This document discusses parallel database management systems and includes the following key points:
1) Parallel DBMSs use parallel evaluation techniques to speed up operations like data loading, indexing, and query evaluation by dividing work across multiple processors.
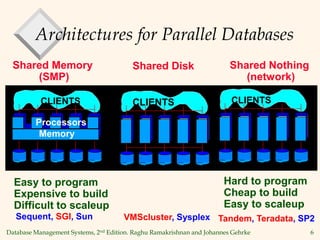
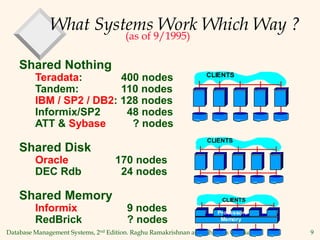
2) There are three main architectures for parallel databases: shared memory, shared disk, and shared nothing.
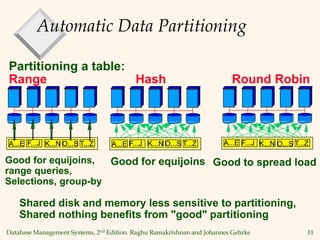
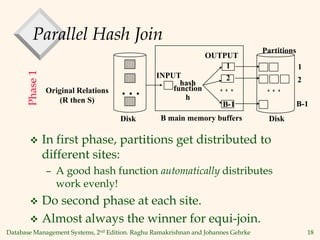
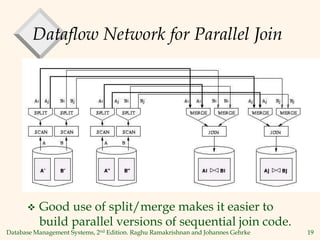
3) Techniques for parallelizing operations include range-partitioning or hash-partitioning tables and joining the partitions in parallel, as well as using dataflow networks with split and merge operators.
4) Query optimization for parallel systems focuses on choosing a good sequential plan then determining the degree of parallelism based on system parameters.

































![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































