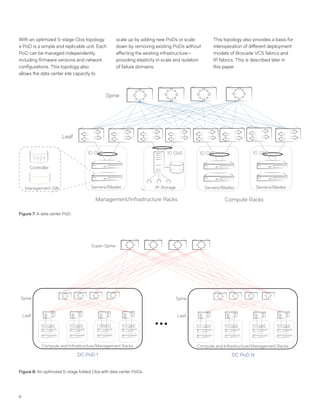
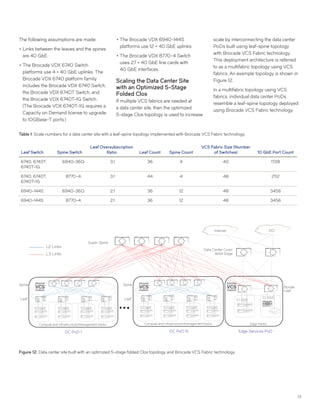
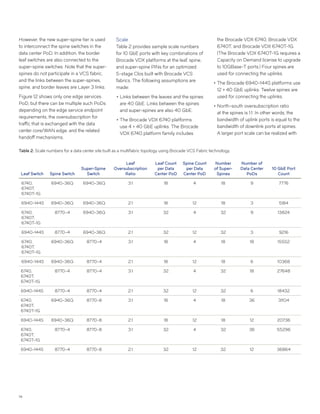
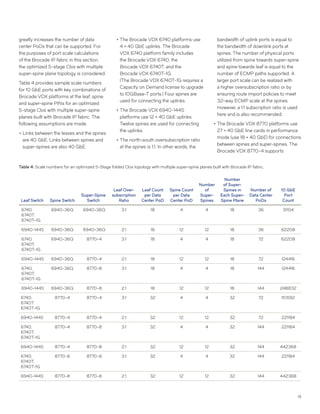
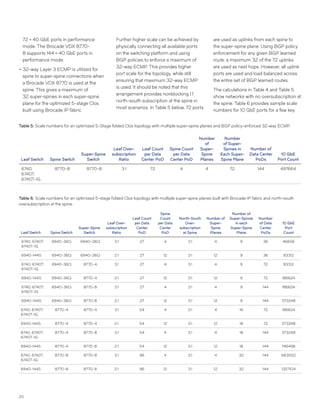
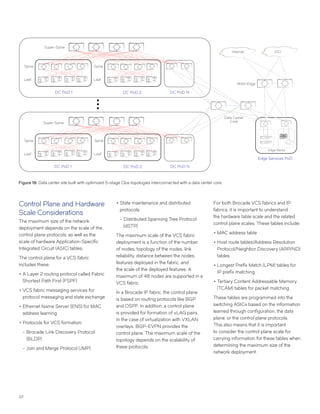
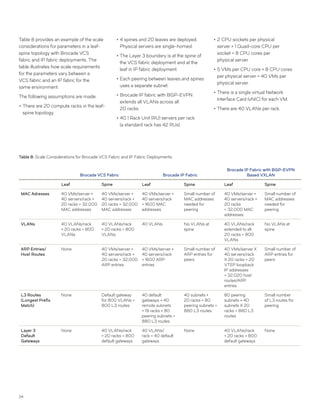
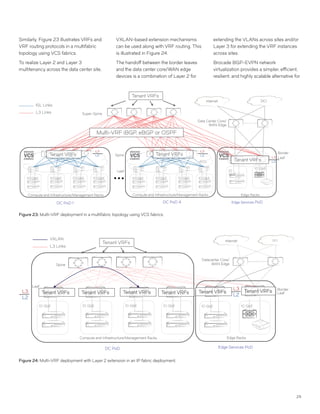
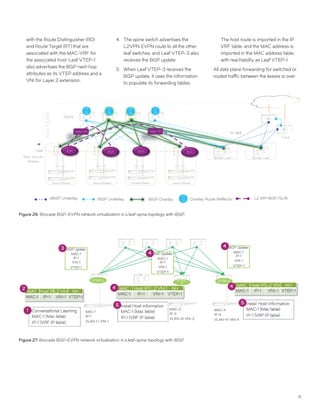
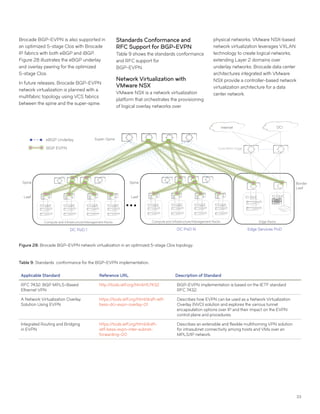
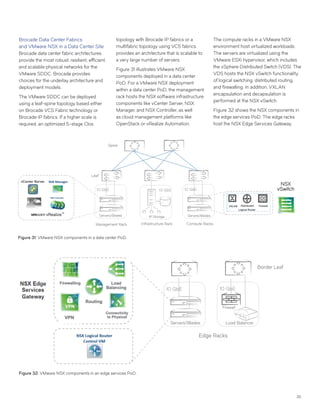
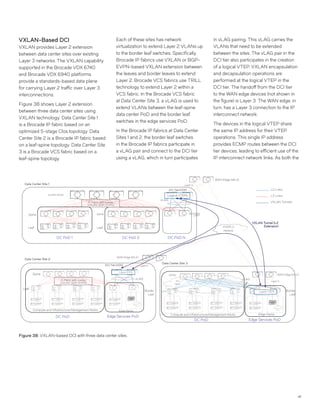
This document discusses Brocade's cloud-optimized data center fabric architectures. It describes how data center networking architectures have evolved from traditional three-tier designs focused on north-south traffic to modern scale-out designs optimized for east-west traffic in cloud environments. The white paper outlines Brocade's networking solutions including virtualization options, data center interconnect fabrics, and automation tools to help architects and engineers design networks that meet their technical and business needs.