Downloaded 119 times




















![Data modelCF = users[userUUID] [segmentID] = 1CF = segments[segmentID] [userUUID] = 1](https://image.slidesharecdn.com/brisktalk-110517055123-phpapp01/85/Cassandra-Hadoop-Brisk-23-320.jpg)
![Data modelcreate keyspacewhyk... with placement_strategy = 'org.apache.cassandra.locator.SimpleStrategy' ... and strategy_options = [{replication_factor:1}];create column family users ... with comparator = 'AsciiType'... and rows_cached = 5000;create column family segments... with comparator = 'AsciiType'... and rows_cached = 5000;](https://image.slidesharecdn.com/brisktalk-110517055123-phpapp01/85/Cassandra-Hadoop-Brisk-24-320.jpg)
![Data modelcreate keyspacewhyk... with placement_strategy = 'org.apache.cassandra.locator.SimpleStrategy' ... and strategy_options = [{replication_factor:1}];create column family users ... with comparator = 'AsciiType'... and rows_cached = 5000;create column family segments... with comparator = 'AsciiType'... and rows_cached = 5000;](https://image.slidesharecdn.com/brisktalk-110517055123-phpapp01/85/Cassandra-Hadoop-Brisk-25-320.jpg)






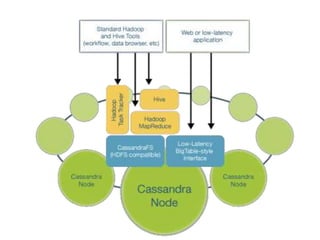
The document discusses a platform called Brisk, which integrates Hadoop, Hive, and Cassandra to manage data for an ad network targeting user segmentation and real-time analytics. It includes technical details about the data model, setup instructions, and PHP code examples for implementing user tracking via a pixel-based system. The document emphasizes ease of use, mixed-mode querying, and the absence of a single point of failure in the architecture.







































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







