Outline
1. Introduction
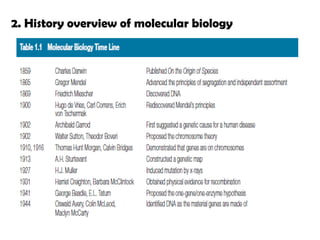
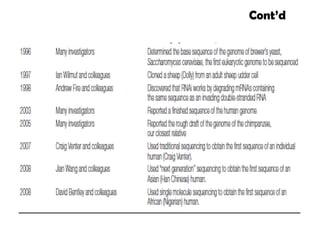
2. Historicaloverview of molecular biology
3. Overview of cells & Biologically important
molecules
4. Cellular genetic components
5. The central dogma of molecular biology
3.
1. Introduction
Molecularbiology is the study of biological
phenomena at the molecular level, in particular the
study of the molecular structure of DNA and the
information it encodes, and the biochemical basis of
gene expression and its regulation.
Molecular biology is a melding of aspects of genetics
and biochemistry
3. Overview ofcells & Biologically important molecules
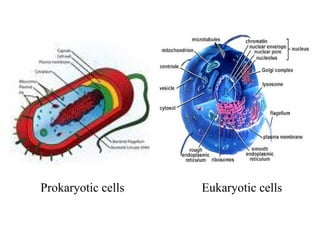
3.1 Overview of cells
Fundamental working units of every living system.
Every organism is composed of one of the two types
of cells:
1. Prokaryotic cells
2. Eukaryotic cells
Distinguished on the basis of their structure and
complexity of their organization.
1. Prokaryotic cells
Lesscomplex cells consisting of single (haploid) and
circular chromosomes lacking a nuclear membrane
Their DNA has not associated with histones
Bounded by semi rigid cell wall
Include Bacteria (eubacteria) & the Archae
(Archaebacteria)
10.
The cellcontents inside the membrane are liquid and
includes:
Cytoplasm; - helps in maintain and allowing for
cell respiration (energy production).
Nuclear material (DNA); - genetic material which
is not bounded by nuclear membrane.
Ribosome; - for protein synthesis and composed
of three kind of rRNA and about fifty kind of
protein.
11.
Extracellular structureor structure present outside of
the cell includes
Flagella; - which helps in movement of the cell.
Capsule; - structure which protects bacteria from
being engulfed by other phagocytes cells.
Pilli; - a hair like structure present in some bacteria.
Prokaryotic cells multiply by dividing into two by
binary fission, a means of multiplication in which the
nuclear material (DNA) replicates simply and the cell
divided into two and the resulting cells that produced
will have identical genetic material.
12.
2. Eukaryotic cells
Eu means true and karyoten means nucleus
Have more a complex cytoplasm, has nuclear
material (DNA) covered by nuclear membrane and
membrane bounded organelles.
The outer boundary of those cells is formed of cell
membrane,
It contains one or more paired, linear
chromosomes composed of DNA associated with
histone and non-histones proteins
Includes plants, animals, fungi and certain algae
13.
The cytoplasmof eukaryotic cells include: -
Nucleus; - surrounded by nuclear membrane and
contain DNA and nucleoli.
Endoplasmic reticulum(ER); - transport protein,
lipid and other materials.
Ribosome
Produce protein
Larger and more complex than those of the
prokaryotic cell and composed of five kinds of
rRNA and about eighty kinds of proteins.
14.
Mitochondria:
Respiration/energy production for the cell
Contains self replicating, circular, dsDNA molecule
Golgi complex; - secretion of substance from the cell
Lysosome; - produced by Golgi complex and
breakdown foreign substance.
Cell division in eukaryotes: Mitosis and Meiosis
15.
Mitosis
Results inthe formation of two daughter cells
having the same number of chromosomes as the
parent cell.
The nucleus divides by mitosis.
This is the mechanisms by which most cells
reproduce.
Meiosis
Formation of four daughter cells, each having
half number of chromosomes as the parent cell.
