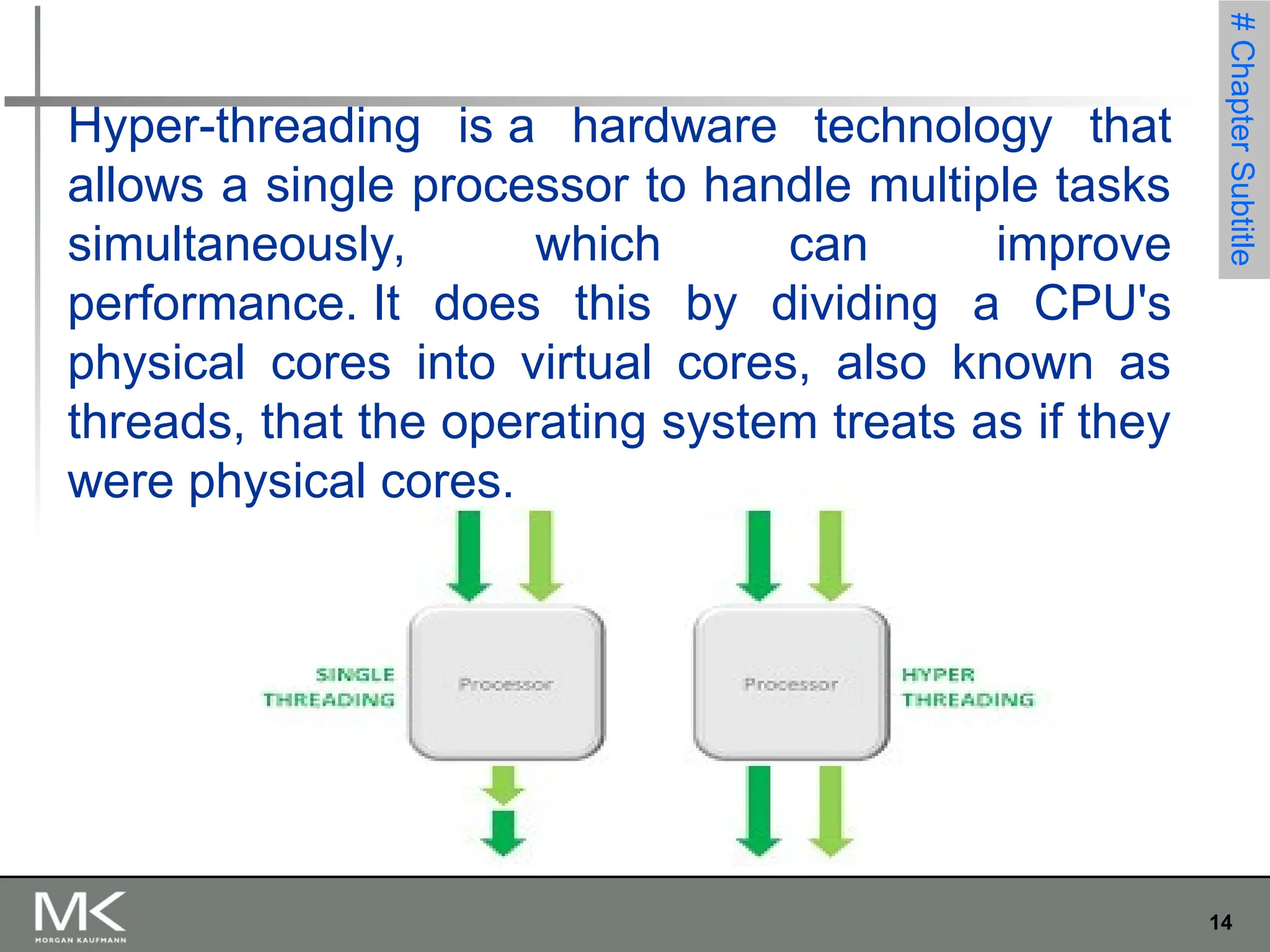
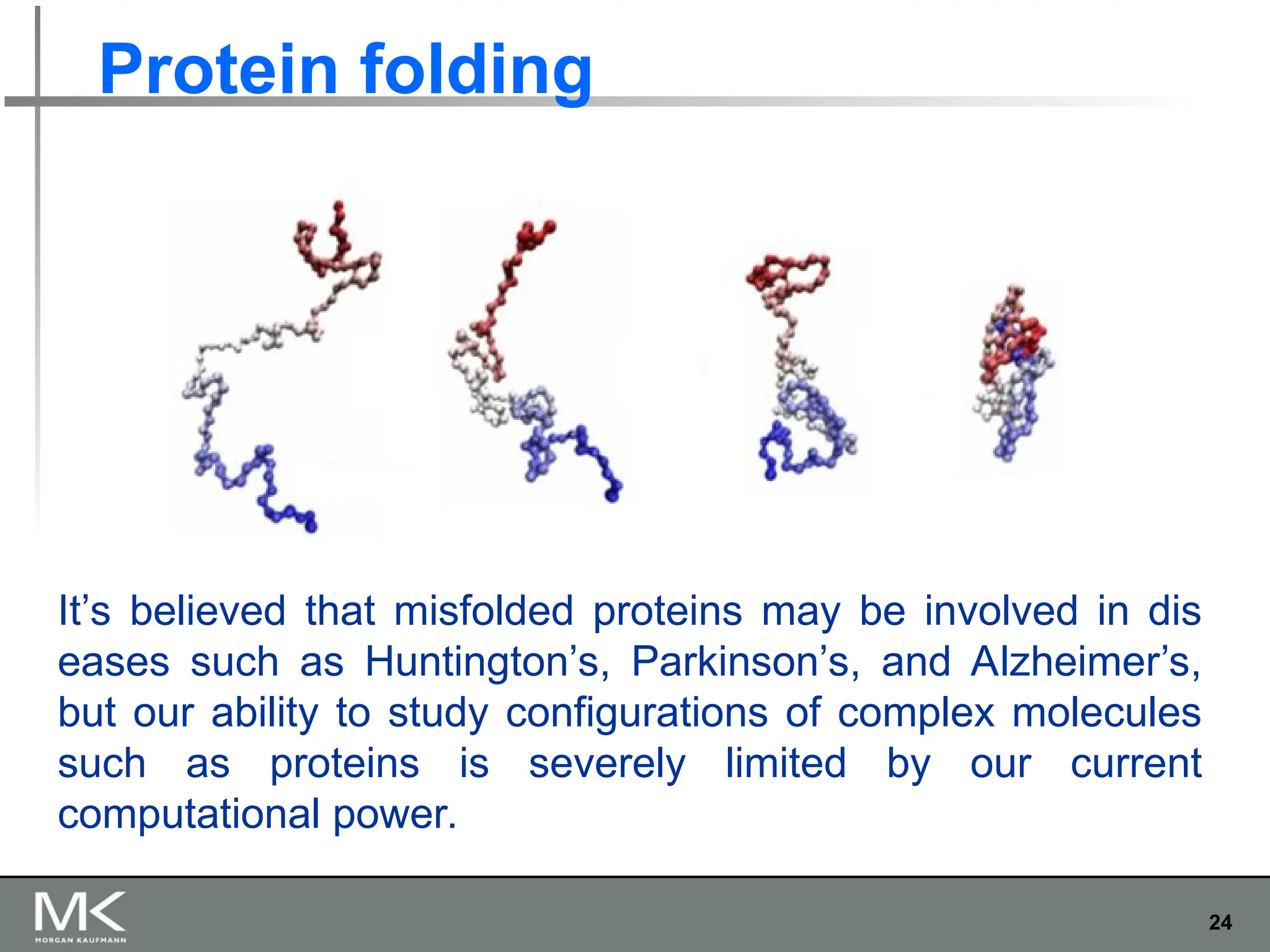
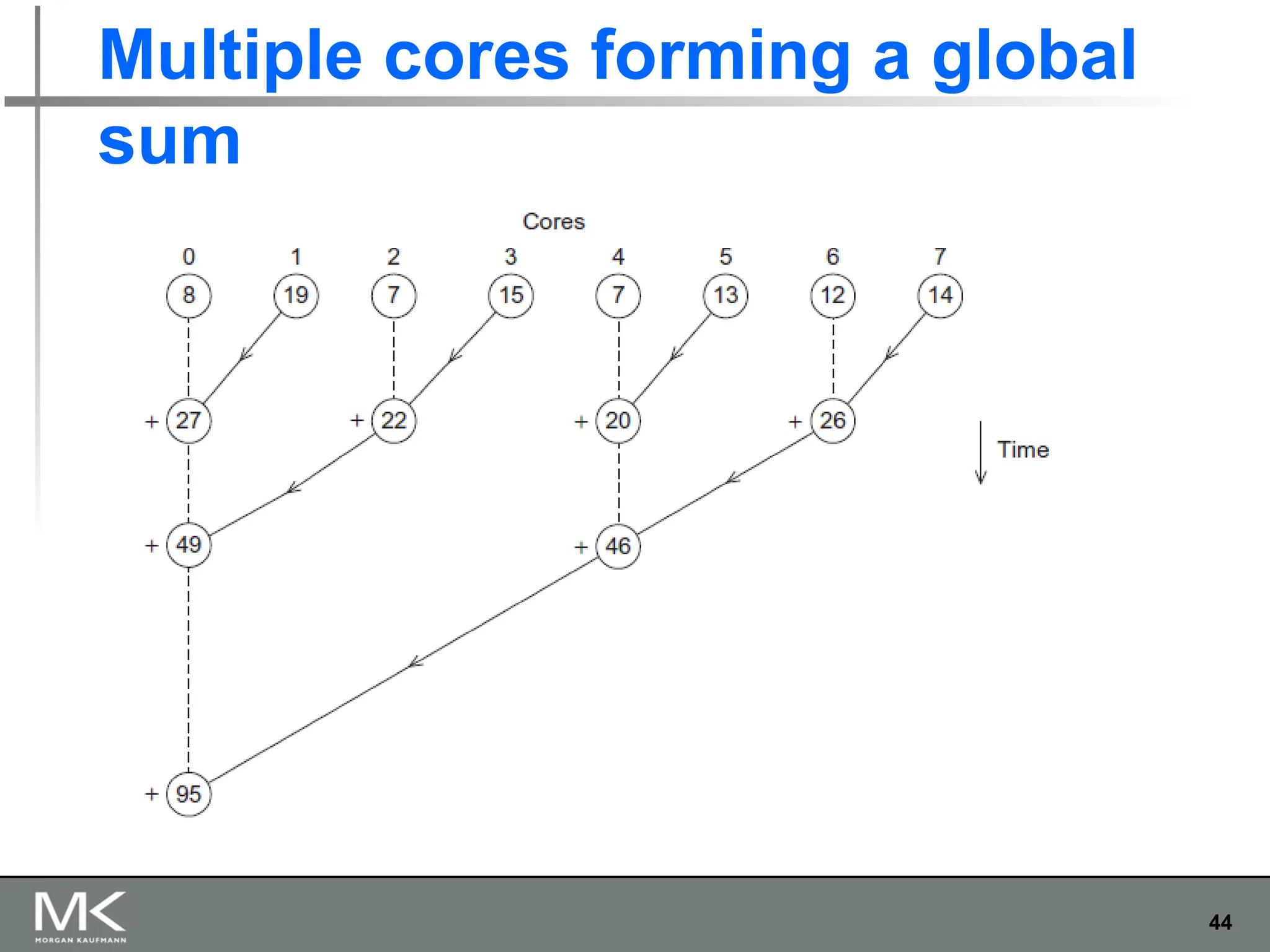
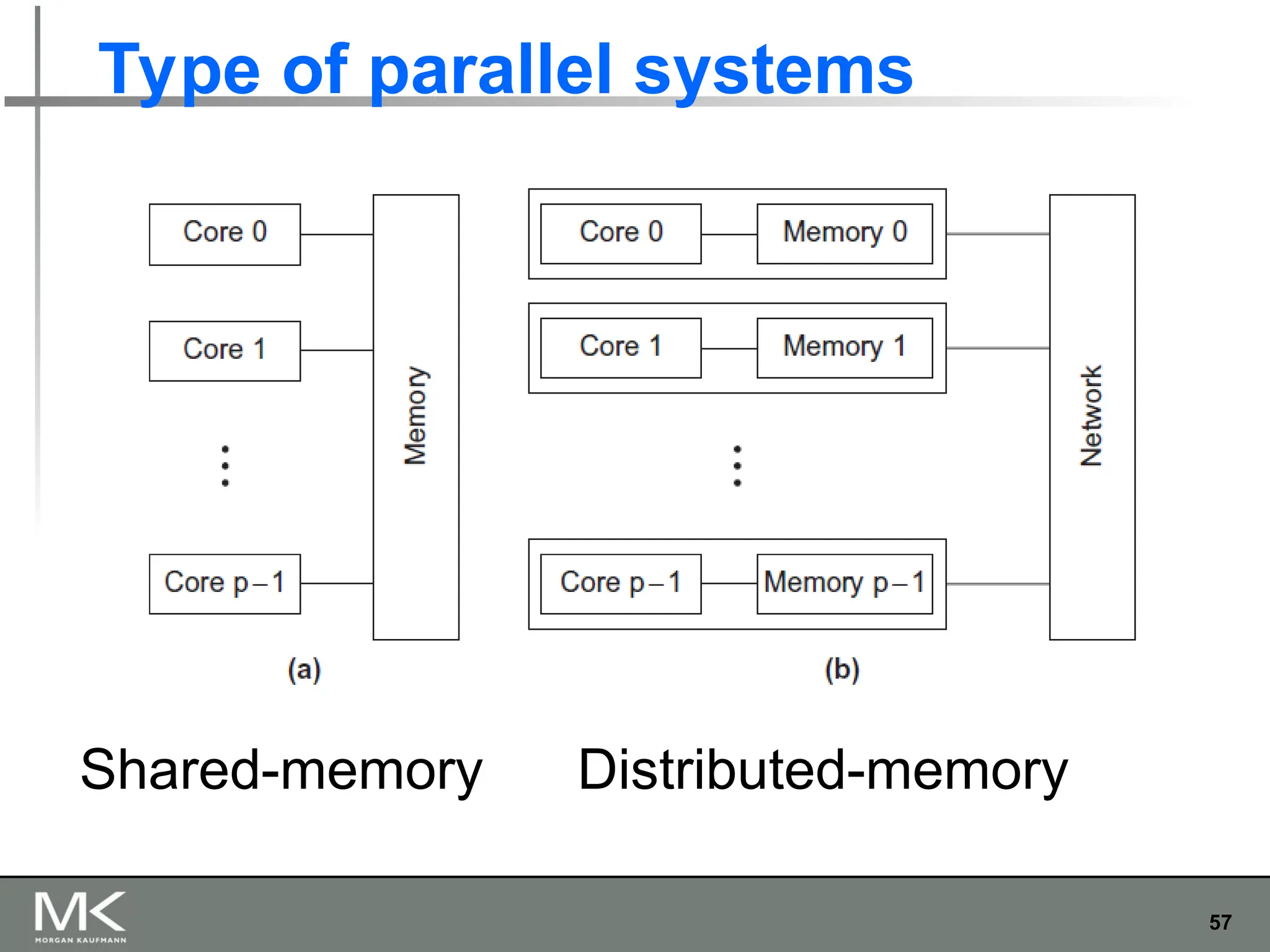
The document provides an extensive overview of parallel computing and processing, highlighting definitions, scopes, and applications while differentiating between CPUs and GPUs in this context. It also discusses the importance of parallelism in programming, the transition from single-core to multi-core systems, and various methods for writing parallel programs. Additionally, it touches on the benefits of using parallel APIs and the necessity for coordination and synchronization among cores.