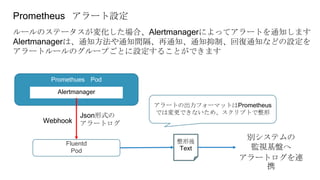
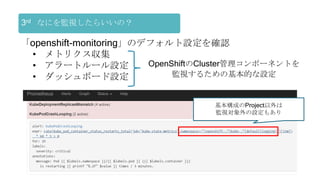
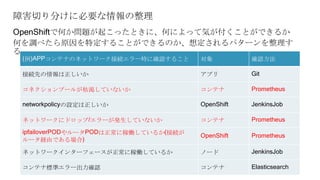
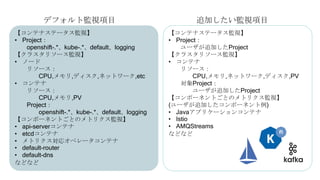
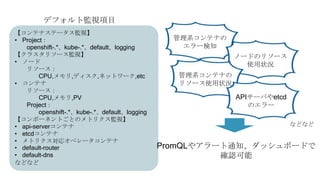
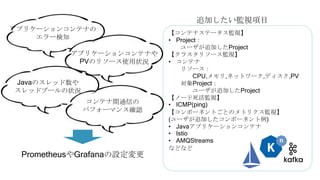
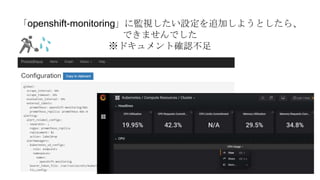
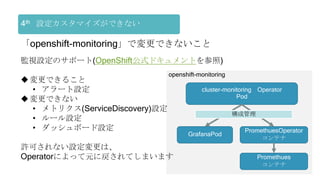
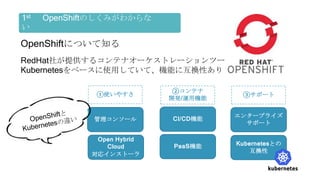
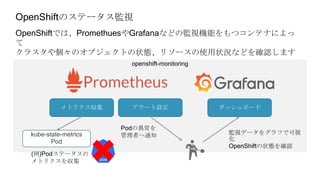
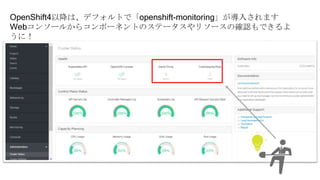
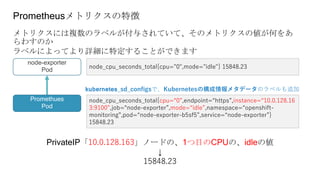
OpenShiftクラスタの基本構成では、openshift-monitoringプロジェクトのコンポーネントによってコンテナ監視を行うことができます。
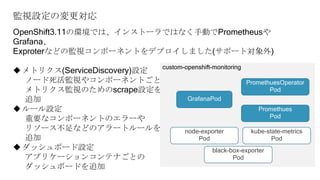
しかし実際に監視をしようとすると、基本構成のPrometheusに対する設定変更に制限があったり、
そもそもどのようなメトリクスを監視するべきか分からないなど、困ったことが沢山ありました。
OpenShift管理初心者が、コンテナ監視で直面した課題やその対処についてお話しさせていただきます。
OpenShift.Run Summer 2020.9.24






![[root@ip-172-31-43-203 ~]# oc apply -f test.yaml
deploymentconfig.apps.openshift.io/frontend created
[root@ip-172-31-43-203 ~]# oc get po -w
NAME READY STATUS RESTARTS AGE
frontend-2-5kldg 0/1 ContainerCreating 0 21s
frontend-2-deploy 1/1 Running 0 31s
frontend-2-n2zrx 0/1 ContainerCreating 0 21s
frontend-2-5kldg 1/1 Running 0 64s
frontend-2-n2zrx 1/1 Running 0 64s
frontend-2-deploy 0/1 Completed 0 75s
Manifest
test.yaml
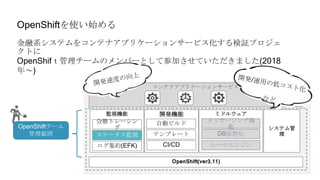
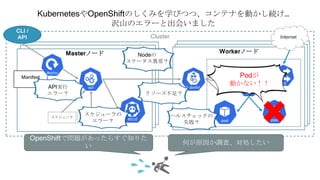
OpenShiftがなんだかよくわからないまま、コンテナのYAMLファイルをつくってコマンド
実行したら
コンテナが増えて、STATUSは「Running」だし何だかすごい!!
でもひとたびエラーが起こると、何をしたらいいのか全くわかりません
コントローラスケジューラ
ぜんぶ
おまじないの
世界](https://image.slidesharecdn.com/cluster-monitoringstudy-200925011333/85/cluster-monitoring-8-320.jpg)



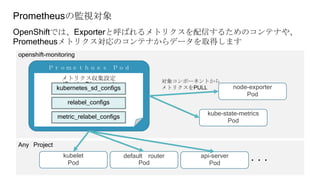

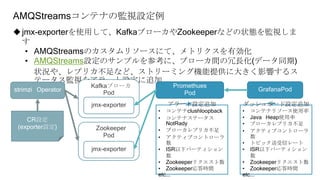
![メトリクスのラベル設定
「relabel_configs」では、ターゲットからメトリクスを取得する前に、ターゲッ
トに関する
ラベル設定を操作して、取得対象を変更したり、絞り込んだりすることができる
scrape_configs:
- job_name: openshift-monitoring/node-exporter/0
~~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_k8s_app]
separator: ;
regex: node-exporter
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
separator: ;
regex: https
replacement: $1
action: keep
~~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~~~~~
サービス名をあらわすラベルが「node-exporter」である
メトリクスだけを取得する
サービスのエンドポイント名が「https」であるメトリクス
だけを取得する](https://image.slidesharecdn.com/cluster-monitoringstudy-200925011333/85/cluster-monitoring-19-320.jpg)