Downloaded 72 times








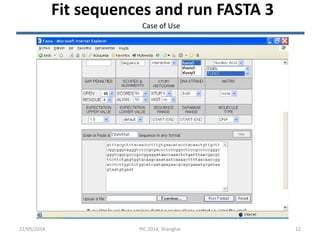
![22/05/2014 13
The output
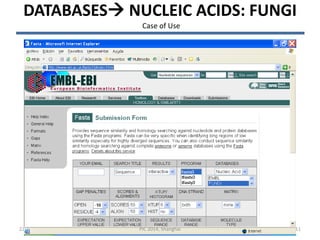
• FASTA searches a protein or DNA sequence data bank
• version 3.3t09 May 18, 2001
• Please cite:
• W.R. Pearson & D.J. Lipman PNAS (1988) 85:2444-2448
• @:1-: 241 nt
•
• vs EMBL Fungi library
• searching /ebi/services/idata/v225/fastadb/em_fun library
• 104701680 residues in 66478 sequences
• statistics extrapolated from 60000 to 61164 sequences
• Expectation_n fit: rho(ln(x))= -1.2290+/-0.000361; mu= 72.1313+/- 0.026
• mean_var=907.6270+/-295.007, 0's: 68 Z-trim: 4246 B-trim: 15652 in 3/79
• Lambda= 0.0426
• FASTA (3.39 May 2001) function [optimized, +5/-4 matrix (5:-4)] ktup: 6
• join: 48, opt: 33, gap-pen: -16/ -4, width: 16
• Scan time: 3.180
• The best scores are: opt bits E(61164)
• EM_FUN:CGL301988 AJ301988.1 Colletotrichum glo (1484) [f] 1184 88 5.7e-17
• EM_FUN:AF090855 AF090855.1 Colletotrichum gloe ( 500) [f] 1205 88 7.3e-17
• EM_FUN:CGL301986 AJ301986.1 Colletotrichum glo (1484) [f] 1166 87 1.2e-16
• EM_FUN:CGL301908 AJ301908.1 Colletotrichum glo (2868) [f] 1148 87 1.3e-16
• EM_FUN:CGL301909 AJ301909.1 Colletotrichum glo (2868) [f] 1148 87 1.3e-16
• EM_FUN:CGL301907 AJ301907.1 Colletotrichum glo (2867) [f] 1148 87 1.3e-16
• EM_FUN:CGL301919 AJ301919.1 Colletotrichum glo (1171) [f] 1166 87 1.6e-16
• EM_FUN:CGL301977 AJ301977.1 Colletotrichum glo (1876) [f] 1148 86 2e-16
• EM_FUN:CFR301912 AJ301912.1 Colletotrichum fra (2870) [f] 1137 86 2.1e-16
PIC 2014, Shanghai
Case of Use](https://image.slidesharecdn.com/bigopendata-challengesforsmartcity-shanghaipic2014-140522060117-phpapp01/85/Big-open-data-challenges-for-smartcity-PIC2014-Shanghai-13-320.jpg)



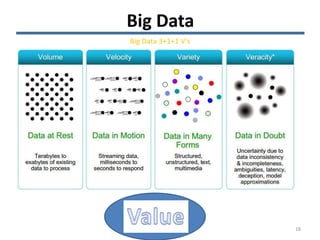


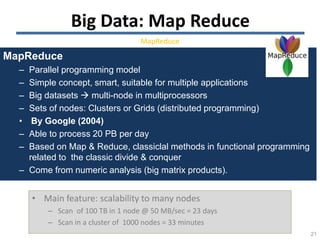






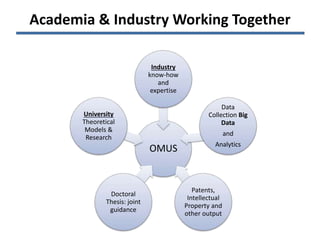




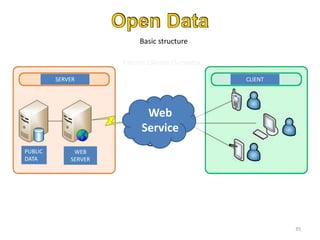
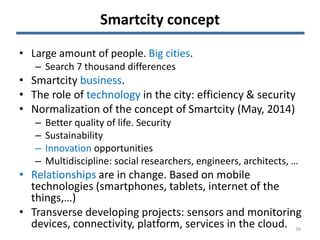


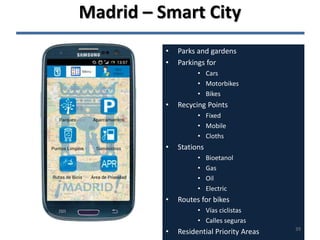

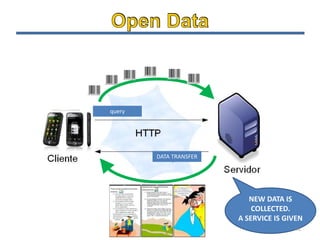

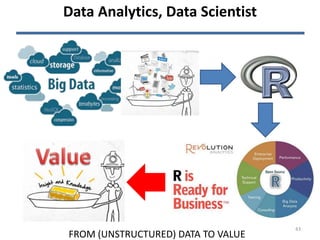





The document discusses the challenges and opportunities associated with big and open data in the context of smart cities, emphasizing the importance of technology transfer and collaboration among various fields. It addresses the need for efficient data management, advanced analytics, and the integration of intelligent systems to enhance urban environments. Finally, it highlights the role of open data in improving citizen engagement and the overall quality of life in metropolitan areas.



































