Haploid (1N) sex cells in diploid (2N) organisms
are produced through meiosis.
16.
Common featuresof organisms
• Chemical energy is stored in ATP
• Genetic information is encoded by DNA
• Information is transcribed into RNA
• There is a common triplet genetic code
• Translation into proteins involves ribosomes
• Shared metabolic pathways
• Similar proteins among diverse groups of organisms
17.
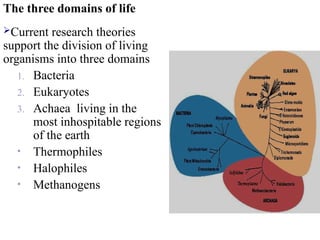
The three domainsof life
Current research theories
support the division of living
organisms into three domains
1. Bacteria
2. Eukaryotes
3. Achaea living in the
most inhospitable regions
of the earth
• Thermophiles
• Halophiles
• Methanogens
18.
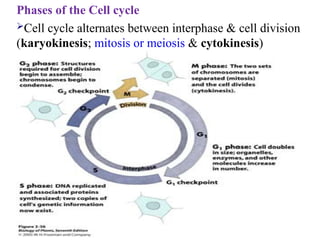
Phases of theCell cycle
Cell cycle alternates between interphase & cell division
(karyokinesis; mitosis or meiosis & cytokinesis)
cont’d
A. G1 phase
Each chromosome has one chromatid
The cell grows in size and synthesis of organelles
occurs.
B. S phase
DNA duplicates when DNA synthesis occurs
C. G2 phase
The chromosomes have two chromatids.
Synthesis of enzymes & other proteins in
preparation for mitosis
21.
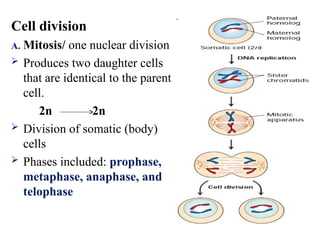
Cell division
A. Mitosis/one nuclear division
Produces two daughter cells
that are identical to the parent
cell.
2n 2n
Division of somatic (body)
cells
Phases included: prophase,
metaphase, anaphase, and
telophase
22.
Function of mitosis
Singlecelled organisms: reproduction
Multicellular organisms:
• Growth/development (asexual reproduction),
• Differentiation: specialization & division of labor
• Repair: replacement of dying cells e.g. skin, RBCs
Reproduction (multi-cellular to produce sex cells
(gametes) (meiosis)
23.
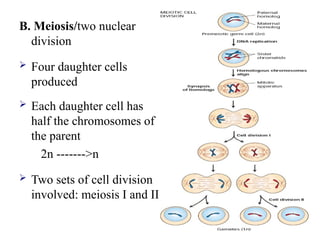
B. Meiosis/two nuclear
division
Four daughter cells
produced
Each daughter cell has
half the chromosomes of
the parent
2n ------->n
Two sets of cell division
involved: meiosis I and II
24.
Difference b/n mitosis& meiosis
Mitosis Meiosis
Purpose Produces somatic cells (Body,
growth)
produces reproductive cells
Process cell duplication (Diploid -> diploid) reduction division (Diploid ->
haploid)
Number of
Divisions
One cell division Two cell division
Product 1 -> 2 identical daughter cells To
each other & mother cell
1 -> 4 cells (gametes) daughter
cells different
Occurrence More often At a certain time in the life cycle
Crossing-
over
No Yes
Chromosome
separation
Sister chromatids Homologous chromosomes
25.
3.2 Overview Biologicalimportant molecules
Most organic molecules fall into one of four
classes:
A. Carbohydrates
B. Lipids
C. Proteins
D. Nucleic acids
26.
1. Carbohydrates
It isa common class of simple organic compounds
Function of Carbohydrates
Energy source
Give structure to cell membranes and cell walls
(in plants)
Recognition markers-e.g. A,B,O blood types
Structural component of nucleic acids (DNA and
RNA)
Serve as metabolic intermediates
27.
