly can be classified into three categories: • Human readable: suitable for communicating with the computer user. Examples: Screen, keyboard, video display terminals (VDT) and printers. • Machine readable: suitable for communicating with equipment’s. Examples: magnetic disk & tapes systems, Monitoring and control, sensors and actuators which are used in robotics. • Communication: These devices allow a computer to exchange data with remote devices, which may be machine readable or human readable. Examples: Modem, Network Interface Card (NIC) 3/9/2024 Prepared Haftom B 173
- 174. 3/9/2024 Prepared Haftom B 174 It is the entity within a computer that is responsible for the control of one or more external devices Interface to CPU and memory Interface to one or more peripherals I/O Module Function The major functions or requirements for an I/O module fall into the following five categories. Control & Timing CPU Communication Device Communication Data Buffering Error Detection Input/output Module
- 175. I/O Module Function Cont.… Processor might involve in sequence of operations like: CPU checks I/O module device status I/O module returns device status If ready, CPU requests data transfer I/O module gets data from device I/O module transfers data to CPU Variations for output, DMA, etc. I/O module must have the capability to engage in communication with the CPU and external device. 3/9/2024 Prepared Haftom B 175
- 176. Thus CPU communication involves: • Command decoding: The I/O module accepts commands from the CPU carried on the control bus. • Data exchange : data are exchanged between the CPU and the I/O module over data bus. 3/9/2024 Prepared Haftom B 176
- 177. I/O Module Function Cont.… Status reporting: Because peripherals are slow it is important to know the status of I/O device. • I/O module can report with the status signals common used status signals are BUSY or READY. • Various other status signals may be used to report various error conditions. Address recognition: just as each memory word has an address, there is address associated with every I/O device. • Thus I/O module must be recognized with a unique address for each peripheral it controls. 3/9/2024 Prepared Haftom B 177
- 178. I/O Module Function Cont.… The I/O module must also be able to perform device communication. This communication involves commands, status information, and data. Some of the essentials tasks are listed below: o Error detection: I/O module is often responsible for error detection and subsequently reporting errors to the CPU. o Data buffering: the transfer rate into and out of main memory or CPU is quite high, and the rate is much lower for most of the peripherals. • The data is buffered in the I/O module and then sent to the peripheral device at its rate. 3/9/2024 Prepared Haftom B 178
- 179. Input/output Techniques (Data Transfer Mode) Three techniques are possible for I/O operations or data transfer mode. 1. Programmed I/O 2. Interrupt Driven 3. Direct Memory Access (DMA) 1. Programmed I/O Data are exchanged between the CPU and the I/O module. The CPU executes a program that gives it direct control of the I/O operation, including sensing device status, sending a read or write command and transferring data. When CPU issues a command to I/O module, it must wait until I/O operation is complete. If the CPU is faster than I/O module, there is wastage of CPU time. 3/9/2024 Prepared Haftom B 179
- 180. Input/output Techniques Cont.… The I/O module does not take any further action to alert CPU. That is, it doesn’t interrupt CPU. Hence it is the responsibility of the CPU to periodically check the status of the I/O module until it finds that the operation is complete. The sequences of actions that take place with programmed I/O are: 1) CPU requests I/O operation 2) I/O module performs operation 3) I/O module sets status bits 4) CPU checks status bits periodically 5) I/O module does not inform CPU directly 6) I/O module does not interrupt CPU 7) CPU may wait or come back later 3/9/2024 Prepared Haftom B 180
- 181. Input/output Techniques Cont.… I/O commands To execute an I/O related instruction, the CPU issues an address, specifying the particular I/O module and external device and an I/O command. Four types of I/O commands can be received by the I/O module when it is addressed by the CPU. They are: A control command: is used to activate a peripheral and tell what to do. Example: a magnetic tape may be directed to rewind or move forward a record. A test command: is used to test various status conditions associated with an I/O module and its peripherals. 3/9/2024 Prepared Haftom B 181
