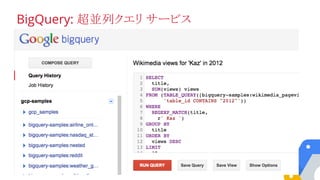
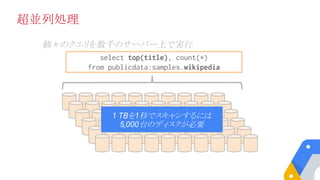
例: 1000億行に対するRegEx +GROUP BY
SELECT language, SUM(views) as views
FROM (
SELECT title, language, MAX(views) as views
FROM [helixdata2:benchmark.Wiki100B]
WHERE REGEXP_MATCH(title, "G.*o.*")
GROUP EACH BY title, language
)
GROUP EACH BY language
ORDER BY views desc
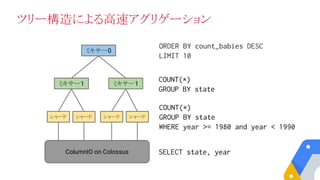
ミキサー0
ミキサー1 ミキサー1
シャード シャードシャード シャード
ColumnIO on Colossus SELECT state, year
COUNT(*)
GROUP BY state
WHERE year >= 1980 and year < 1990
ORDER BY count_babies DESC
LIMIT 10
COUNT(*)
GROUP BY state
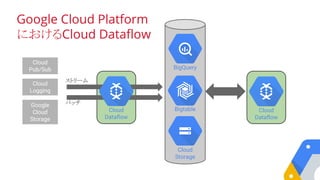
ツリー構造による高速アグリゲーション
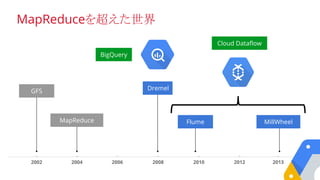
14.
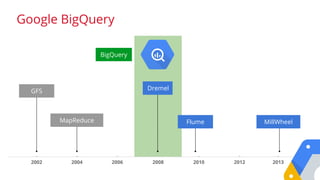
BigQuery Analytic Servicein the Cloud
BigQuery
Google
アナリティクス
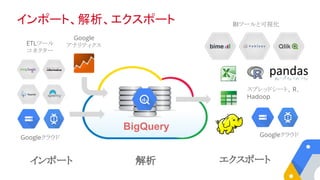
解析 エクスポートインポート
インポート、解析、エクスポート
ETLツール
コネクター
BIツールと可視化
Googleクラウド Googleクラウド
スプレッドシート、R、
Hadoop






![例: 1000億行に対するRegEx + GROUP BY
SELECT language, SUM(views) as views
FROM (
SELECT title, language, MAX(views) as views
FROM [helixdata2:benchmark.Wiki100B]
WHERE REGEXP_MATCH(title, "G.*o.*")
GROUP EACH BY title, language
)
GROUP EACH BY language
ORDER BY views desc](https://image.slidesharecdn.com/6-18next-googlemapreduce-150630050026-lva1-app6891/85/6-18-Next-Google-MapReduce-9-320.jpg)








![オートコンプリートの例
ツイート
予測
読み
込み
#argentina scores, my #art project,
watching #armenia vs #argentina
タグの抽出 #argentina #art #armenia #argentina
カウント (argentina, 5M) (art, 9M) (armenia, 2M)
プレフィクス対応
a->(argentina,5M) ar->(argentina,5M)
arg->(argentina,5M) ar->(art, 9M) ...
上位3件抽出
書き
出し
a->[apple, art, argentina]
ar->[art, argentina, armenia]
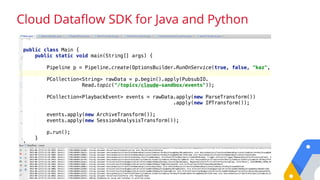
.apply(TextIO.Read.from(...))
.apply(ParDo.of(new ExtractTags()))
.apply(Count.create())
.apply(ParDo.of(new ExpandPrefixes())
.apply(Top.largestPerKey(3)
Pipeline p = Pipeline.create();
p.begin();
.apply(TextIO.Write.to(...));
p.run()](https://image.slidesharecdn.com/6-18next-googlemapreduce-150630050026-lva1-app6891/85/6-18-Next-Google-MapReduce-27-320.jpg)






![[Cloud OnAir] Google Cloud Next '18 in London 最新情報 2018年10月18日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooooo-181018091804-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] ビジネスの成長を加速するマーケティング データウェアハウス 2019年12月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1205-191205090806-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud 主催イベント Data Platform Day Recap!〜登壇企業インタビューと内容解説〜 2...](https://cdn.slidesharecdn.com/ss_thumbnails/0409-200409090356-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] エンタープライズでのマイグレーション 方法論やクラウド ジャーニー 2019年7月18日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0718-190726085551-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] BigQuery ML と AutoML Tables で はじめるマーケティング分析入門 2019年5月23日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0523-190523094914-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] ビジネスを変革する!クラウドを活用したデータ分析基盤の第一歩 (LIVE) 2018年4月12日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/cloudonair412-180412095134-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201022092013-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir ] #05 Google Cloud の G Suite で働き方改革が簡単にできる](https://cdn.slidesharecdn.com/ss_thumbnails/cloudonair05googlecloudgsuite-171130102535-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 2019 年振り返り!G Suite 新機能紹介 2019年11月28日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1128-191128072640-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] クラウドからエッジまで!進化する GCP の IoT サービス 2018年11月22日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aiaia-181122091746-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 良いデータのために良い可視化ツールを使いましょう! 2019年11月7日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1107-191107092842-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] Chronicle Backstory のご紹介 2020 年 1 月 23 日放送](https://cdn.slidesharecdn.com/ss_thumbnails/a-200123090919-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ol-201203090835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Cloud Data Fusion で GCP にデータを集約して素早く分析を開始しよう 2019年10月31日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1031-191031092923-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] アプリケーションにフォーカス!ビジネスに直結する開発の極意をご紹介します。(LIVE) 2018年3月8日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/cloudonair-season2ep4-rapiddev-180308095157-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 最新アップデート Google Cloud データ関連ソリューション 2020年5月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] ビッグデータ事例紹介 データ分析と実践編 (e-Learning) 2018年6月28日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aaaaaaaaaaaaaaaaaaaaaaaaa-180628084133-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] お客様事例紹介 -リクルートライフスタイルにおける デジタルトランスフォーメーションとクラウド活用- 2018年7月12日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/444444444444-180712090757-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] ビジネスを変革する!クラウドを活用したデータ分析基盤の第一歩 (e-Learning) 2018年4月19日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aa-180419095105-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] #01 徹底解剖 GCP のここがすごい](https://cdn.slidesharecdn.com/ss_thumbnails/cloudonairgcp-171005103254-thumbnail.jpg?width=640&height=640&fit=bounds)























![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ppp-201221033858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...](https://cdn.slidesharecdn.com/ss_thumbnails/pta-201210085248-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ii-201126090801-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/yy-201119084816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...](https://cdn.slidesharecdn.com/ss_thumbnails/h-201112061942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ab-201105085037-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/bb-201029090440-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooo-200924094839-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ffffffffffffffff-200903090943-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Cloud OnAir] Talks by DevRel Vol.4 データ管理とデータ ベース 2020年8月27日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ttt-200827092150-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Talks by DevRel Vol.2 セキュリティ 2020年8月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aaaa-200806090441-thumbnail.jpg?width=640&height=640&fit=bounds)