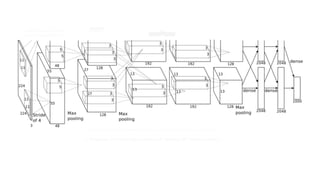
CNN-AlexNet-ResNet presentation describing their architectures
2.
Convolutional Neural Networks(CNNs) had always
been the go-to model for object recognition
• They’re strong models that are easy to control and even
easier to train.
• They don’t experience overfitting at any alarming scales
when being used on millions of images.
• The only problem: they’re hard to apply to high resolution
images.
3.
AlexNet
• The architectureconsists of eight layers: five convolutional layers and
three fully-connected layers.
• ReLU Nonlinearity. AlexNet uses Rectified Linear Units (ReLU)
instead of the tanh function, which was standard at the time. ReLU’s
advantage is in training time; a CNN using ReLU was able to reach a
25% error on the CIFAR-10 dataset six times faster than a CNN using
tanh.
• Overlapping Pooling. CNNs traditionally “pool” outputs of
neighboring groups of neurons with no overlapping.
However, when the authors introduced overlap, they saw a reduction
in error by about 0.5% and found that models with overlapping
pooling generally find it harder to overfit.
5.
The Overfitting Problem.AlexNet had 60 million parameters, a major issue in terms
of overfitting. Two methods were employed to reduce overfitting:
•Data Augmentation. The authors used label-preserving transformation to make their
data more varied. Specifically, they generated image translations and horizontal
reflections, which increased the training set by a factor of 2048. They also performed
Principle Component Analysis (PCA) on the RGB pixel values to change the intensities of
RGB channels, which reduced the top-1 error rate by more than 1%.
•Dropout. This technique consists of “turning off” neurons with a predetermined
probability (e.g. 50%). This means that every iteration uses a different sample of the
model’s parameters, which forces each neuron to have more robust features that can be
used with other random neurons. However, dropout also increases the training time
needed for the model’s convergence.
What Now? AlexNet is an incredibly powerful model capable of achieving high accuracies
on very challenging datasets. However, removing any of the convolutional layers will
drastically degrade AlexNet’s performance. AlexNet is a leading architecture for any
object-detection task and may have huge applications in the computer vision sector of
artificial intelligence problems. In the future, AlexNet may be adopted more than CNNs
for image tasks.
8.
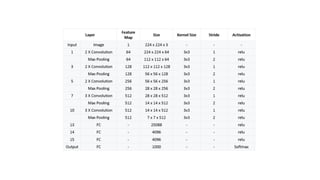
VGGNet Architecture
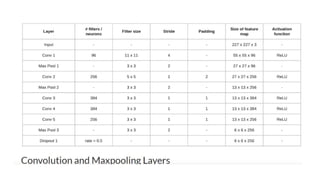
There aretotal of 13 convolutional layers and 3 fully connected layers in VGG16 architecture.
VGG has smaller filters (3*3) with more depth instead of having large filters. It has ended up
having the same effective receptive field as if you only have one 7 x 7 convolutional layers.
Another variation of VGGNet has 19 weight layers consisting of 16 convolutional layers with 3
fully connected layers and same 5 pooling layers. In both variation of VGGNet there consists
of two Fully Connected layers with 4096 channels each which is followed by another fully
connected layer with 1000 channels to predict 1000 labels. Last fully connected layer uses
softmax layer for classification purpose.
9.
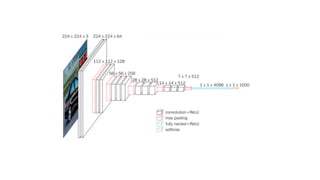
Architecture walkthrough:
•The firsttwo layers are convolutional layers with 3*3 filters, and first two
layers use 64 filters that results in 224*224*64 volume as same
convolutions are used. The filters are always 3*3 with stride of 1
•After this, pooling layer was used with max-pool of 2*2 size and stride 2
which reduces height and width of a volume from 224*224*64 to
112*112*64.
•This is followed by 2 more convolution layers with 128 filters. This results
in the new dimension of 112*112*128.
•After pooling layer is used, volume is reduced to 56*56*128.
•Two more convolution layers are added with 256 filters each followed by
down sampling layer that reduces the size to 28*28*256.
•Two more stack each with 3 convolution layer is separated by a max-pool
layer.
•After the final pooling layer, 7*7*512 volume is flattened into Fully
Connected (FC) layer with 4096 channels and softmax output of 1000
classes.