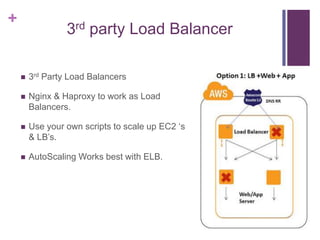
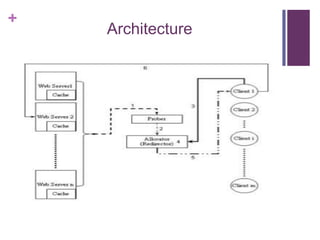
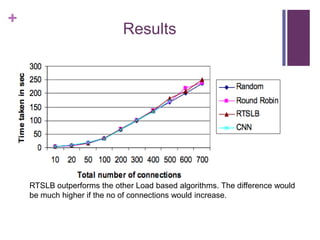
This document discusses designing fault tolerant web services on AWS. It covers motivation for fault tolerance on AWS, inherent fault tolerant AWS components like availability zones and Elastic IPs, and how to implement redundancy using Auto Scaling and Elastic Load Balancing. It then discusses designing high availability at the web/app, load balancing, and database layers, providing options for session synchronization and load balancing. It proposes a new load balancing algorithm that dynamically adapts strategies based on real-time server stats.






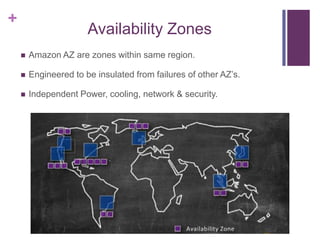
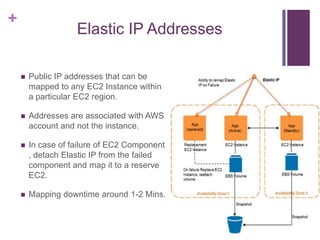

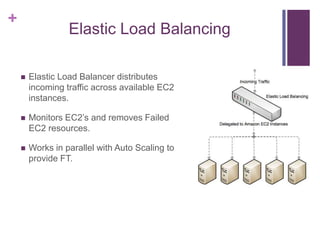



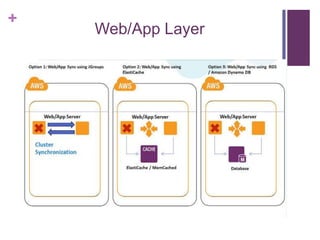
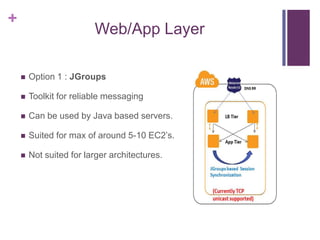
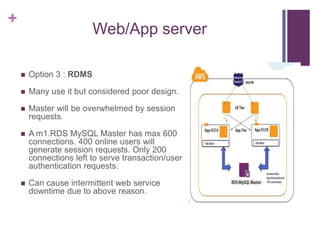
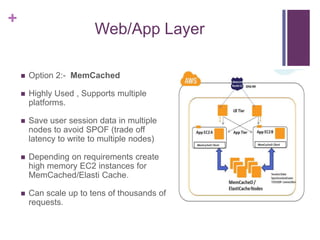

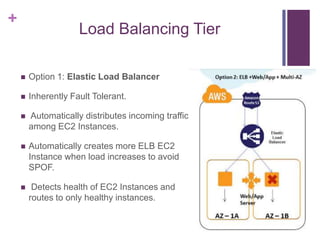
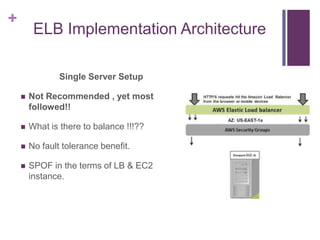
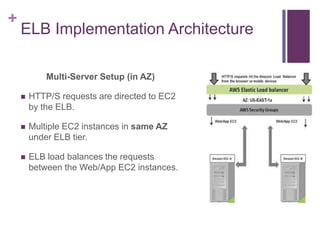

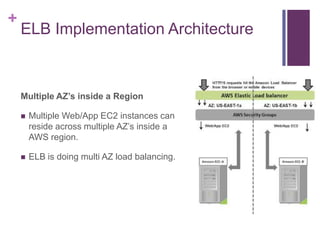
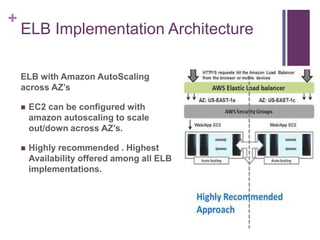































![[Jun AWS 201] Technical Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/aws201general201tworkshop-130708040331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















