1) The document discusses using a cluster of computers to analyze and classify massive biomedical image data more efficiently.
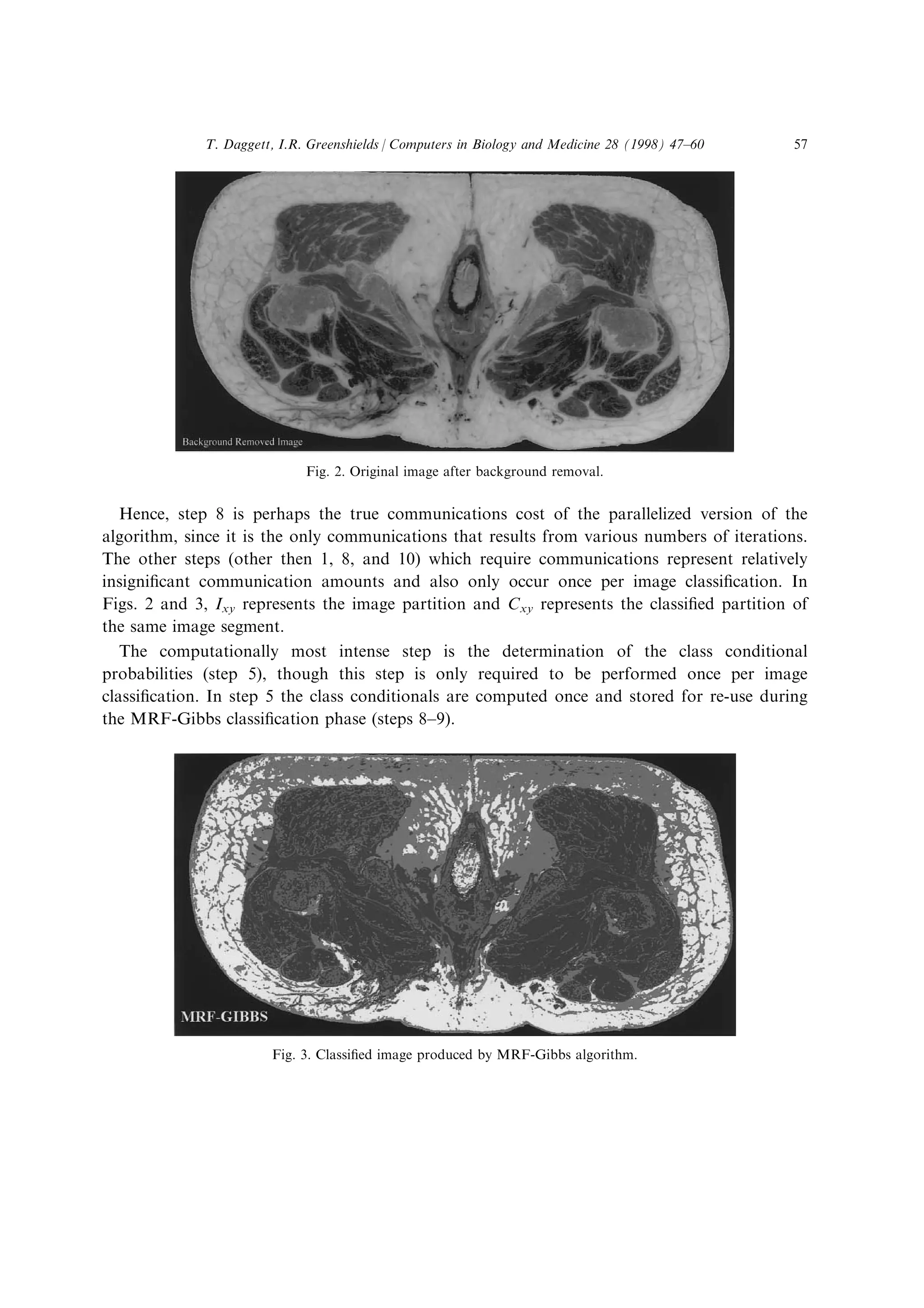
2) It describes parallelizing an MRF-Gibbs classification algorithm across the cluster to segment and classify images from the Visible Human Project dataset, which contains high resolution 3D imagery totalling over 4200 MB.
3) The cluster is made up of 8 PC workstations connected by an ATM switch and Ethernet, and supports two programming interfaces (MPI and Paradise) to implement parallel algorithms for improved processing throughput of the large image datasets.