- 182. Input/output Techniques Cont.… The CPU wants to know the interested peripheral for use. It also wants to know the most recent I/O operation is completed and if any errors have occurred. A read command: it causes the I/O module to obtain an item of data from the peripheral and place it in an internal buffer. • The CPU then gets the data items by requesting I/O module to place it on the data bus. A write command: it causes the I/O module to take an item of data from the data bus and subsequently transmit the data item to the peripheral. 3/9/2024 Prepared Haftom B 182
- 183. I/O Mapping When the CPU, main memory, and I/O module share a common bus two modes of addressing. Memory mapped I/O Devices and memory share an address space I/O looks just like memory read/write No special commands for I/O Large selection of memory access commands available Isolated I/O Separate address spaces Need I/O or memory select lines Special commands for I/O and Limited set 3/9/2024 Prepared Haftom B 183
- 184. 2. Interrupt Driven I/O Using Program-controlled I/O requires continuous involvement of the processor in the I/O activities. It is desirable to avoid wasting processor execution time. An alternative is for the CPU to issue an I/O command to a module and then go on other work. The I/O module will then interrupt the CPU requesting service when it is ready to exchange data with the CPU. The CPU will then execute the data transfer and then resumes its former processing. Based on the use of interrupts, this technique improves the utilization of the processor. With Interrupt driven I/O, the CPU issues a command to I/O module and it does not wait until I/O operation is complete but instead continues to execute other instructions. When I/O module has completed its, work it interrupts the CPU. 3/9/2024 Prepared Haftom B 184
- 185. Interrupt Driven I/O Cont.… An interrupt is more than a simple mechanism for coordinating I/O transfers. In a general sense, interrupts enable transfer of control from one program to another to be initiated by an event that is external to a computer. Execution of the interrupted program resumes after completion of execution of the interrupt service routine. The concept of interrupts is useful in operating systems and in many control applications where processing of certain routines has to be accurately timed relative to the external events. 3/9/2024 Prepared Haftom B 185
- 186. Interrupt Driven I/O Cont.… Using Interrupt Driven I/O technique CPU issues read command. I/O module gets data from peripheral while CPU does other work and I/O module interrupts CPU checks the status if no error that is the device is ready then CPU requests data and I/O module transfers data. Thus CPU reads the data and stores it in the main memory. Basic concepts of an Interrupt An interrupt is an exception condition in a computer system caused by an event external to the CPU. Interrupts are commonly used in I/O operations by a device interface (or controller) to notify the CPU that it has completed an I/O operation. An interrupt is indicated by a signal sent by the device interface to the CPU via an interrupt request line (on an external bus). 3/9/2024 Prepared Haftom B 186
- 187. Interrupt Driven I/O Cont.… This signal notifies the CPU that the signalling interface needs to be serviced. The signal is held until the CPU acknowledges or otherwise services the interface from which the interrupt originated. Response of CPU to an Interrupt The CPU checks periodically to determine if an interrupt signal is pending. This check is usually done at the end of each instruction, although some modern machines allow for interrupts to be checked for several times during the execution of very long instructions. When the CPU detects an interrupt, it then saves its current state (at least the PC and the Processor Status Register containing condition codes); this state information is usually saved in memory. 3/9/2024 Prepared Haftom B 187
- 188. Interrupt Driven I/O Cont.… 3/9/2024 Prepared Haftom B 188 Figure 6.2: CPU Interrupts 3. Direct Memory Access (DMA) Interrupt driven and programmed I/O require active CPU intervention. Transfer rate is limited. CPU is tied up. DMA is the solution for these problems.
