Download to read offline





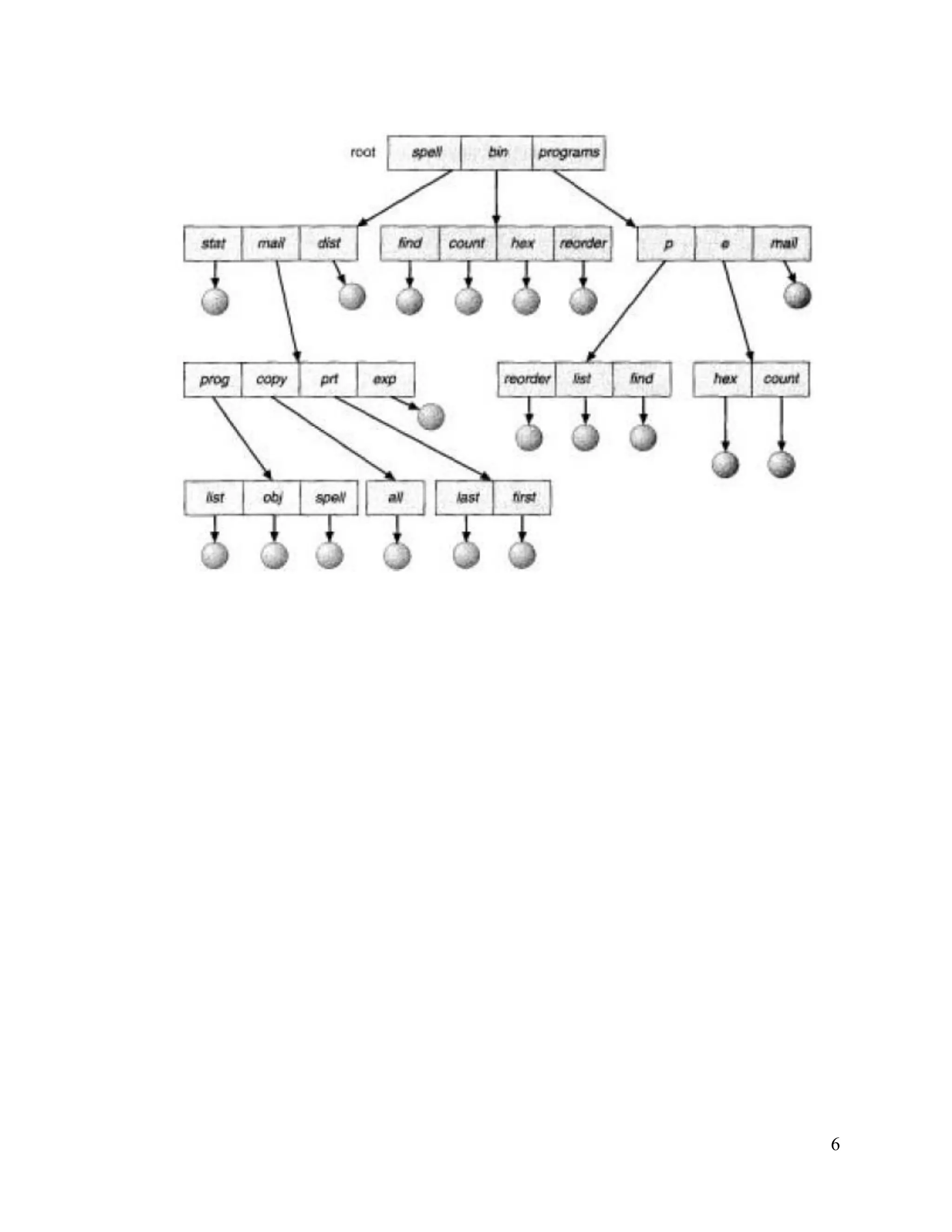

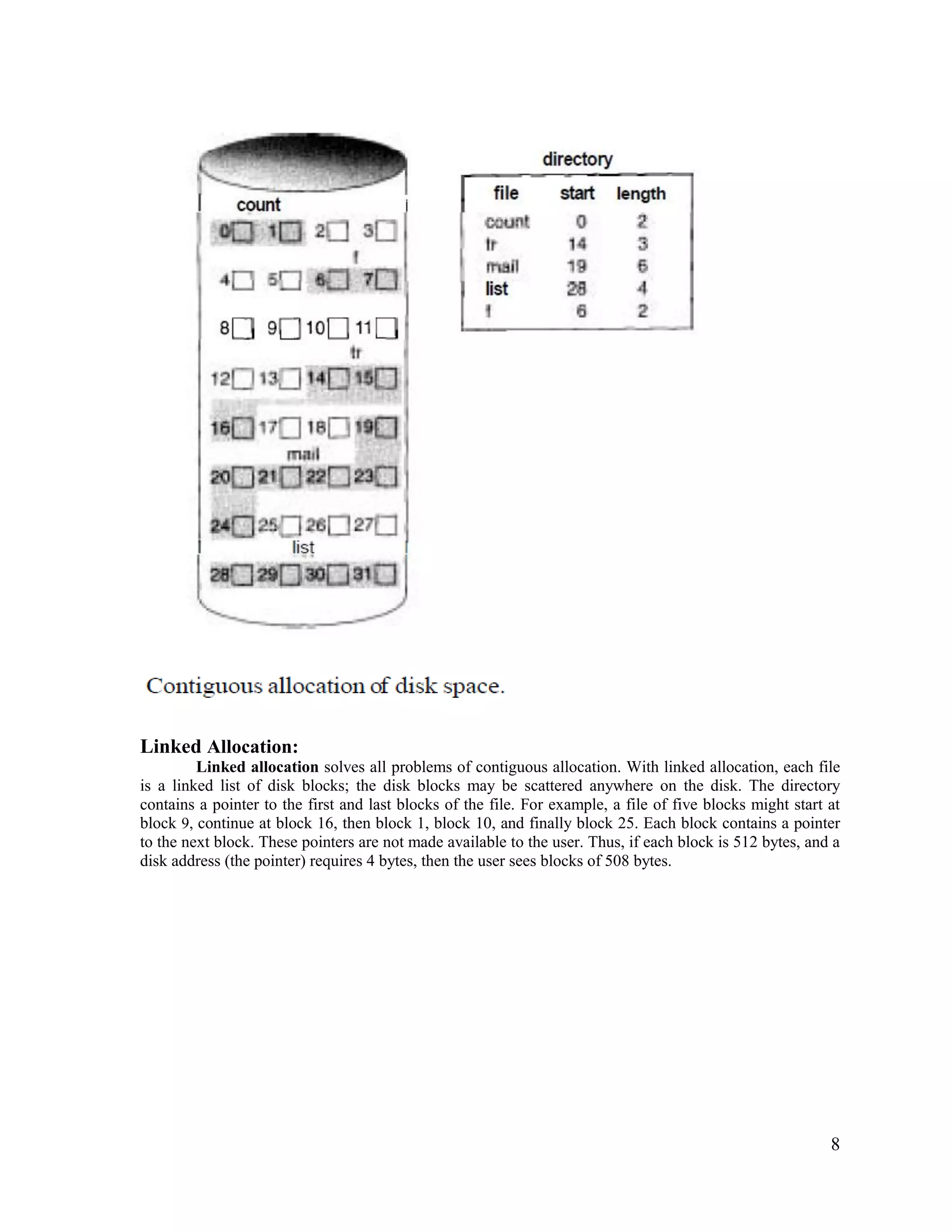







1) Files are the basic unit of storage in an operating system. They provide a logical view of information storage that is abstracted from physical storage devices. 2) A file has attributes like its name, size, location, and permissions. The operating system performs basic operations on files like creating, reading, writing, deleting and truncating files. 3) There are different methods for organizing files and allocating storage space, including contiguous, linked, and indexed allocation schemes as well as single-level, two-level, and tree directory structures. This allows files to be efficiently organized and accessed.






















































