Major groups ofCarbohydrate
Monosaccharides (Simple Sugars)
Have basic structure (CH2O)n, where n is ≥ 3
Cannot be hydrolyzed any further (e.g., Glucose,
Galactose , and Fructose)
Monosaccharide's link to each other through glycoside
bond to form other groups.
28.
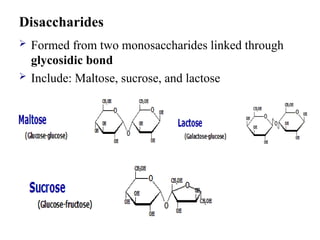
Disaccharides
Formed fromtwo monosaccharides linked through
glycosidic bond
Include: Maltose, sucrose, and lactose
29.
Polysaccharides
More than10 monosaccharids joined together by glycoside
bond
They vary in monomeric composition, bond type, degree of
branching, and biological function.
Starches: major storage form of Glucose in most plants
Two main constituents of starch are Amylopectin and Amylose
Amylose composed only of glucose units joined in an alpha (α)
-1,4- linkage.
Amylopectin composed only of glucose units are joined together
by α 1-4 linkages predominate, but every 30-50 residues, a
‘branch’ arises from an α-1,6- linkage.
30.
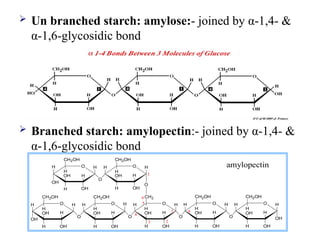
Un branchedstarch: amylose:- joined by α-1,4- &
α-1,6-glycosidic bond
Branched starch: amylopectin:- joined by α-1,4- &
α-1,6-glycosidic bond
H O
OH
H
OH
H
OH
CH2OH
H
O H
H
OH
H
OH
CH2OH
H
O
H
H H O
O
H
OH
H
OH
CH2
H
H H O
H
OH
H
OH
CH2OH
H
OH
H
H O
O
H
OH
H
OH
CH2OH
H
O
H
O
1 4
6
H O
H
OH
H
OH
CH2OH
H
H H O
H
OH
H
OH
CH2OH
H
H
O
1
OH
3
4
5
2
amylopectin
31.
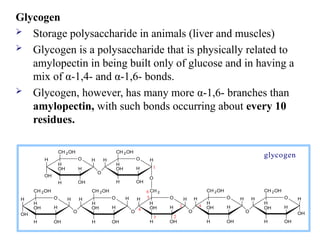
Glycogen
Storage polysaccharidein animals (liver and muscles)
Glycogen is a polysaccharide that is physically related to
amylopectin in being built only of glucose and in having a
mix of α-1,4- and α-1,6- bonds.
Glycogen, however, has many more α-1,6- branches than
amylopectin, with such bonds occurring about every 10
residues.
H O
OH
H
OH
H
OH
CH 2OH
H
O H
H
OH
H
OH
CH 2OH
H
O
H
H H O
O
H
OH
H
OH
CH 2
H
H H O
H
OH
H
OH
CH 2OH
H
OH
H
H O
O
H
OH
H
OH
CH 2OH
H
O
H
O
1 4
6
H O
H
OH
H
OH
CH 2OH
H
H H O
H
OH
H
OH
CH 2OH
H
H
O
1
OH
3
4
5
2
glycogen
32.
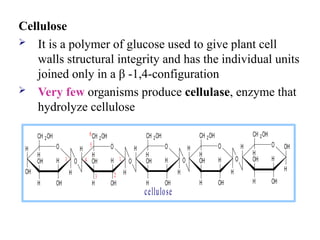
Cellulose
It isa polymer of glucose used to give plant cell
walls structural integrity and has the individual units
joined only in a β -1,4-configuration
Very few organisms produce cellulase, enzyme that
hydrolyze cellulose
cellulose
H O
OH
H
OH
H
OH
CH 2OH
H
O
H
OH
H
OH
CH 2OH
H
O
H H O
O H
OH
H
OH
CH 2OH
H
H O
H
OH
H
OH
CH 2OH
H
H
OH
H O
O H
OH
H
OH
CH 2OH
H
O
H H H H
1
6
5
4
3
1
2
33.