- 189. Direct Memory Access Cont.… Direct Memory Access is capabilities provided by some computer bus architectures that allow data to be sent directly from an attached device (such as a disk drive) to the memory on the computer’s motherboard. The microprocessor (CPU) is freed from involvement with the data transfer, thus speeding up overall computer operation. 3/9/2024 Prepared Haftom B 189 Figure 6.3: Direct Memory Access (DMA)
- 190. Direct Memory Access Processes When the CPU wishes to read or write a block of data, it issues a command to the DMA module and gives following information: CPU tells DMA controller: Whether to read or write Device address , Starting address of memory block for data Amount of data to be transferred The CPU carries on with other work. The DMA controller steals the CPU‟s work of I/O operation. The DMA module transfers the entire block of data, one word at a time, directly to or from memory, without going through CPU. 3/9/2024 Prepared Haftom B 190
- 191. Direct Memory Access process When the transfer is complete. DMA controller sends interrupt when finished. Thus CPU is involved only at the beginning and at the end of the transfer. 3/9/2024 Prepared Haftom B 191
- 192. DMA Configurations • The DMA mechanism can be configured in variety of ways. • 1. Single Bus Detached DMA: In this configuration all modules share the same system bus. The block diagram of single bus detached DMA is as shown below 3/9/2024 Prepared Haftom B 192
- 193. DMA Configuration Cont.… The DMA module that is mimicking the CPU uses the programmed I/O to exchange the data between the memory and the I/O module through the DMA module. This scheme may be inexpensive but is clearly inefficient. The features of this configuration are: Single Bus, Detached DMA controller Each transfer uses bus twice I/O to DMA then DMA to memory CPU is suspended twice Figure 6.5: Single Bus, integrated DMA 3/9/2024 Prepared Haftom B 193
- 194. DMA Configuration Cont.… 2. Single Bus, integrated DMA: Here, there is a path between DMA module and one or more I/O modules that do not include the system bus. The DMA logic can actually be considered as a part of an I/O module or there may be a separate module that controls one more I/O modules. 3/9/2024 Prepared Haftom B 194 Figure 6.5: Single Bus, integrated DMA
- 195. DMA Configuration Cont.… The features of this configuration can be considered as: Single Bus, Integrated DMA controller Controller may support >1 device Each transfer uses the bus once DMA to memory CPU is suspended once 3. DMA using an I/O bus: One further step of the concept of integrated DMA is to connect I/O modules to DMA controller using a separate bus called I/O bus. This reduces the number of I/O interfaces in the DMA module to one and provides for an easily expandable configuration. 3/9/2024 Prepared Haftom B 195
- 196. DMA Configuration Cont.… The block diagram of DMA using I/O bus is as shown in Figure 6.6. Here the system bus that the DMA shares with CPU and main memory is used by DMA module only to exchange data with memory. And the exchange of data between the DMA module and the I/O modules takes place off the system bus that is through the I/O bus. 3/9/2024 Prepared Haftom B 196 Figure 6. 6: DMA using an I/O bus
- 197. DMA Configuration Cont.… The features of this configuration are: Separate I/O Bus Bus supports all DMA enabled devices Each transfer uses bus once DMA to memory CPU is suspended once With both Programmed I/O and Interrupt driven I/O the CPU is responsible for extracting data from main memory for output and storing data in main memory for input. 3/9/2024 Prepared Haftom B 197
- 198. DMA Configuration Cont.… Table indicates the relationship among the three techniques. 3/9/2024 Prepared Haftom B 198
- 199. DMA Configuration Cont.… Advantages of DMA DMA has several advantages over polling and interrupts. DMA is fast because a dedicated piece of hardware transfers data from one computer location to another and only one or two bus read/write cycles are required per piece of data transferred In addition, DMA is usually required to achieve maximum data transfer speed, and thus is useful for high speed data acquisition devices. DMA also minimizes latency in servicing a data acquisition device because the dedicated hardware responds more quickly than interrupts and transfer time is short. Minimizing latency reduces the amount of temporary storage (memory) required on an I/O device. 3/9/2024 Prepared Haftom B 199
- 200. Advantages of DMA • DMA is fast because a dedicated piece of hardware transfers data from one computer location to another and only one or two bus read/write cycles are required per piece of data transferred • DMA is usually required to achieve maximum data transfer speed, and thus is useful for high speed data acquisition devices. • which means the processor does not have to execute any instructions to transfer data. 3/9/2024 Prepared Haftom B 200
- 201. End of Chapter 8 Thanks!!! ??? 3/9/2024 Prepared Haftom B 201
