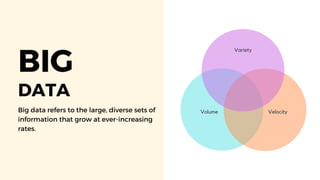
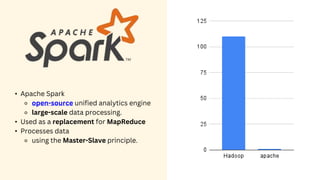
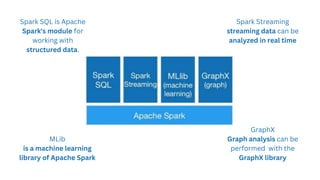
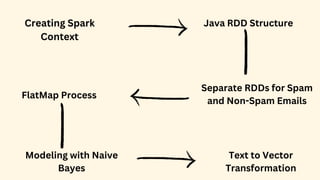
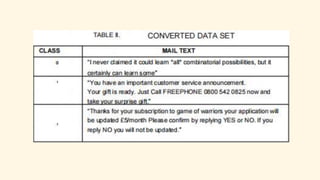
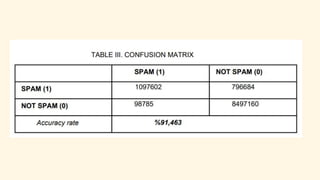
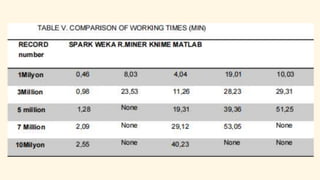
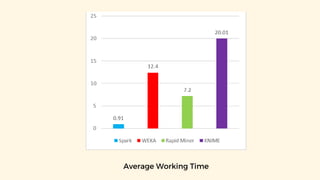
Spark is an open-source unified analytics engine that can be used as a replacement for MapReduce. It processes large and diverse datasets using a master-slave principle. Spark has modules for working with structured data using Spark SQL, streaming data analysis with Spark Streaming, machine learning with MLib, and graph analysis with GraphX. The document describes using Spark for spam detection by creating separate RDDs for spam and non-spam emails, applying flatMap processing to transform text to vectors, and using Naive Bayes modeling to classify emails. It concludes that Spark is faster for analyzing a dataset of 10.5 million email records totaling 5GB in size.