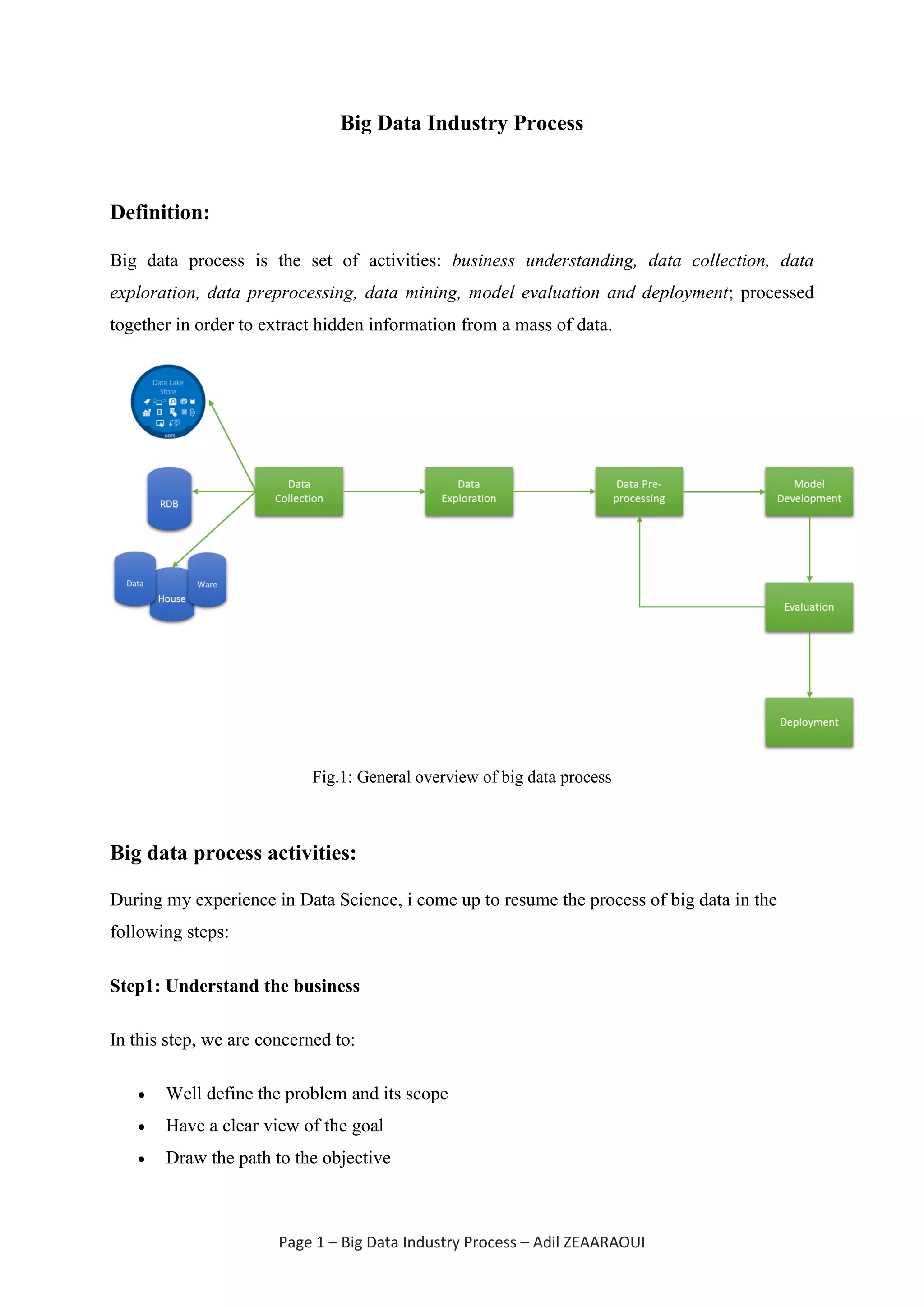
The document outlines the big data industry process, which includes steps such as business understanding, data collection, data exploration, data preprocessing, data mining, and model evaluation and deployment. It emphasizes the importance of each step, particularly data preprocessing, which can account for up to 90% of the overall process. The ultimate goal is to extract valuable insights from large data sets through a systematic approach.













































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