2. Proteins
Proteins arepolymers of monomers called amino acids
Amino acid contains amino & carboxyl groups cause
protein to have a positively charged end & a negatively
charged end & an alpha carbon bonded to 4 different
covalent partners Structure of an amino acid
Different amino acids
differ in their R-group
that determines physical &
chemical characteristics of amino acid (aa).
34.
Amino acidsform polymers when the negative
carboxyl group(COO-
) of one amino acid react with
amino group of the other amino acid.
During this process there is releasing a molecule of
water and a formation of an amid link or a peptide
bond (-CONH-) thereby forming a polypeptide chain.
In a reverse reaction, the peptide bond can be cleaved
by water (hydrolysis).
NH3-CH-COO + NH3-CH-COO ↔NH3-CH-CO- NH-CH-COO
R R’ R
R’
-H2O
Peptide
bond
- - -
+
+ +
35.
Function of proteins
Proteinsdo all essential work for the cell
– build cellular structures
– digest nutrients
– execute metabolic functions
– mediate information flow within a cell and among
cellular communities.
36.
Protein Structure
A proteinmolecule may consist of one very long
polypeptide chain or it may consist of several polypeptide
chains joined together in which case linkage other than
peptide bonds is involved.
When cells make a polypeptide, the chain folds
spontaneously to assume the functional conformation of
that protein
4 superimposed levels of structure
37.
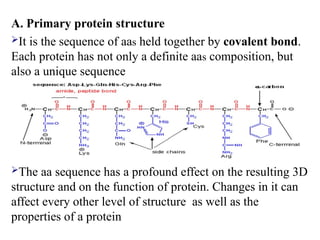
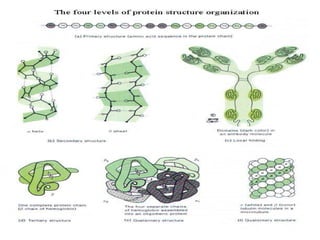
A. Primary proteinstructure
It is the sequence of aas held together by covalent bond.
Each protein has not only a definite aas composition, but
also a unique sequence
The aa sequence has a profound effect on the resulting 3D
structure and on the function of protein. Changes in it can
affect every other level of structure as well as the
properties of a protein
38.
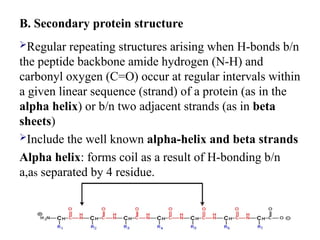
B. Secondary proteinstructure
Regular repeating structures arising when H-bonds b/n
the peptide backbone amide hydrogen (N-H) and
carbonyl oxygen (C=O) occur at regular intervals within
a given linear sequence (strand) of a protein (as in the
alpha helix) or b/n two adjacent strands (as in beta
sheets)
Include the well known alpha-helix and beta strands
Alpha helix: forms coil as a result of H-bonding b/n
a,as separated by 4 residue.
39.
Beta strands
Consists oftwo or more aa sequence that are arranged
adjacently and the 2 or more strands are joined by
hydrogen bond
Adjacent β strands can form hydrogen bonds in
antiparallel or parallel arrangements
In an antiparallel arrangement, the successive β strands
alternate directions
In a parallel arrangement, all of the N-termini of
successive strands are oriented in the same direction
40.
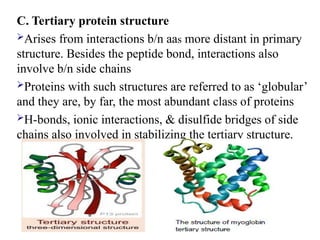
C. Tertiary proteinstructure
Arises from interactions b/n aas more distant in primary
structure. Besides the peptide bond, interactions also
involve b/n side chains
Proteins with such structures are referred to as ‘globular’
and they are, by far, the most abundant class of proteins
H-bonds, ionic interactions, & disulfide bridges of side
chains also involved in stabilizing the tertiary structure.