![algorithm can execute in parallel acting on di€erent subdivisions of the image. Thus,
discounting typical parallel overheads, many imaging algorithms are in principle amenable to
the p-speedup when distributed over p processors. (Many image algorithms are, of course, not
so amenable.) It is therefore often the case that the issue impacting the processing throughput
of massive images lies not in complex algorithm design, but in platform availability. It will
sometimes be true that a large parallel system's costs can be folded into the cost of the imager
itself without apparent impact on total system cost (as might be the case with a modern MR
imager), but the average biological or medical laboratory interested in analysing these images is
unlikely to wish to acquire a large parallel system, both because of cost and system
management problems. However, even the most modest laboratories will have access to
inexpensive PC-level workstations, and it has now become a trend in parallel system design to
exploit groups of these systems networked together to form what is known as a cluster
computer. Cluster computers, unlike the more expensive symmetric multiprocessors which
characterize the bulk of non-cluster parallel systems are inexpensive to assemble, easy to
maintain, extremely fault-tolerant (in the sense that the failure of a cluster component Ða
workstationÐ simply means that the cluster has less processing power than it had before),
surprisingly powerful (a tribute to the modem microprocessor) and (with newer application
programming interfaces) relatively easy to program. Clusters can be quite small yet still
powerful; the architecture we describe below consists of 8 Pentium systems capable of a
(theoretical) throughput SpecFP of about 245 [1].
The principal software component for application development on parallel systems is the
underlying communication mechanism used for inter-process communications. There are a
number of di€erent software communication paradigms that have received signi®cant attention.
Of these, the message passing interface (MPI) has been much heralded as the future standard
for message passing based communications [2, 3]. A very di€erent and less well known
technique for inter-process communications is virtual shared memory. Virtual shared memory
allows processes to communicate by directly sharing data as if it existed in a global shared
memory space. Processes can access (read or write) information in the memory space without
concern or knowledge of external processes, and can therefore be developed in a more
sequential program fashion [4]. This conceptually simpler view supports the main advantage
usually associated with virtual shared memory, which is that the application programming
interface is usually quite simple and therefore the complexity of developing parallel
applications is greatly reduced. Paradise (Scienti®c Computing, New Haven, CT) is a widely
used virtual shared memory based communications package that o€ers a very simple API.
The particular problem we address involves the derivation of quantitative anatomical
parameters (such as tissue volume by type etc.) from the visible human dataset [5]. Our medical
imaging goal is to segment (by automatic image classi®cation) the anatomical images of the
visible human dataset so that quantitative anatomical issues and computational geometric
models can be constructed from the dataset. In reference to earlier work from MR images [6, 7]
we have elected to use the visible human dataset to extract out and model the bladder and
urethra. Both because it is anatomically simpler and because the dataset is homogeneous in x,
y, and z resolution (0.33 mm per pixel), we are working with the newer visible female dataset.
Even in the small anatomical region of interest we are examining, the dataset is huge: each raw
image (2048 Â 1216 Â 3) exceeds 7 MB. The pelvic imagery alone (from the base of the sacrum
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±6048](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-2-2048.jpg)
![to about the linea terminalis on the sacral promontory) occupies about 4200 MB. The
algorithmic strategy involves image preprocessing (to remove background and non-anatomical
image details) followed by an unsupervised context-dependent classi®cation of the RGB images
using a Gibbs classi®er (described below).
Automatic image classi®cation, though dicult, is not a new problem and numerous
algorithms have been developed for other problem domains which may aid in the classi®cation
process [8]. These algorithms can be grouped into two principal categories: context-dependent
and context-independent. Context-independent algorithms perform an image classi®cation
based directly on a pixel's intensity and the distribution of the intensity values of an image. In
simpler terms they attempt to classify the pixel purely from its intensity with respect to the rest
of the pixel intensi®es of the image. Context-independent algorithms classify the pixel values of
a random image (one where pixels are randomly scattered) identically to the pixels of an image
that contains well de®ned regions (typical digital image), as long as the images have identical
intensity distributions. Well known examples of context-independent algorithms include the
nearest mean, maximum likelihood estimation and K nearest neighbors methods [8]. In
comparison to context-independent algorithms, context-dependent approaches attempt to
utilize relationships, or contextual information, between pixels within an image to perform a
classi®cation. An important and popular example from the context-dependent category is the
MRF-Gibbs algorithm [9, 10].
