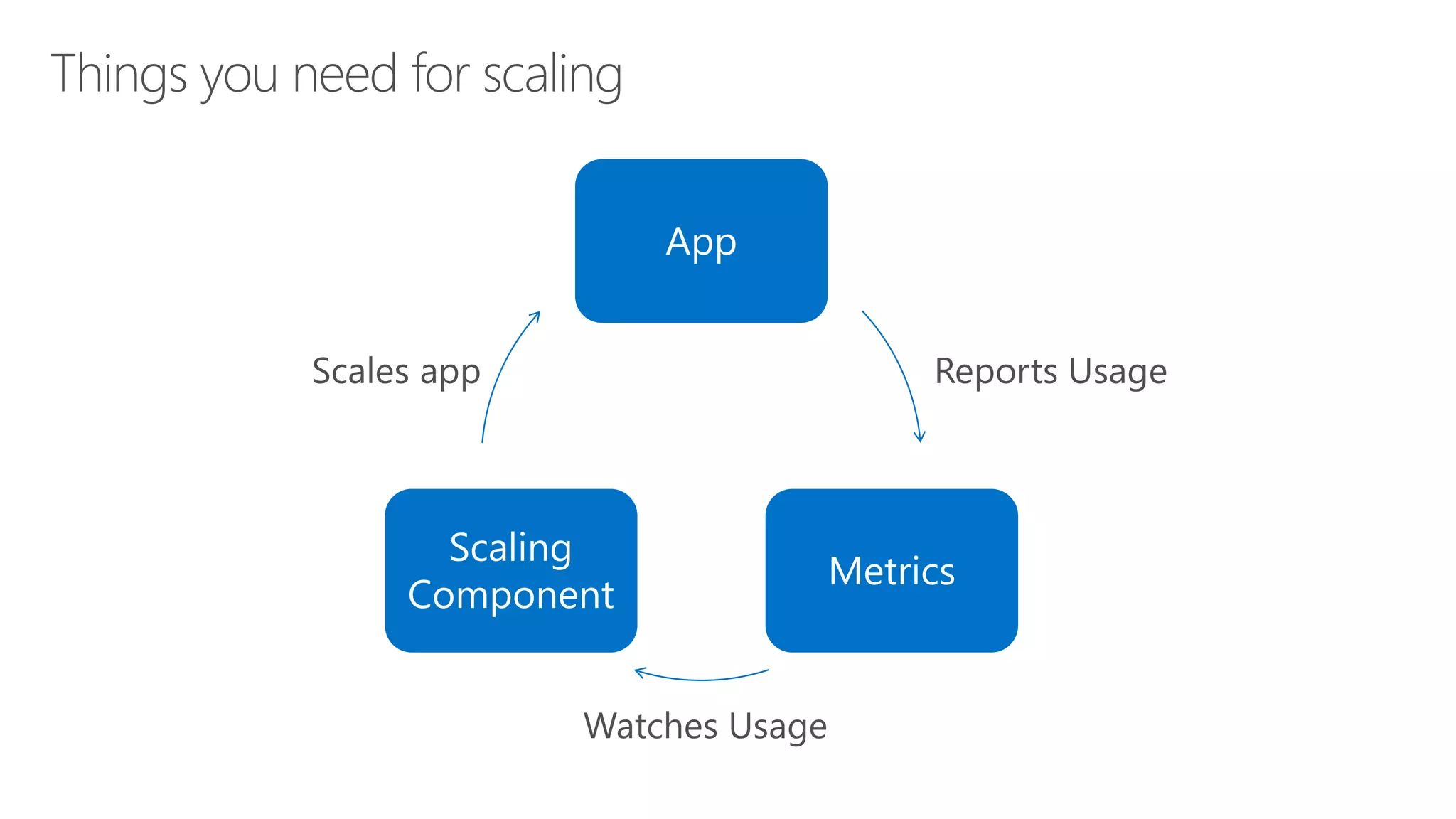
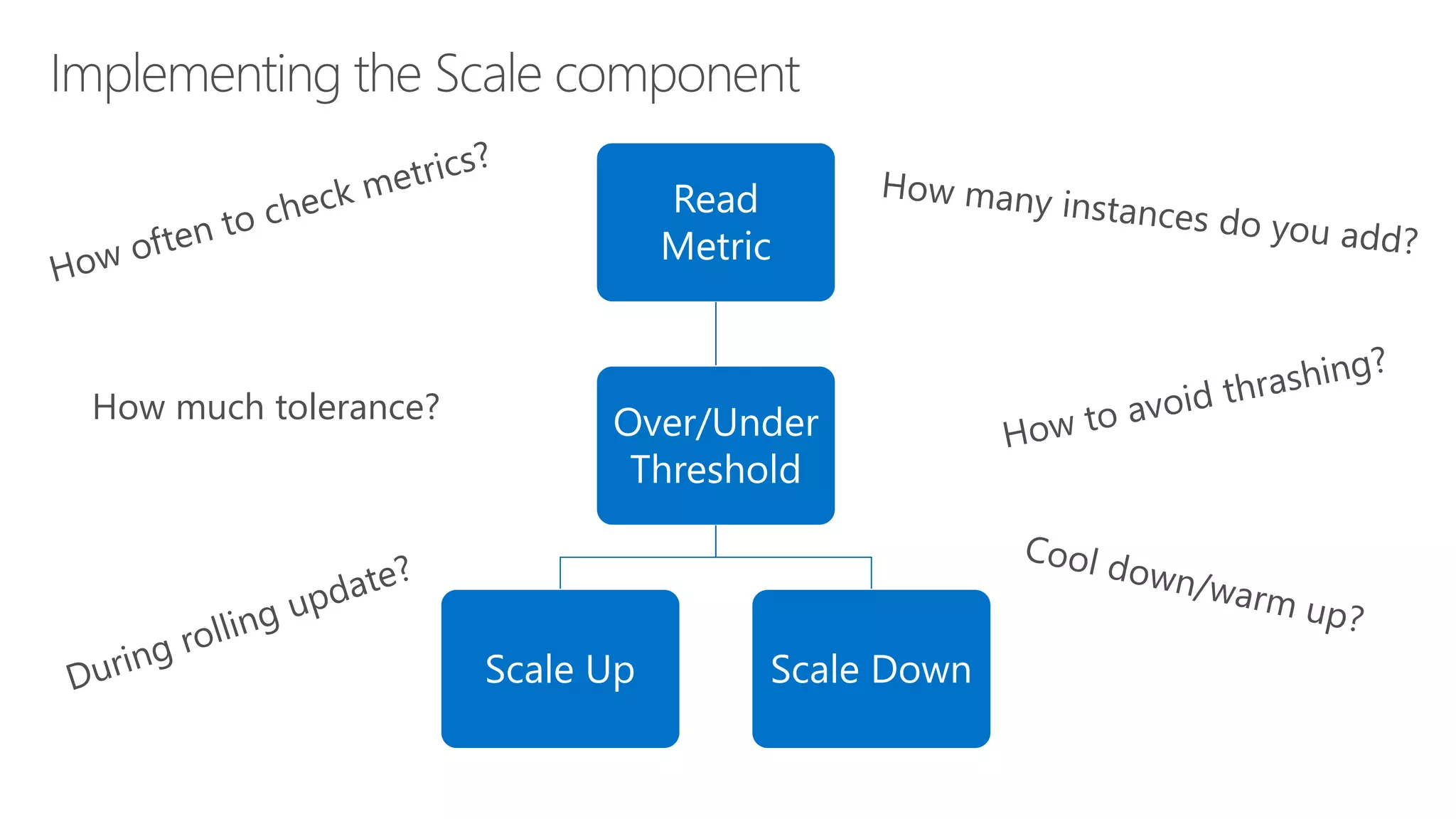
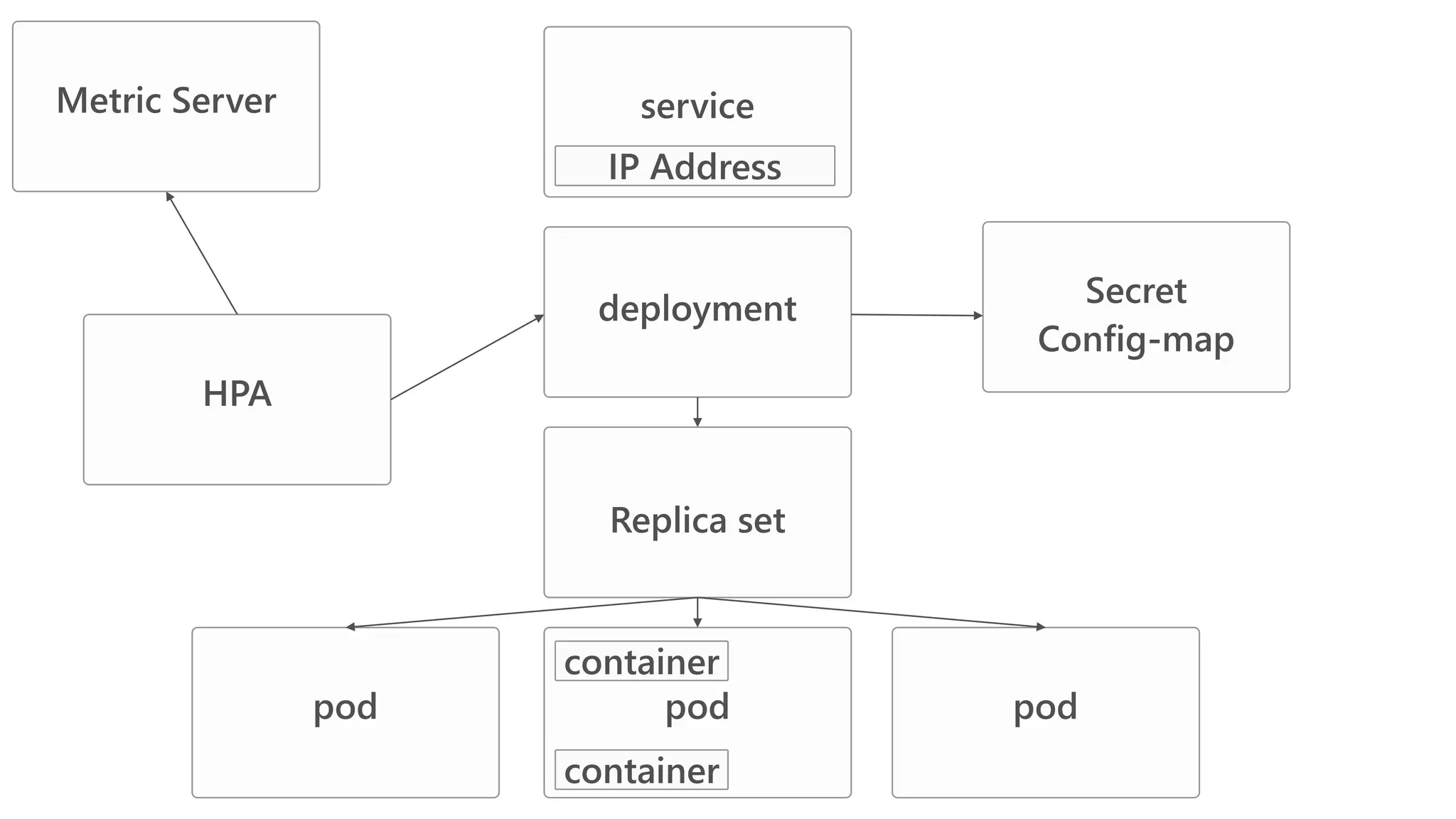