41.
D. Quaternary proteinstructure
The last level of protein structure we will consider is
that of quaternary structure
Results from the union of more than one protein
molecules, which function as part of the larger
assembly or protein complex
Consider hemoglobin, the oxygen carrying protein of
our blood, contains two alpha and beta subunits
Multiple subunit proteins are common in cells and
they give rise to very useful properties not found in
single subunit proteins
42.
04/12/25
42
Structure of humanhemoglobin. The protein's α and β subunits
are in red and blue, and the iron-containing heme groups in
green.
43.
Protein Denaturation
Proteins denaturewhen they lose their 3-D structure
>>their chemical conformation and thus their
chemical characteristic folded structure
Proteins may be denatured at secondary, tertiary and
quaternary structural levels, but not at the primary
structural level
Denaturation is usually caused by heat, acids, bases,
detergents, alcohols, heavy metals, reducing agents or
certain chemicals such as urea
Denatured proteins can be irreversible or reversible
denaturation, when the denaturing influence is removed.
44.
3. Lipids
Biological moleculesthat are insoluble in aqueous
solutions and soluble in organic solvents are classified
as lipids
Composed of monomers of alcohol (glycerol) & fatty
acids
Fats (solid) & oils (liquid at room temp.)
Fats associated with animals - butter
Oils associated with plants - corn oil, olive oil
Function of lipids
Provide energy reserves- fats & oils
Insulation (subcutaneous fat) & Cushions of internal
organs
Serve as structural components of biological
membranes
Message (signaling) & membrane fluidity – steroids
Hormones (testosterone, estrogen) - steroids
47.
4. Nucleic acids
Nucleic acids are very large and complex molecules
responsible for storage, transmission, and translation
of genetic information
Found in all cells (inside nucleus, mitochondria and
chloroplast)
They are long chain or polymers of repeating
subunits, called nucleotides, with 4 bases [adenine,
guanine, cytosine, and thymine (in DNA) or uracil
(in RNA)]
48.
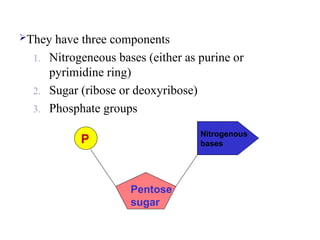
They have threecomponents
1. Nitrogeneous bases (either as purine or
pyrimidine ring)
2. Sugar (ribose or deoxyribose)
3. Phosphate groups
P
Pentose
sugar
Nitrogenous
bases
49.
There arebasically two types of nucleic acids
1. DNA (Deoxyribonucleic acid)
2. RNA (Ribonucleic acid )
DNA
Contain deoxyribose sugar
made of two polynucleotide strands
have thymine rather than uracil
RNA
contain ribose sugar
made of a single polynucleotide strand
have uracil instead of thymine
50.
1. Nitrogenous bases
Theyare nitrogen-containing molecules having the
chemical properties of a base (a substance that accepts
an H+ ion or proton in solution).
Fall into two types: Pyrimidine (Cytosine, Thymine
and Uracil) and Purine (Adenine and Guanine).
The Nitrogenous bases pair up with other bases.
specific one purine to one pyrimidine
Components of nucleotides
51.
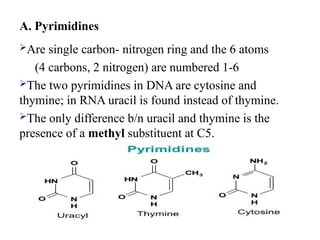
A. Pyrimidines
Are singlecarbon- nitrogen ring and the 6 atoms
(4 carbons, 2 nitrogen) are numbered 1-6
The two pyrimidines in DNA are cytosine and
thymine; in RNA uracil is found instead of thymine.
