Downloaded 11 times





















































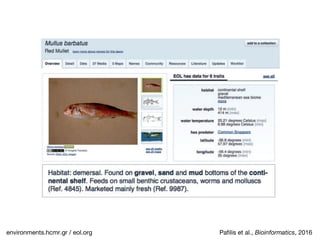


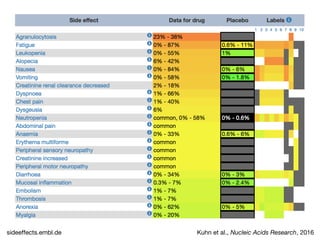






![Gene and protein names
Cue words for entity
recognition
Verbs for relation extraction
[nxexpr The expression of
[nxgene the cytochrome
genes
[nxpg CYC1 and CYC7]]]
is controlled by
[nxpg HAP1]
Saric et al., Proceedings of ACL, 2004](https://image.slidesharecdn.com/jensen2017talk17-170913073401/85/Biomedical-text-mining-Automatic-processing-of-unstructured-text-67-320.jpg)














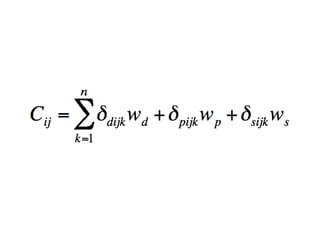




















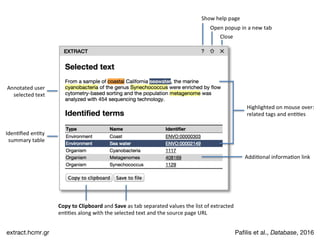
1) Lars Juhl Jensen discusses biomedical text mining and automatic processing of unstructured text such as patent literature, grant proposals, FDA product labels, and electronic medical records. 2) Named entity recognition is used to identify genes/proteins, chemical compounds, diseases, and other entities in text through comprehensive dictionaries and flexible matching rules that account for variations. 3) Relation extraction uses natural language processing techniques like part-of-speech tagging and sentence parsing along with manually crafted rules and machine learning to identify implicit relations between entities in text such as transcription factor targets, kinase substrates, and protein-protein interactions.























































