The MRF-Gibbs classi®cation method utilizes contextual information derived from the
relationship that a point (pixel) in an image has with the neighborhood (spatially close pixels)
that encompasses it. This relationship is assumed to exhibit the characteristics of a Markov
random ®eld (MRF), in which the neighboring pixels can be e€ectively used to classify the
pixel. The Gibbs component of the MRF-Gibbs classi®cation method stems from the
evaluation of this relationship in terms of an energy function. This energy function can be used
to produce the ideal image classi®cation through the maximization of the energy function at
each pixel of the image. However, the determination of the ideal classi®cation requires that
every possible combination of pixel classi®cations of an image be examined. Therefore an n  n
image with L possible classes contained within would require Ln  n
combinations to be
evaluated. This evaluation is considered computationally intractable and hence is considered
not plausible for practical sized images. To address this processing limitation, the
determination of the ideal classi®cation can be approximated through the employment of
stochastic maximization techniques, such as simulated annealing, to reduce the computational
burden of the MRF-Gibbs algorithm. Theoretically, the MRF-Gibbs classi®er iterates
hundreds (or even thousands) of times over each image, repeatedly computing energy functions
and probability distributions, so that the computational demands are enormous.
Faced with this challenge, we elected to construct a cluster computer comprising 8 PC
platforms (Pentium 166 MHz systems, 32 MB running Microsoft Windows NT). The machines
are connected both by a 25 Mbs ATM switch and 10 Mbs Ethernet, and (as we describe
below) support two distinct application programming interfaces (MPI and Paradise) for the
implementations of parallel algorithms. In the sections that follow we describe the
parallelization of the MRF-Gibbs algorithm in conjunction with simulated annealing, by ®rst
identifying the basic operational concepts of the algorithm and then de®ning how it was
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±60 49](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-3-2048.jpg)
![parallelized on the cluster. The speedup of the parallelized algorithm using both MPI and
Paradise based communications over a serial version is presented.
2. MRF-Gibbs
In the core of the MRF-Gibbs algorithm lies the Markov random ®eld (MRF) assumption.
The MRF assumption states that the true interpretation of any pixel Xij given the true
interpretation of all image pixels G depends only on the interpretation of its neighboring pixels
in a neighborhood Nij (Eq. (1)).
P…Xij ˆ okjG † ˆ P…Xij ˆ okjNij † …1†
This interpretation of a pixel can be used for the assignment, or classi®cation of a pixel to a
class ok, which represents a labeling of the pixel from a given set of L possible classes. These
classes may correspond to tissue types believed to be contained in the image (muscle tissue,
bone, etc.).
A neighborhood Nij consists of those pixels that fall into a de®ned region surrounding the
pixel at location (ij). Various shaped neighborhoods can be used, and their shapes (sizes) are
usually determined from the underlying characteristics present in the regions, or structures of
an image. A very commonly employed and simple neighborhood system may be de®ned as
consisting of those pixels which are within a particular Euclidean distance from the pixel Xij.
Typically the relationship between neighboring points diminishes greatly with increasing
distance. It has been shown [9, 10] that a meaningful neighborhood may in fact be quite small,
and can be de®ned as consisting of those neighbors, which are a Euclidean distance (d) of one
from the pixel in question. Thus
Nij ˆ f…r,s†:d……r,s†,…ij†† ˆ 1g …2†
de®nes a four-element neighborhood, consisting of the east, west, north and south adjacent
pixels about the site (ij), and it is this simple but e€ective structure that we use.
With this concept of a four-pixel neighborhood, the assignment of pixel Xij to a class ok can
be evaluated in terms of the posterior probability P(okvXij,Q), the conditional probability that
the assignment of class ok is correct given observation Xij and prior information Q. The prior
information Q consists of the pixel's neighborhood Nij, global information such as the class
probability of the various classes occurring naturally in the image P(ok), and local information
de®ning the likelihood of the contents of the neighborhood. In simple terms, the probability of
class ok, being assigned to site (ij) depends only upon the observations contained in its
neighborhood Nij, Eq. (3).
P…okjXij,Q† ˆ
‰
…xy†PNij
P…okjXxy,Q† …3†
In Eq. (3), Xxy represents an observation contained in the neighborhood Nij. From a
Bayesian perspective, the best classi®cation for Xij is the class ok that maximizes Eq. (4).