- 202. Pipeline and Vector Processing 09/03/2024 Chapter 9
- 203. CONTENTS 1. Pipeline 2. Parallel Processing 3. Arithmetic Pipeline 4. Instruction Pipeline 5. Vector Processing 6. Array Processing 09/03/2024 203
- 204. PIPELINE Pipelining is the process of accumulating instruction from the processor through a pipeline. It allows storing and executing instructions in an orderly process. It is also known as pipeline processing. Pipelining is a technique where multiple instructions are overlapped during execution. Pipeline is divided into stages and these stages are connected with one another to form a pipe like structure. Instructions enter from one end and exit from another end. Pipelining increases the overall instruction throughput. 09/03/2024 204
- 205. TYPES OF PIPELINE It is divided into 2 categories: Arithmetic Pipeline Instruction Pipeline 09/03/2024 205
- 206. ARITHMETIC PIPELINE Arithmetic pipelines are usually found in most of the computers. They are used for floating point operations multiplication of fixed point numbers etc. 09/03/2024 206
- 207. CONT.. The floating point addition and subtraction is done in 4 parts: 1.Compare the exponents. 2.Align the mantissas. 3.Add or subtract mantissas 4.Produce the result. 09/03/2024 207
- 208. EXAMPLE X = A x 10a = 0.9504 x 103 Y = B x 10b = 0.8200 x 102 1) Compare exponents : 3 - 2 = 1 2) Align mantissas X = 0.9504 x 103 Y = 0.08200 x 103 3) Add mantissas Z = 1.0324 x 103 4) Normalize result Z = 0.10324 x 104 09/03/2024 208
- 209. INSTRUCTION PIPELINE Pipeline processing can occur also in the instruction stream. An instruction pipeline reads consecutive instructions from memory while previous instructions are being executed in other segments. Fetch an instruction from memory [1] Fetch an instruction from memory [2] Decode the instruction [3] Calculate the effective address of the operand [4] Fetch the operands from memory [5] Execute the operation [6] Store the result in the proper place 09/03/2024 209
- 210. PARALLEL PROCESSING Parallel computing is a type of computing architecture in which several processors simultaneously execute multiple, smaller calculations broken down from an overall larger, complex problem. 09/03/2024 210
- 211. CONT.. Parallel computing refers to the process of breaking down larger problems into smaller, independent, often similar parts that can be executed simultaneously by multiple processors communicating via shared memory, the results of which are combined upon completion as part of an overall algorithm. The primary goal of parallel computing is to increase available computation power for faster application processing and problem solving. 09/03/2024 211
- 212. VECTOR PROCESSING There is a class of computational problems that are beyond the capabilities of a conventional computer. These problems require a vast number of computations that will take a conventional computer days or even weeks to complete. Vector Processor (computer) Ability to process vectors, and matrices much faster than conventional computers 09/03/2024 212
- 213. VECTOR PROCESSING APPLICATIONS Problems that can be efficiently formulated in terms of vectors and matrices Long-range weather forecasting Seismic data analysis Petroleum explorations Medical diagnosis Aerodynamics and space flight simulations Artificial intelligence and expert systems Mapping the human genome Image processing 09/03/2024 213
- 214. TYPES OF PARALLEL PROCESSING Single instruction stream, single data stream – SISD Single instruction stream, multiple data stream – SIMD Multiple instruction stream, single data stream – MISD Multiple instruction stream, multiple data stream – MIMD 09/03/2024 214
- 215. CONT.. SISD Instructions are executed sequentially. Parallel processing may be achieved by means of multiple functional units or by pipeline processing SIMD – Includes multiple processing units with a single control unit. All processors receive the same instruction, but operate on different data. MISD-- The same data stream flows through a linear array of processors executing different instruction streams. MIMD – A computer system capable of processing several programs at the same time. We will consider parallel processing under the following main topics: 09/03/2024 215
- 216. 09/03/2024 Ch- 10
- 217. CONTENTS Multiprocessor Multiprocessor and its Characteristics 09/03/2024 217
- 218. MULTIPROCESSOR A multiprocessor is a computer system with two or more central processing units (CPUs), with each one sharing the common main memory as well as the peripherals. This helps in simultaneous processing of programs. The key objective of using a multiprocessor is to boost the system’s execution speed, with other objectives being fault tolerance and application matching. 09/03/2024 218
- 219. BENEFITS OF MULTIPROCESSOR •Enhanced performance •Multiple applications •Multiple users •Multi-tasking inside an application •High throughput and/or responsiveness •Hardware sharing among CPUs 09/03/2024 219
- 221. 09/03/2024 221
- 222. 09/03/2024 ኣለቀ