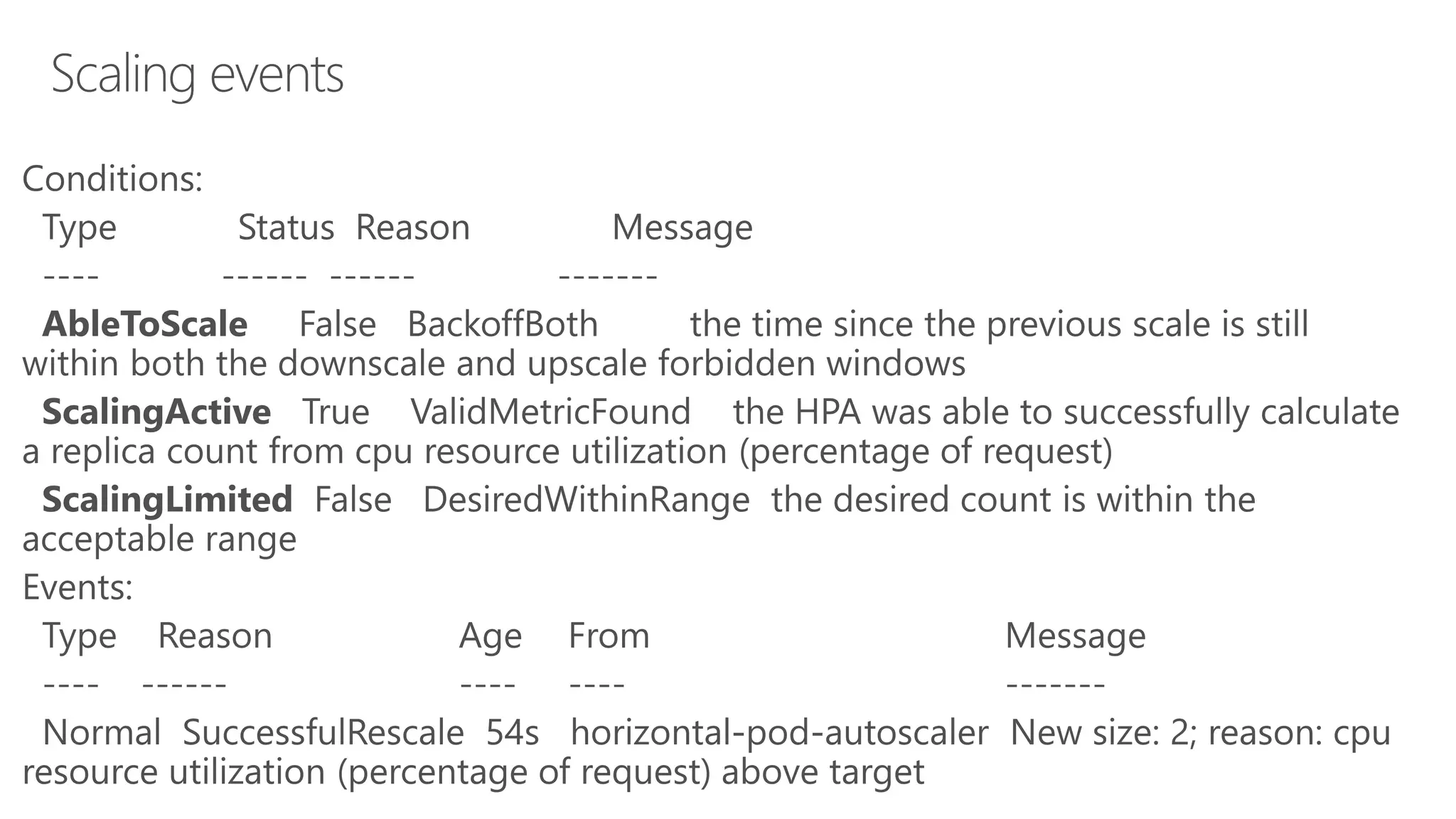
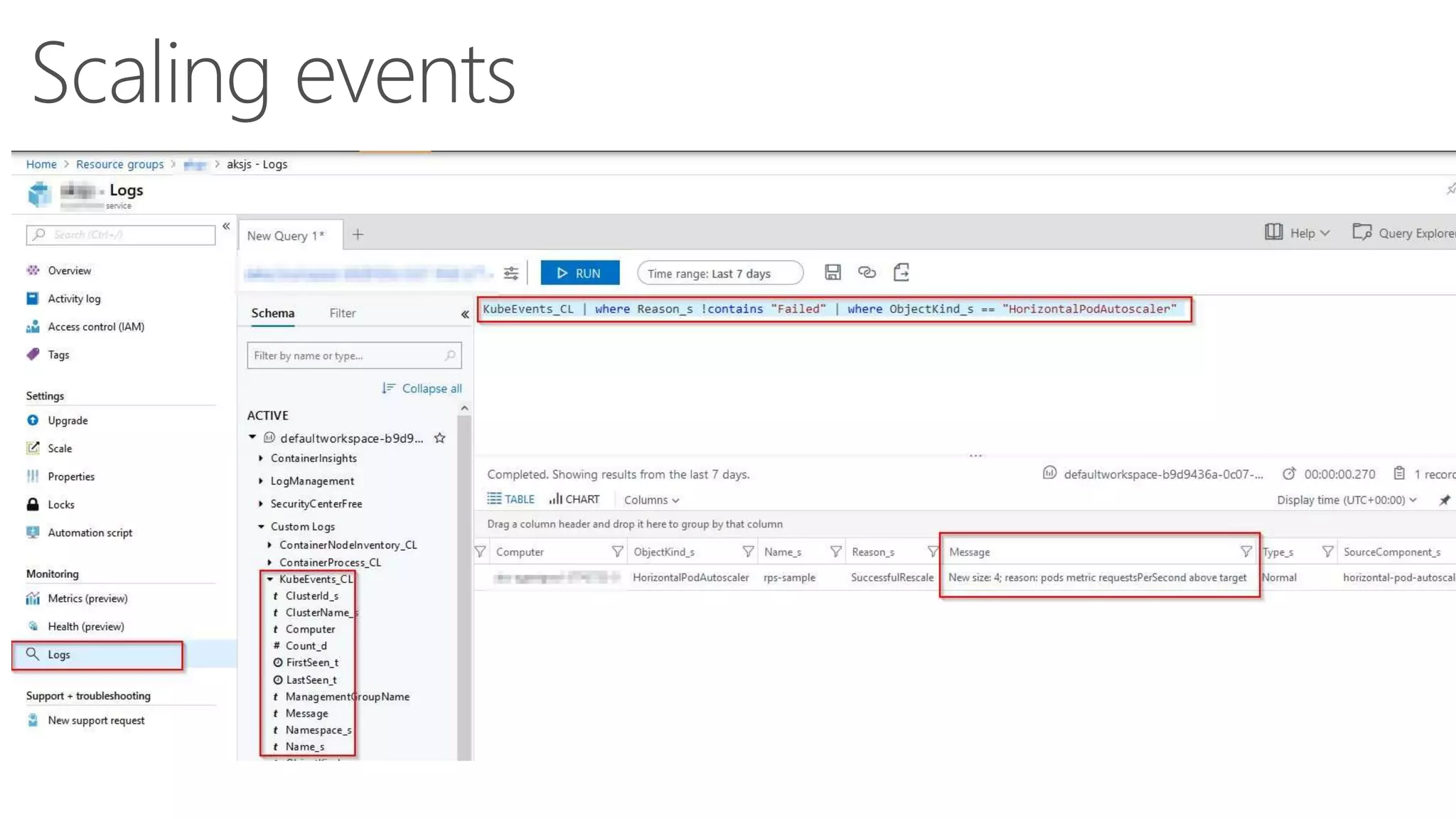
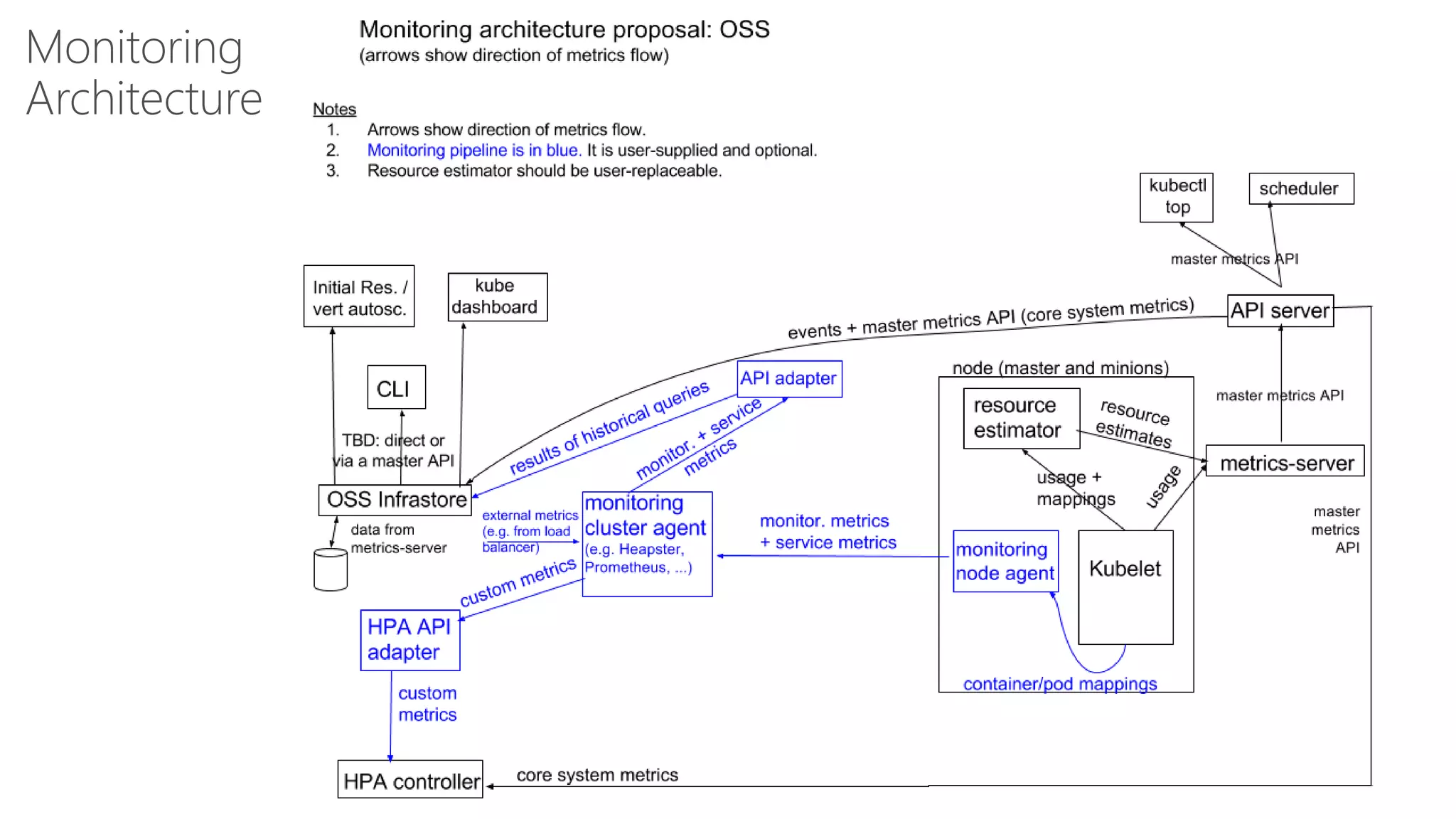
