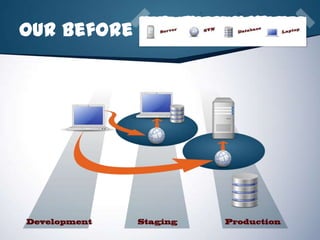
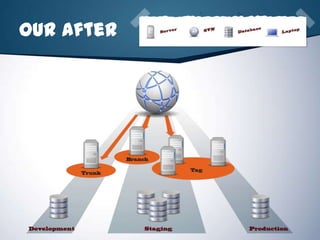
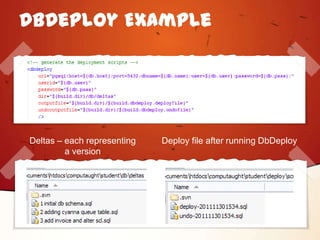
The document is a presentation by Joey Rivera on using Phing, an XML-based build tool written in PHP, to automate manual processes in software development, thereby reducing time and errors. It covers installation, usage, and various features like task management, property organization, and examples of implementation including version control, packaging, testing, documentation, and deployment. The presentation also highlights the benefits of automating processes with Phing and includes links to resources for further information.