




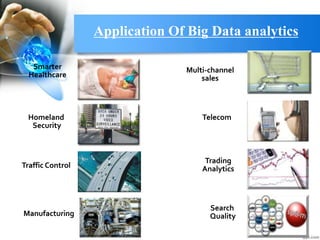

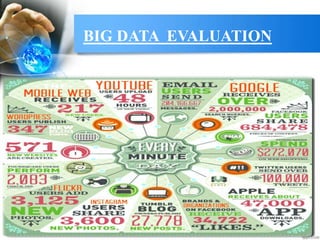
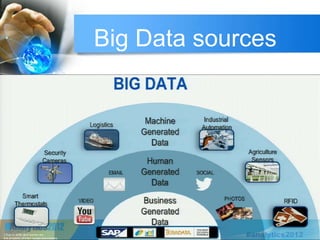





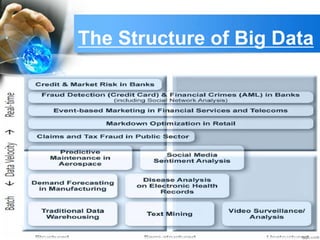











This document provides an overview of big data. It begins with definitions of big data and its key characteristics, including volume, velocity, and variety. It then discusses how big data is stored, selected, and processed. Examples of big data sources and tools are provided. The document outlines several applications of big data across different industries like healthcare, manufacturing, and retail. It also discusses risks of big data like privacy issues and costs. The future of big data is presented, with projections that the big data market will grow significantly in coming years. In closing, references are provided for additional information on big data.








































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)

































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)