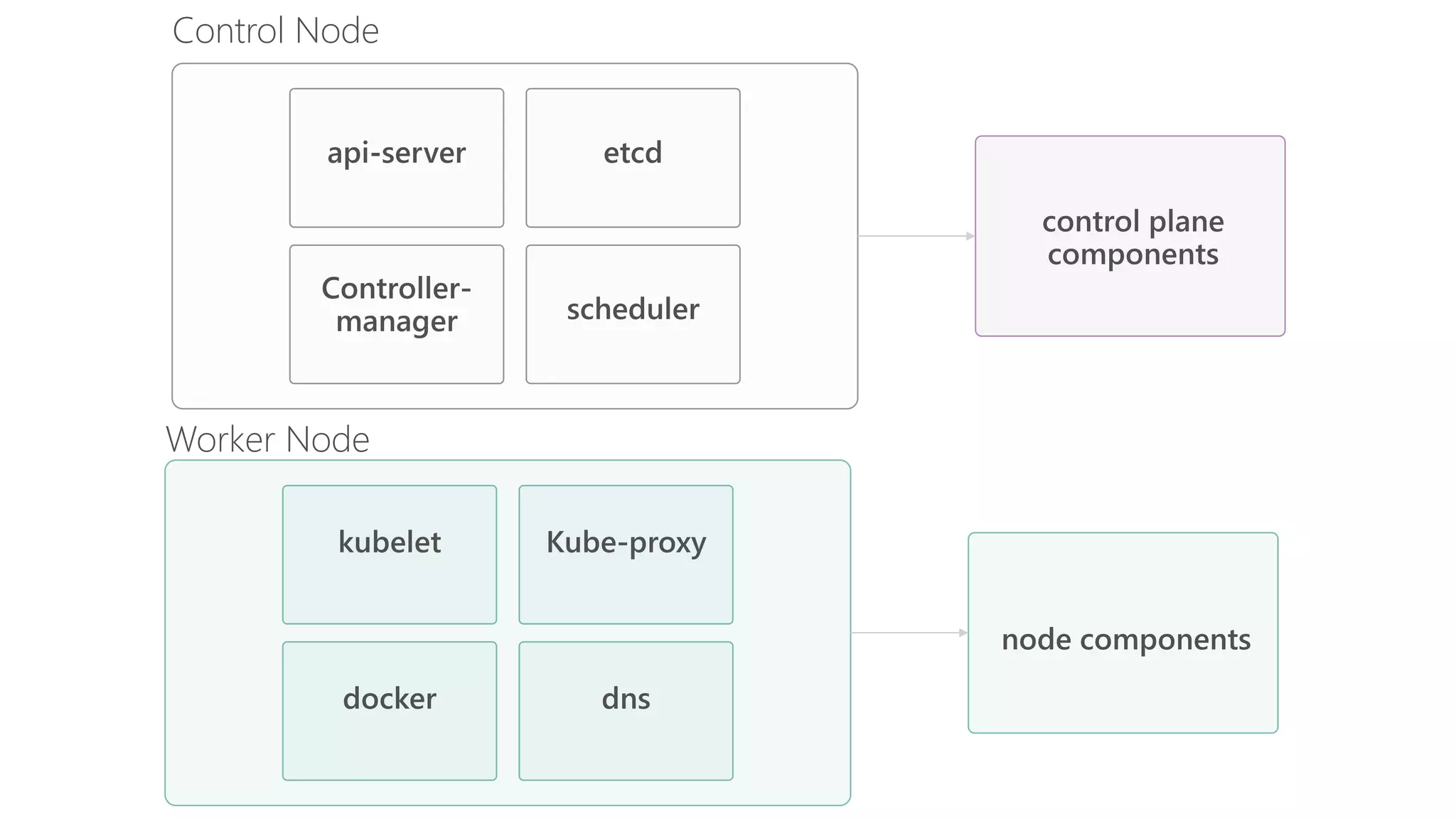
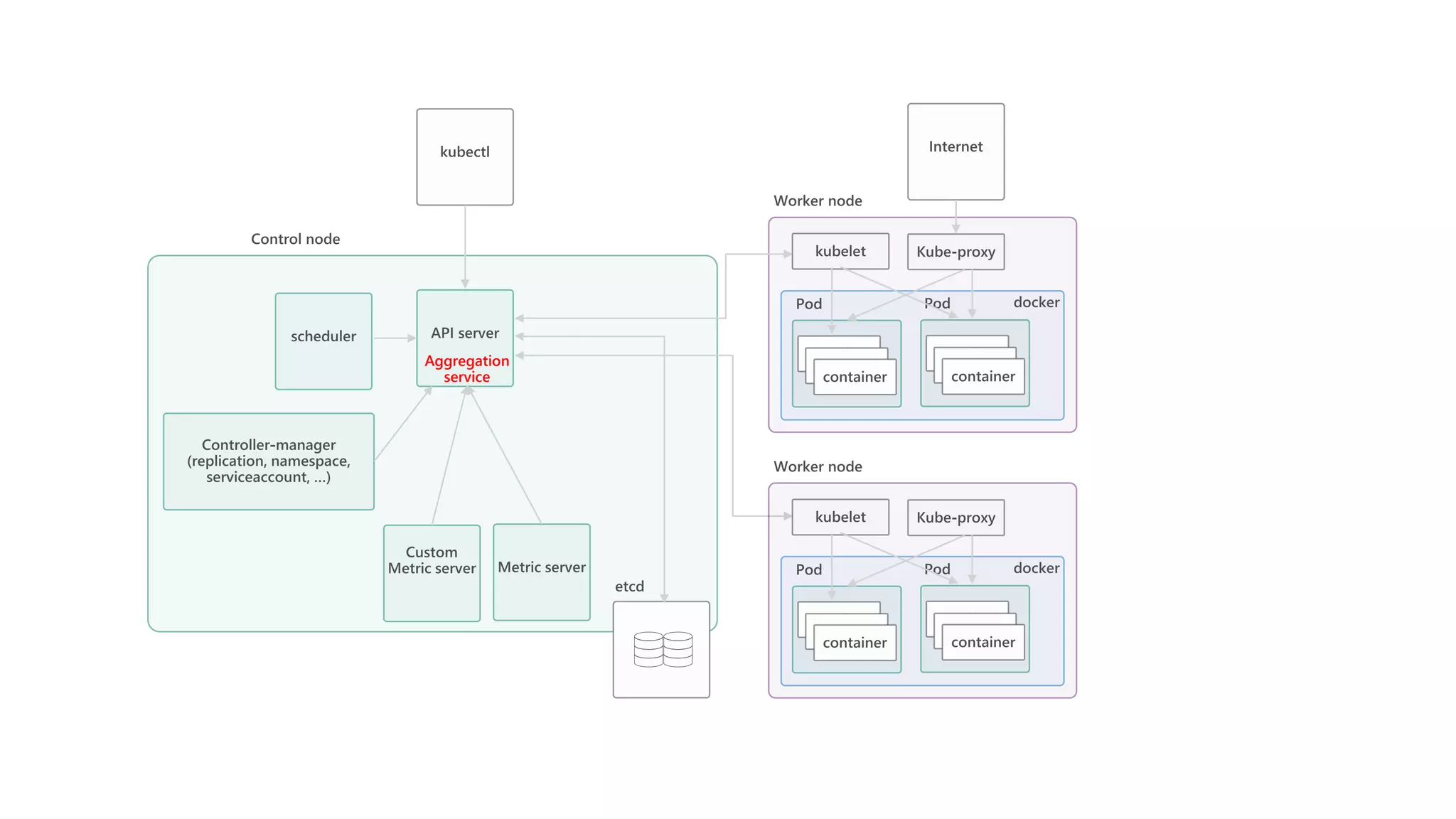