The only difference b/n uracil and thymine is the
presence of a methyl substituent at C5.
52.
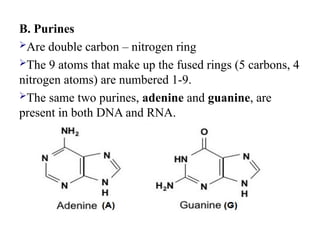
B. Purines
Are doublecarbon – nitrogen ring
The 9 atoms that make up the fused rings (5 carbons, 4
nitrogen atoms) are numbered 1-9.
The same two purines, adenine and guanine, are
present in both DNA and RNA.
53.
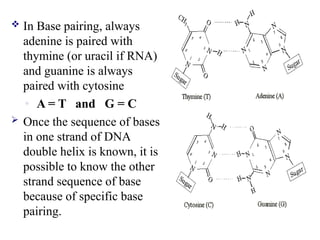
In Basepairing, always
adenine is paired with
thymine (or uracil if RNA)
and guanine is always
paired with cytosine
◦ A = T and G = C
Once the sequence of bases
in one strand of DNA
double helix is known, it is
possible to know the other
strand sequence of base
because of specific base
pairing.
54.
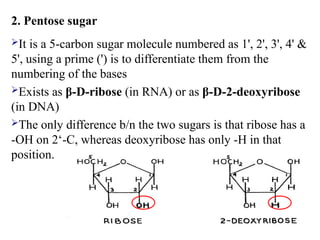
2. Pentose sugar
Itis a 5-carbon sugar molecule numbered as 1', 2', 3', 4' &
5', using a prime (') is to differentiate them from the
numbering of the bases
Exists as β-D-ribose (in RNA) or as β-D-2-deoxyribose
(in DNA)
The only difference b/n the two sugars is that ribose has a
-OH on 2‘-C, whereas deoxyribose has only -H in that
position.
55.
3. Phosphate group(PO4)
It gives an acidic character of nucleotides because it dissociate
at the PH found in the cells, freeing H+
ions & leaving the
phosphate negatively charged
Two sugars in polymerised RNA or DNA molecule are joined
by a phosphoric acid molecule which is forming an ester bond
with the 5' and 3' C.
56.
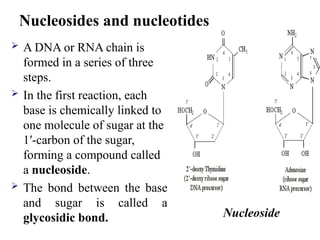
A DNAor RNA chain is
formed in a series of three
steps.
In the first reaction, each
base is chemically linked to
one molecule of sugar at the
1′-carbon of the sugar,
forming a compound called
a nucleoside.
The bond between the base
and sugar is called a
glycosidic bond. Nucleoside
Nucleosides and nucleotides
57.
When aphosphate group is also attached to the 5′-
carbon of the same sugar, the nucleoside becomes a
nucleotide.
Nucleotides can possess 1, 2, or 3 phosphate groups &
labeled with α, β & γ phosphate, respectively.
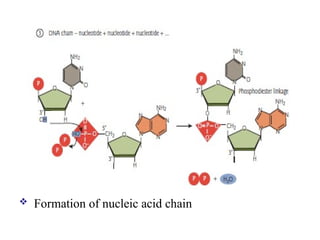
Finally, nucleotides are joined (polymerized) by
condensation reactions to form a chain (strand).
The OH on the 3′-carbon of a sugar of one nucleotide
forms an ester bond to the phosphate of another
nucleotide, eliminating a molecule of water.
This chemical bond linking the sugar components of
adjacent nucleotides is called a phosphodiester bond,
or 5′ → 3′ phosphodiester bond, indicating the
polarity of the strand.
58.
