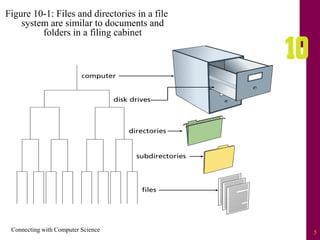
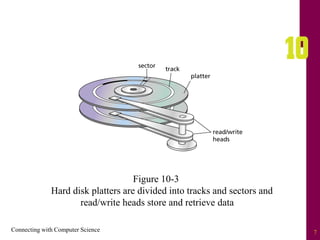
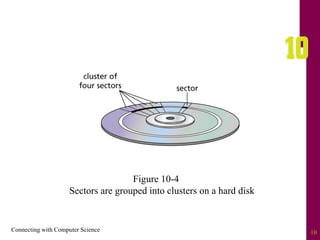
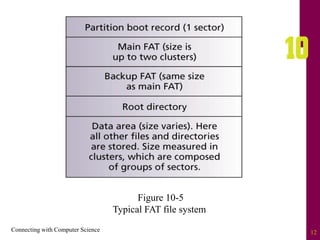
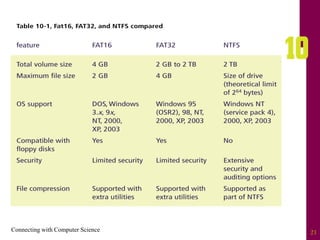
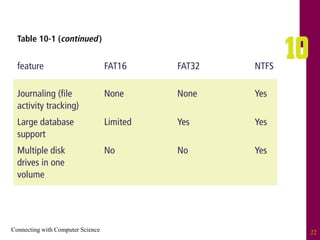
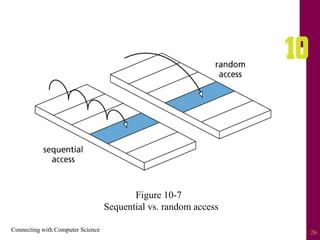
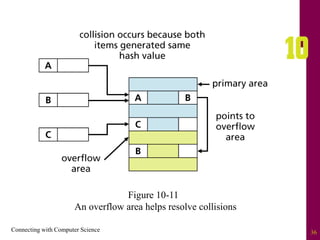
The document discusses file systems and file organization. It compares the FAT and NTFS file systems, describing their advantages and disadvantages. FAT groups hard drive sectors into clusters and uses a file allocation table to track files. NTFS overcomes FAT limitations with features like security and crash recovery. The document also describes sequential and random access of files, how hashing converts keys into indexes to allow random access, and how hashing algorithms deal with collisions.