1. The document discusses building a small data center network for Dyn, focusing on lessons learned from two design iterations.
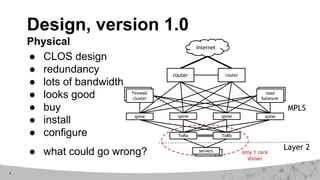
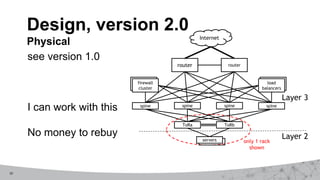
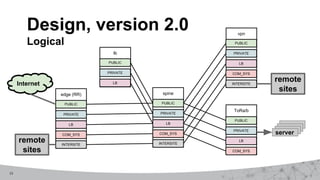
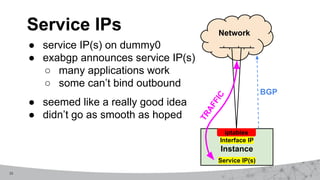
2. The first design used MPLS VPNs but had issues with routing and IPv6 support. The second design used virtual routing and forwarding with multiple routing tables to separate traffic and improve service mobility.
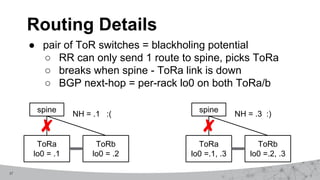
3. Key lessons included validating designs before deploying, automating network operations, and moving security policies to instances rather than the network to improve agility and isolate impacts.