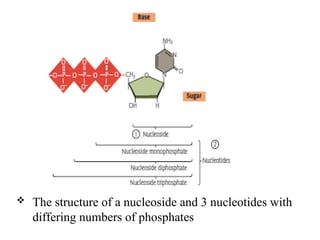
The structureof a nucleoside and 3 nucleotides with
differing numbers of phosphates
Nucleotides maycontain 1 phosphate unit
(monophosphate), two such (diphosphate), or three
(triphosphate).
When free in the cell pool, nucleotides usually occur
as triphosphates: deoxynucleoside triphosphates
(dNTPs) and nucleoside triphosphates (NTPs)
The triphosphate (dNTPs and NTPs) form serves as
the precursor building block for a DNA or RNA chain
during synthesis.
Nomenclature of the nucleotides use shorthand. E.g.,
deoxycytidine triphosphate (DNA) and cytidine
triphosphate (RNA) are abbreviated to dCTP and CTP,
respectively.
61.
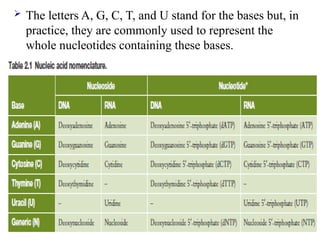
The lettersA, G, C, T, and U stand for the bases but, in
practice, they are commonly used to represent the
whole nucleotides containing these bases.
62.
Significance of 5′and 3′
The ends of a DNA or RNA chain are distinct and
have different chemical properties. The two ends are
designated by the symbols 5′ and 3′.
The symbol 5′ refers to the carbon in the sugar to
which a phosphate (PO4) functional group is attached.
The symbol 3′ refers to the carbon in the sugar ring to
which a hydroxyl (OH) functional group is attached.
The asymmetry of the ends of a DNA strand implies
that each strand has a polarity determined by which
end bears the 5′-phosphate and which end bears the 3′-
hydroxyl group.
63.
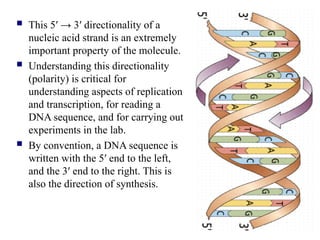
This 5′→ 3′ directionality of a
nucleic acid strand is an extremely
important property of the molecule.
Understanding this directionality
(polarity) is critical for
understanding aspects of replication
and transcription, for reading a
DNA sequence, and for carrying out
experiments in the lab.
By convention, a DNA sequence is
written with the 5′ end to the left,
and the 3′ end to the right. This is
also the direction of synthesis.
64.
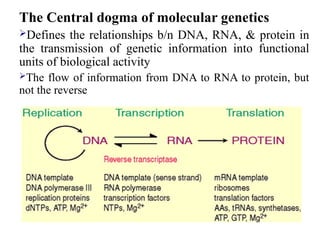
The Central dogmaof molecular genetics
Defines the relationships b/n DNA, RNA, & protein in
the transmission of genetic information into functional
units of biological activity
The flow of information from DNA to RNA to protein, but
not the reverse
Editor's Notes
#21 If the parent cell is diploid, the daughter cells will also be diploid.
#25 The major elements found in biological material can be remembered with the acronym SPONCH
#45 Note: Number of fatty acids determines if it’s a mono-, di-, or triglyceride.
glycerol + 1 fatty acid -> monoglyceride
monoglyceride + 2nd fatty acid -> diglyceride
diglyceride + 3rd fatty acid -> triglyceride
#46 It aloows membranes permeability & diffusion = Phospholipids






























![4. Nucleic acids
Nucleic acids are very large and complex molecules
responsible for storage, transmission, and translation
of genetic information
Found in all cells (inside nucleus, mitochondria and
chloroplast)
They are long chain or polymers of repeating
subunits, called nucleotides, with 4 bases [adenine,
guanine, cytosine, and thymine (in DNA) or uracil
(in RNA)]](https://image.slidesharecdn.com/chapter1-250412223758-b13fcc04/85/chapter-11235676890900-988676565eeee-ppt-47-320.jpg)