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±6050](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-4-2048.jpg)
![‰
…xy†PNij
P…ok†P…Xxyjok†r
‰
…xy†PNij
P…oh†P…Xxyjoh†, Vh Tˆ k …4†
The decision rule, de®ned above, involves maximizing the probability of the classi®cation of
an entire neighborhood. The MRF-Gibbs equivalence shows that Eq. (4) can be written in a
Gibbsian form P(Xij,ok),
P…Xij,ok† ˆ
1
Z
eÀU…Xij,ok†aT
…5†
U…Xij,ok† ˆ À
ˆ
…x,y†PNij
log P…Xxyjok† ‡ U…ok† …6†
and that this Gibbsian equivalent can be evaluated using an energy function, U(Xij,ok) used
here, a normalizing constant Z, and an arti®cial temperature T. Proof of the equivalence
between the Gibbs and MRF representations is given in Refs. [9, 10]. The MRF-Gibbs
classi®cation process therefore consists of assigning the pixels of an image those class values
that produce a maximum posterior distribution when the energy is minimized. The description
above has concentrated on the local expression of the MRF-Gibbs model for classi®cation.
Evidently, energy minimization cannot proceed on a purely local basis; instead, we consider the
maximum a posteriori (MAP) estimate of the image's class structure as follows. Suppose there
are L classes in an n  n image. A con®guration z $ C is an enumeration of the classes
attached to each point of the image. In the case described, cardinality card{C} = Ln  n
. Let W
be the (random) observation of a con®guration, and let X be the (random) observation of the
image data; then the MAP estimate is the estimate [8, 9].
WMAP ˆ arg maxzPCfP…W ˆ zjX ˆ x†g …7†
However, the assignment of the pixels cannot be performed pixel by pixel but instead
represents a dynamic programming problem.
One can employ simulated annealing to migrate towards an approximate solution to this
maximization problem. Simulated annealing is an iterative optimization technique which
attempts to minimize an energy function through random excitation [11]. It can be utilized to
reduce the overall computation of locating an ``ideal'' classi®cation to a more reasonable
amount. Here ``ideal'' now refers to an approximate solution to the classi®cation problem,
which may or may not be the true classi®cation solution. Typically, the procedure terminates
after a ®xed number of iterations of the annealing process.
In the MRF-Gibbs classi®cation approach, simulated annealing functions by periodically re-
classifying a pixel to a ``worst'' classi®cation, i.e. a classi®cation that actually produces a higher
energy potential. It is this occasional acceptance of a ``worst'' classi®cation that allows the
algorithm to jump out of a local minimum in search of a global minimum, consequently
producing an improved classi®ed image. The decision rule for the acceptance of a ``worst''
classi®cation is governed by a temperature and a cooling schedule.
Numerous cooling schedules have been developed for simulated annealing [11], however it
appears that the best schedule is usually determined through ad hoc trial and error. In our
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±60 51](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-5-2048.jpg)
![case, a cooling schedule T(t), (Eq. (8))
T…t† ˆ
T0
log…t ‡ 1†
…8†
where T0 is the initial temperature is employed [12]. The initial temperature T0 was determined
from the ®rst iteration of the algorithm, which evaluated the image by summing the total
energy encountered (increase in energy) during an attempted classi®cation of the pixels to a
new classi®cation with higher energy. The gradual cooling of the temperature produced by the
schedule ideally allows the algorithm to settle in the global minimum.
With the employment of simulated annealing to ®nd the minimal energy produced by Eq. (6),
the remaining complexity of the MRF-Gibbs approach involves determining a useful energy
function. The derivation of an energy function typically involves understanding the nature of
the image, identifying a meaningful neighborhood shape (and size), and describing the unique
attributes of the image regions, or structures. Numerous models have been developed to
describe these di€ering attributes in terms of relationships of the pixels of the neighborhoods,
contained in the regions or structures. As result, many di€erent energy functions have been
developed which attempt to evaluate the likelihood or quality of a neighborhood relative to a
set of attribute quali®ers [10]. For our energy function,
U…Xij,ok† ˆ À
ˆ
…x,y†PNij
log P…Xxyjok† ‡
ˆ
…x,y†PNij
log P…o…x,y††
‡
ˆ
…x,y†PNij
log P…x,y†,…x‡1,y†…o…x,y†,o…x‡1,y†† ‡
ˆ
…x,y†PNij
log P…x,y†,…x,y‡1†…o…x,y†,o…x,y‡1†† …9†
we utilized the conditional probability of each neighbor in Nij given the class ok, the
probability of the classi®cations of neighbors, and the transitional probabilities associated with
the spatial con®guration of the neighborhood [13]. This spatial likelihood encompasses both
the horizontal and vertical transitions of the neighborhood. Since our neighborhood consisted
of the four-pixel stencil mentioned earlier, the horizontal relationship consisted of evaluating
the transitional probability of the west pixel to pixel Xij and Xij to the east pixel. Likewise the
vertical relationship consisted of the vertical transitional probability of the north pixel to Xij
and Xij to the south pixel. It should be noted that a transitional probability of ok to oj is the
likelihood, or probability, that ok, is followed by oj in the direction of the transition type.