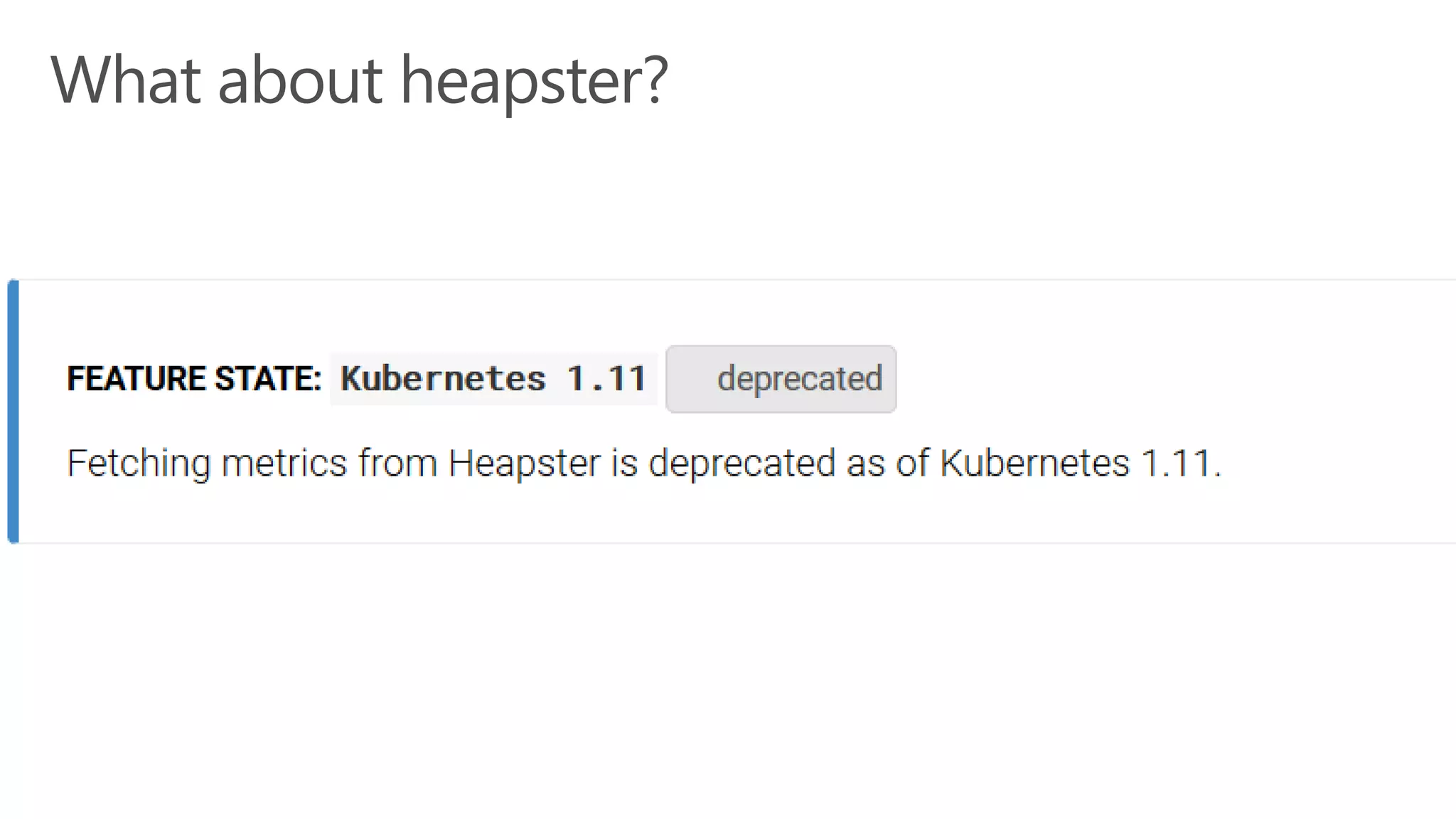
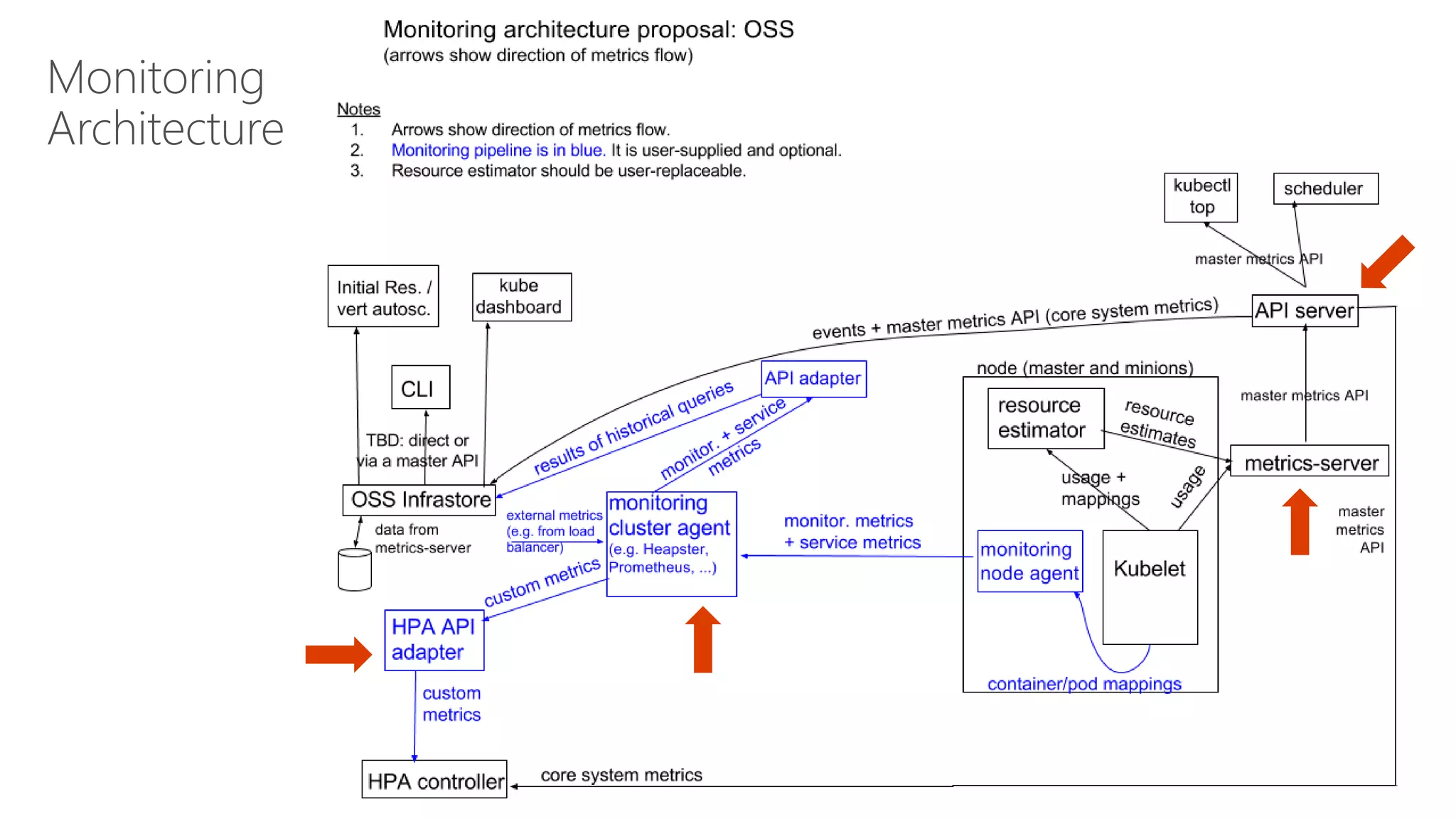
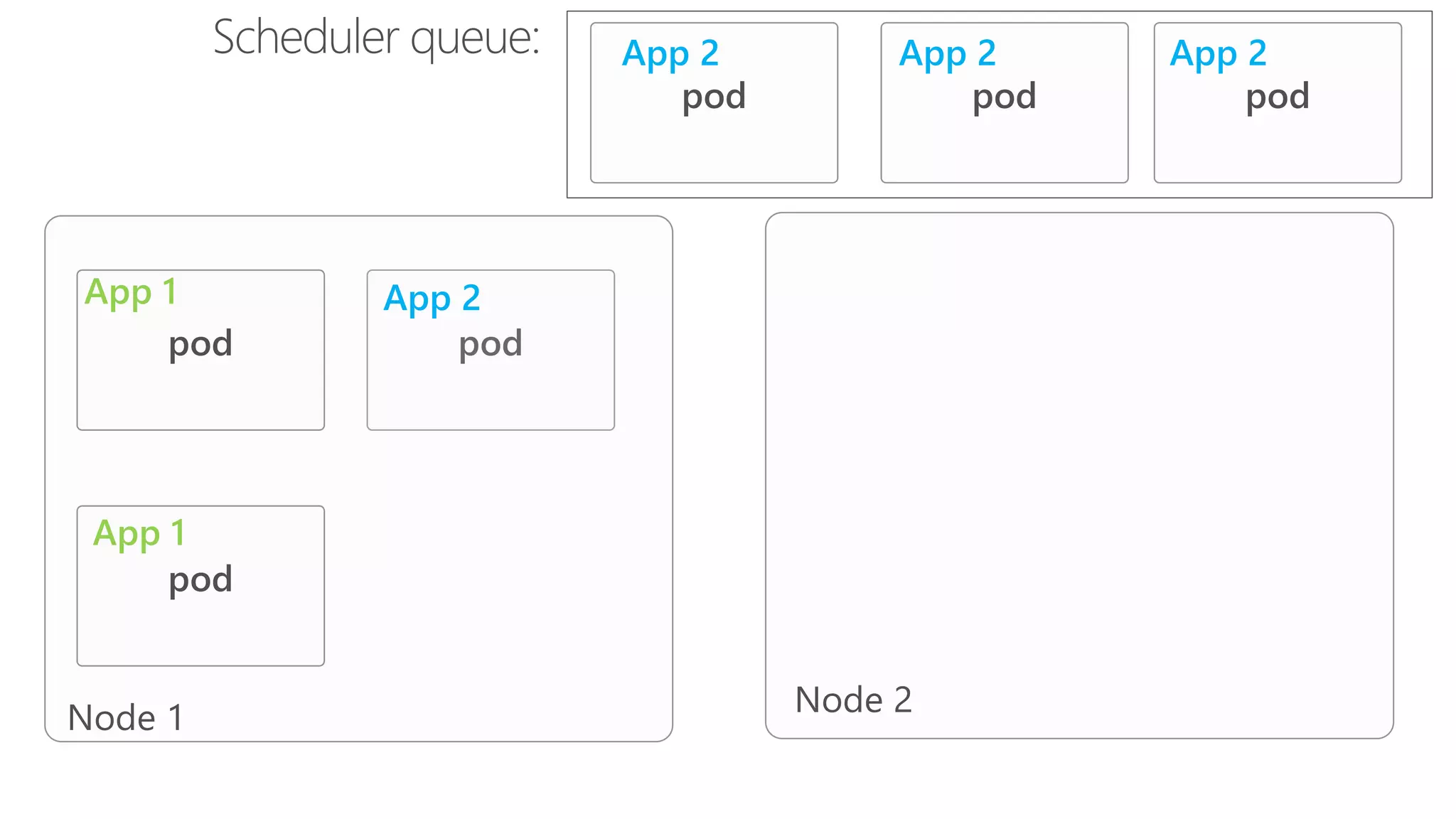
James Sturtevant discusses the implementation of horizontal pod autoscaling in Kubernetes, detailing the API definitions, metrics gathering, and monitoring architecture. He provides a comprehensive overview of scaling processes, including tolerance levels, sync periods, and resource metrics accumulation, as well as references to relevant resources and documentation. The document serves as a guide for developers looking to optimize resource management in cloud environments.