This document discusses parallelizing the Berlekamp-Massey algorithm (BMA) using SIMD instructions and GPU streams. It first provides background on the BMA and its use in linear feedback shift registers. It then describes implementing the BMA using SSE and AVX instructions to perform computations on multiple data elements simultaneously. Finally, it discusses parallelizing the BMA on a GPU using multiple streams to concurrently execute kernels, achieving speedups over the serial CPU implementation for long input lengths. Evaluation results show the SIMD CPU implementation outperforms GPU with one stream for inputs under 2^23 bits, while the GPU with 32 streams is fastest for longer inputs.



![BMA Algorithm
u Given a finite binary sequence, find a shortest LFSR that generates
the sequence
u Elwyn Berlekamp
u A paper/presentation at International Symposium on Information Theory,
Italy, 1967 [1]
u Algebraic coding theory, McGraw-Hill, 1968 [2]
u James Massey
u Shift-register synthesis and BCH decoding, IEEE Transactions on
Information Theory, 1969 [3]
u “LFSR synthesis algorithm”, “Berlekamp iterative algorithm”](https://image.slidesharecdn.com/6ad81915-e240-498c-b69d-2359655baeee-161216185209/85/BMA-4-320.jpg)

![BMA Algorithm
u Prof.Ouyang Previous Work[4]
u Reverse S
u Pack 32 bits into one word
u Compute inner product
u Count # of 1-bits in a 32-bit word
u Update C(x)
u GPU is faster than CPU reverse bit version for long input length (more
than 2^22)](https://image.slidesharecdn.com/6ad81915-e240-498c-b69d-2359655baeee-161216185209/85/BMA-6-320.jpg)
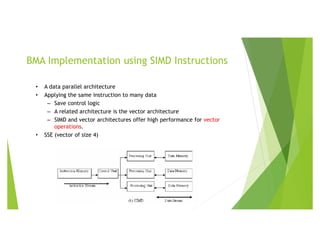












![References
u [1] Berlekamp, Elwyn R. ,"Nonbinary BCH decoding", International Symposium
on Information Theory, San Remo, Italy, 1967.
u [2] Berlekamp, Elwyn R. , "Algebraic Coding Theory" , Laguna Hills, CA:
Aegean Park Press, ISBN 0-89412-063-8. Previous publisher McGraw-Hill, New
York, NY, 1968.
u [3] Massey, J. L., "Shift-register synthesis and BCH decoding", IEEE Trans.
Information Theory, IT-15 (1): 122–127, 1969.
u [4] Ali H, Ouyang M, Sheta W, Soliman A. Parallelizing the Berlekamp-Massey
Algorithm. Proceedings of the Second International Conference on Computing,
Measurement, Control and Sensor Network (CMCSN), 2014.](https://image.slidesharecdn.com/6ad81915-e240-498c-b69d-2359655baeee-161216185209/85/BMA-20-320.jpg)






















