Simulated annealing is employed in conjunction with Eq. (9), as de®ned by the following
series of steps.
1. Randomly select a new class for the pixel xij.
2. Evaluate the new classi®cation in terms of the neighborhood relationships and the
likelihood of the neighborhood via the energy function (Eq. (9)), DU.
3. If the re-classi®cation produces a lower energy then the current classi®cation then accept it.
4. Else accept it conditionally based upon an annealing schedule derived probability Ai>r.
The probability Ai,
Ai ˆ eÀDUaT…t†
…10†
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±6052](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-6-2048.jpg)






![delineation of the Paradise Software for the duration of the project and Dr Michael J.
Ackerman, Visible Human Project, National Library of Medicine for providing the Visible
Human Female dataset.
References
[1] SPECfp_rate95, Spec Benchmarks, http://open.specbench.org/osg/cpu95/results/rfp95.html.
[2] Snir, M., Otto, S., Huss-Lederman, S., Walker, D. and Dongarra, J., MPI The Complete Reference. MIT Press,
Cambridge, MA, 1996.
[3] Gropp, W., Lusk, E. and Skjellum, A., Using MPI Portable Parallel Programming with the Message-Passing
Interface. MIT Press, Cambridge, MA, 1996.
[4] Amza, C. and Cox, A., TreadMarks: shared memory computing on networks of workstations, IEEE Computer,
February, 1996, 18±28.
[5] Visible Human Dataset, National Library of Medicine, National Institutes of Health, Bethesda, MD.
[6] Greenshields, I. R. and Chun, J., Simulation of ¯uid ¯ow through biological inhomogeneous elastic tubes,
Proc. of IASTED Int. Conference on Modeling and Simulation, Pittsburgh, PA, 1993, pp. 66±68.
[7] Greenshields, I. R., Peters, T. J. and Chun, J., Parallel strategies in the reconstruction of surfaces from contour
data, Proc. of 4th ISMM Conf. on Parallel and Distributed Computing Systems, 1991, pp. 355±358.
[8] Fukunaga, K., Statistical Pattern Recognition, 2nd edition. Academic Press, San Diego, CA, 1990.
[9] Li, S. Z., Markov Random Field Modeling in Computer Vision. Springer, Berlin, 1995.
[10] Winkler, G., Image Analysis, Random Fields and Dynamic Monte Carlo Methods. Springer, Berlin, 1991.
[11] L. Ingber, Simulated annealing: practice versus theory, Mathematical and Computer Modeling 18 (11) (1993)
29±57.
[12] Geman, S. and Gemen, D., Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images,
IEEE Trans. on Pattern Analysis and Machine Intelligence, 1984, PAMI-8(6), 721±741.
[13] Zhu, J. and Greenshields, I., Classi®cation of multiecho magnetic resonance images of brain using MRG-Gibbs
classi®er, Department of Computer Science and Engineering, University of Connecticut, Storrs, CT, 1993.
Thomas A. Daggett is a Ph.D. candidate at the University of Connecticut. He received a BSE in computer
engineering from the University of Connecticut in 1985 and his MS in computer science from Rennselaer
Polytechnic Institute in 1989. He is currently serving as an operability and display engineer in the Advanced Display
Research Facility (ADRF) at the Naval Undersea Warfare Center (NUWC) division Newport, Newport Rhode
Island. His research interests lie in parallel/distributed processing, image processing, small-scale cluster computing,
and advanced display technologies.
Ian Greenshields is an Associate Professor of Computer Science and Engineering at the University of Connecticut.
His research interests lie in the areas of biomedical computing, biomedical image processing and biodynamical
modeling.
T. Daggett, I.R. Greenshields / Computers in Biology and Medicine 28 (1998) 47±6060](https://image.slidesharecdn.com/2f5df4ea-6a66-45ce-8412-be7ee6815270-151102192130-lva1-app6892/75/ClusterPaperDaggett-14-2048.jpg)













































