Download as PDF, PPTX
























![@alexsotob27
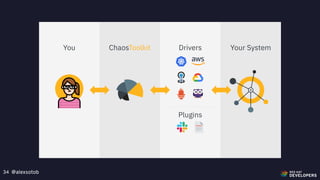
Run
Canary Release
X v1
X v2
user
90%
10%
Dark Canaries
X v1
X v2
user
*
[10.0.X.Y]
Containerise the experiment
Define Expected Behaviour
Make it public within the organisation](https://image.slidesharecdn.com/chaosengineeringkubernetes-191203085152/85/Chaos-Engineering-Kubernetes-27-320.jpg)





![@alexsotob35
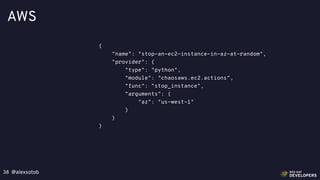
Defining Steady State"steady-state-hypothesis": {
"title": "Services are all available and healthy",
"probes": [
{
"type": "probe",
"name": "application-should-be-alive-and-healthy",
"tolerance": true,
"provider": {
"type": "python",
"module": "chaosk8s.probes",
"func": "microservice_available_and_healthy",
"arguments": {
"name": “greetings-app",
"ns": "default"
}
}
},
{
"type": "probe",
"name": "application-must-respo
"tolerance": 200,
"provider": {
"type": "http",
"verify_tls": false,
"url": “https://app.greetin
}
}
]
},](https://image.slidesharecdn.com/chaosengineeringkubernetes-191203085152/85/Chaos-Engineering-Kubernetes-35-320.jpg)
![@alexsotob36
Defining Experiment
"method": [
{
"type": "action",
"name": "terminate-db-master",
"provider": {
"type": "python",
"module": "chaosk8s.pod.actions",
"func": "terminate_pods",
"arguments": {
"label_selector": "spilo-role=master",
"name_pattern": “greetings-db-[0-9]$",
"rand": true,
"ns": "default"
}
},
"pauses": {
"after": 2
}
},](https://image.slidesharecdn.com/chaosengineeringkubernetes-191203085152/85/Chaos-Engineering-Kubernetes-36-320.jpg)
![@alexsotob37
Verifying Experiment{
"type": "probe",
"ref": "application-must-respond"
},
{
"type": "probe",
"name": "fetch-patroni-operator-logs",
"provider": {
"type": "python",
"module": "chaosk8s.pod.probes",
"func": "read_pod_logs",
"arguments": {
"label_selector": "name=postgres-operator",
"last": "20s",
"ns": "default"
}
}
}
],
"rollbacks": []chaos run experiment.json](https://image.slidesharecdn.com/chaosengineeringkubernetes-191203085152/85/Chaos-Engineering-Kubernetes-37-320.jpg)


![@alexsotob43
Put on your Sunday clothes
there's lots of world
out there.
— Wall-E
“
[https://github.com/lordofthejars/chaos-quarkus]](https://image.slidesharecdn.com/chaosengineeringkubernetes-191203085152/85/Chaos-Engineering-Kubernetes-43-320.jpg)


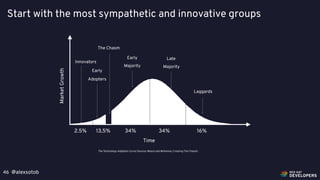





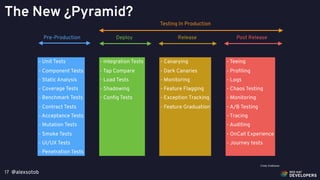
The document discusses chaos engineering principles applied within Kubernetes, emphasizing the need to intentionally disrupt systems to test their resilience and behavior under failure conditions. It outlines various testing methods and the importance of defining a steady state, running experiments, validating results, and developing recovery strategies. Key concepts include canary releases, monitoring, and the significance of a structured approach to chaos testing in improving system reliability.


























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







