Download as PDF, PPTX
















![#AutomationSummit
Interested In Learning More?
Flink SQL Cookbook
The Github Source for Flink
SQL Demo
The GitHub Source for Demo
Manning's Apache Pulsar in
Action
O’Reilly Book
[11/18] Developer Week Austin
[11/19] Porto Tech Hub Con
[12/3] Data Science Camp
Resources Free eBooks Upcoming Events](https://image.slidesharecdn.com/automationdevopssummit-hailhydratefromstreamtolake-211115172114/75/Automation-dev-ops-summit-hail-hydrate-from-stream-to-lake-30-2048.jpg)



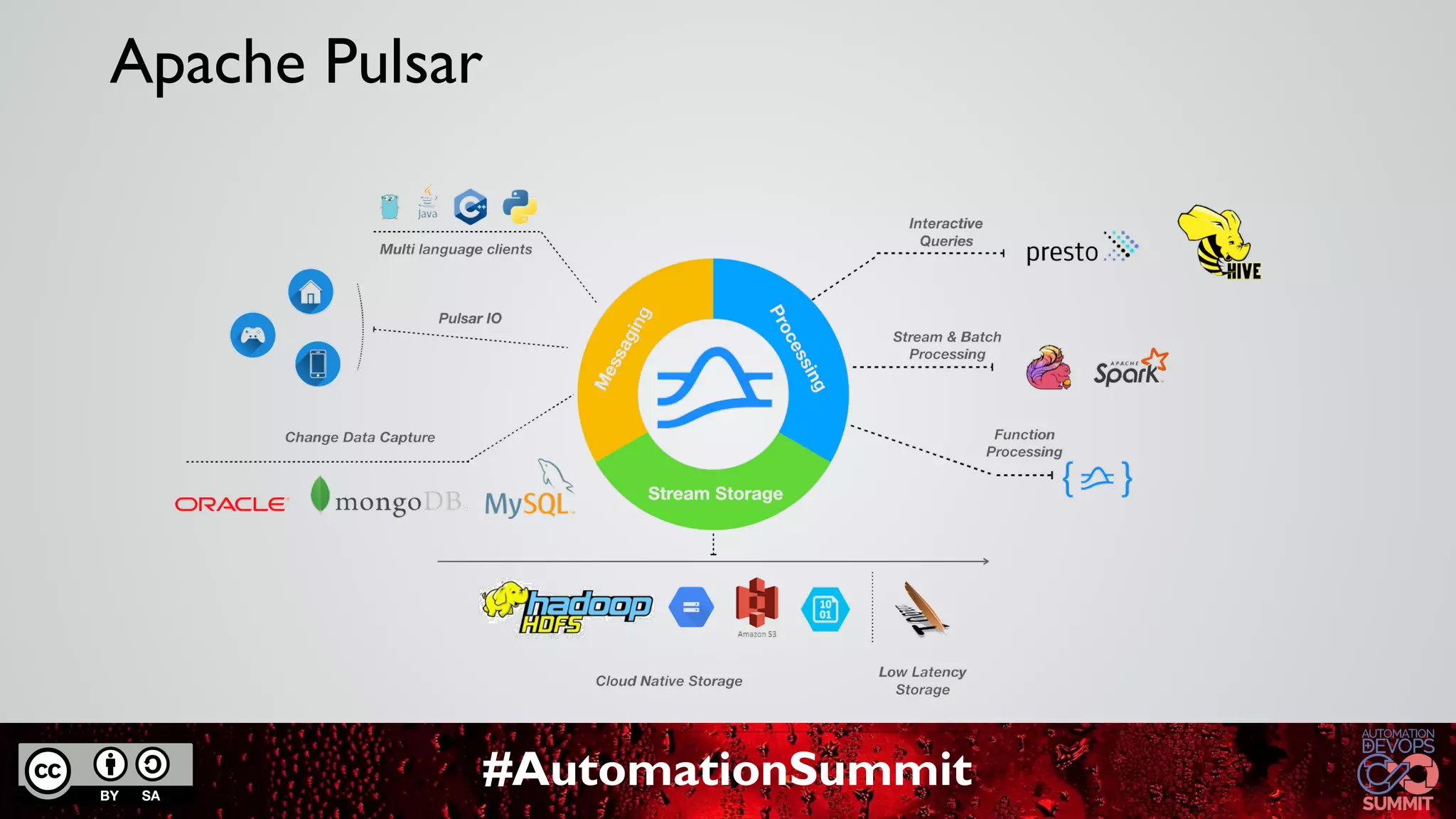
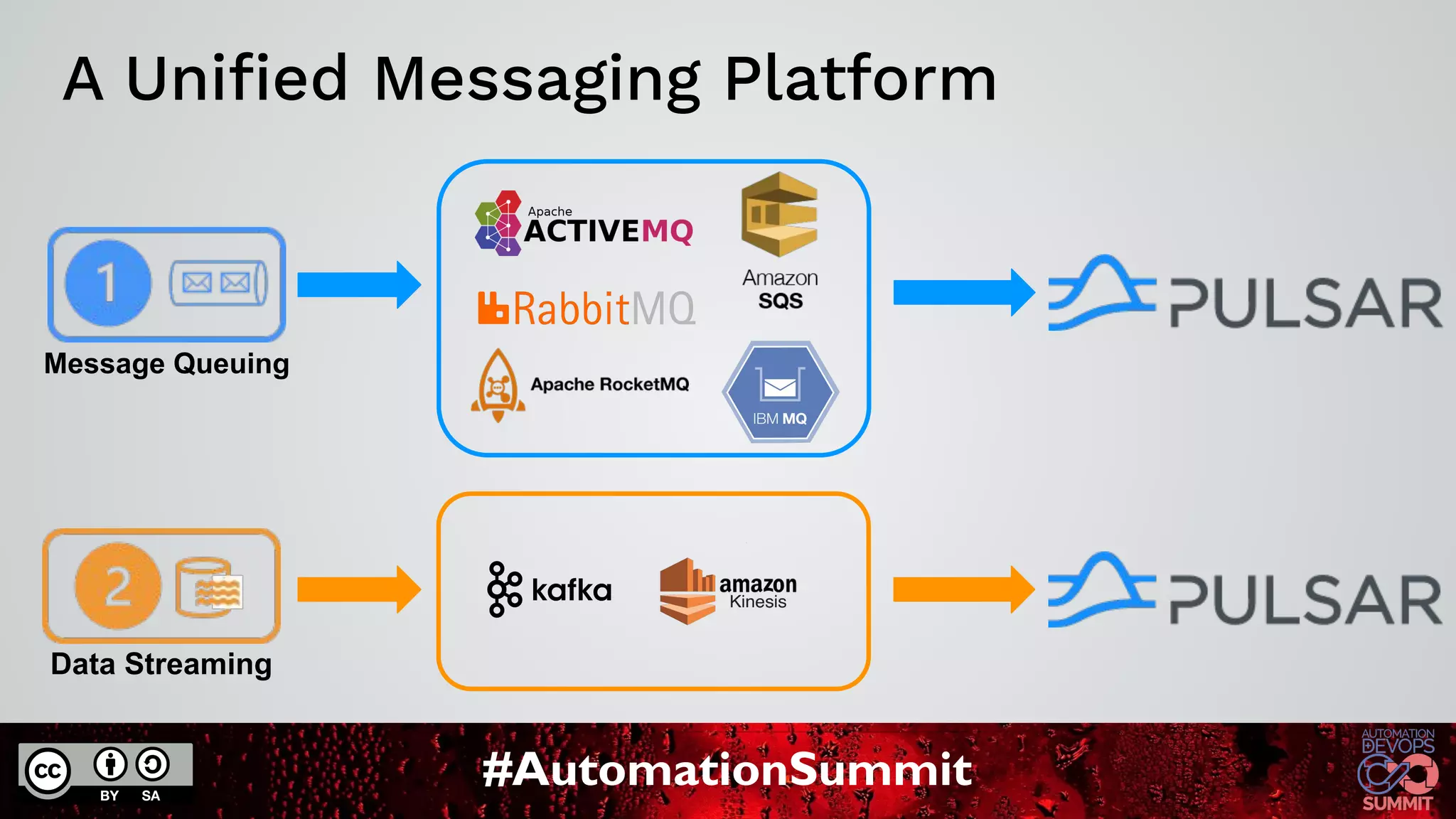
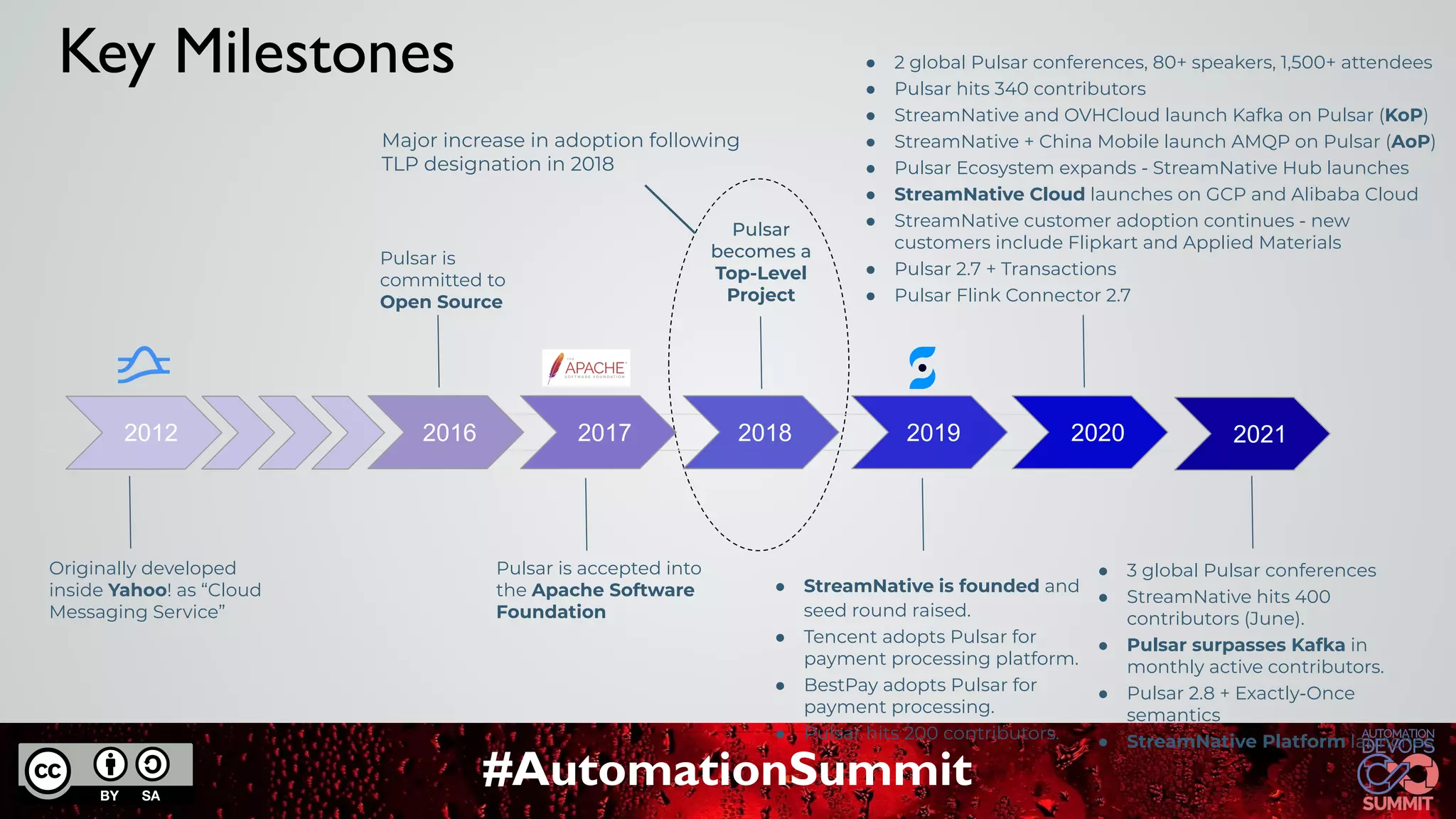
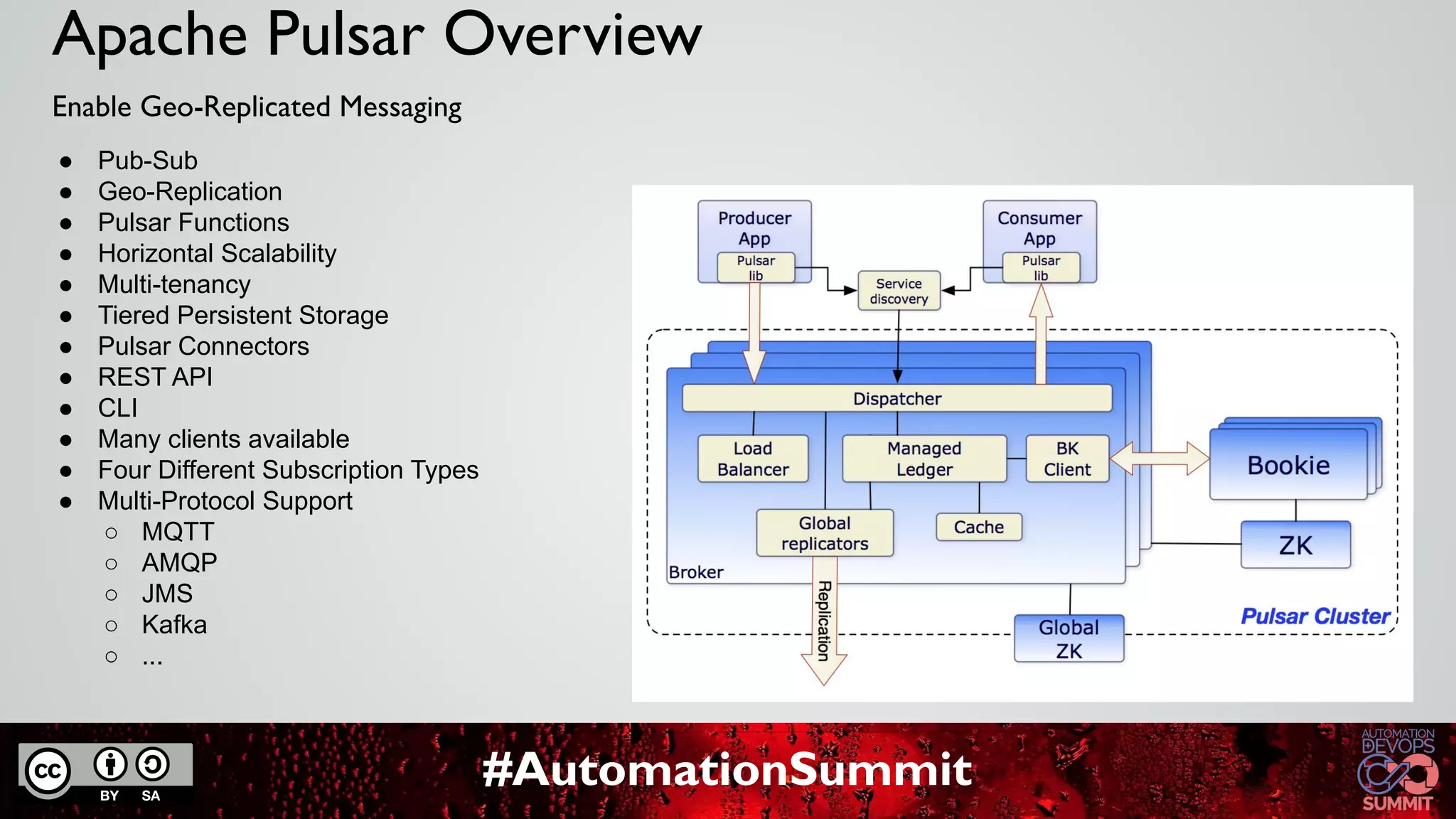
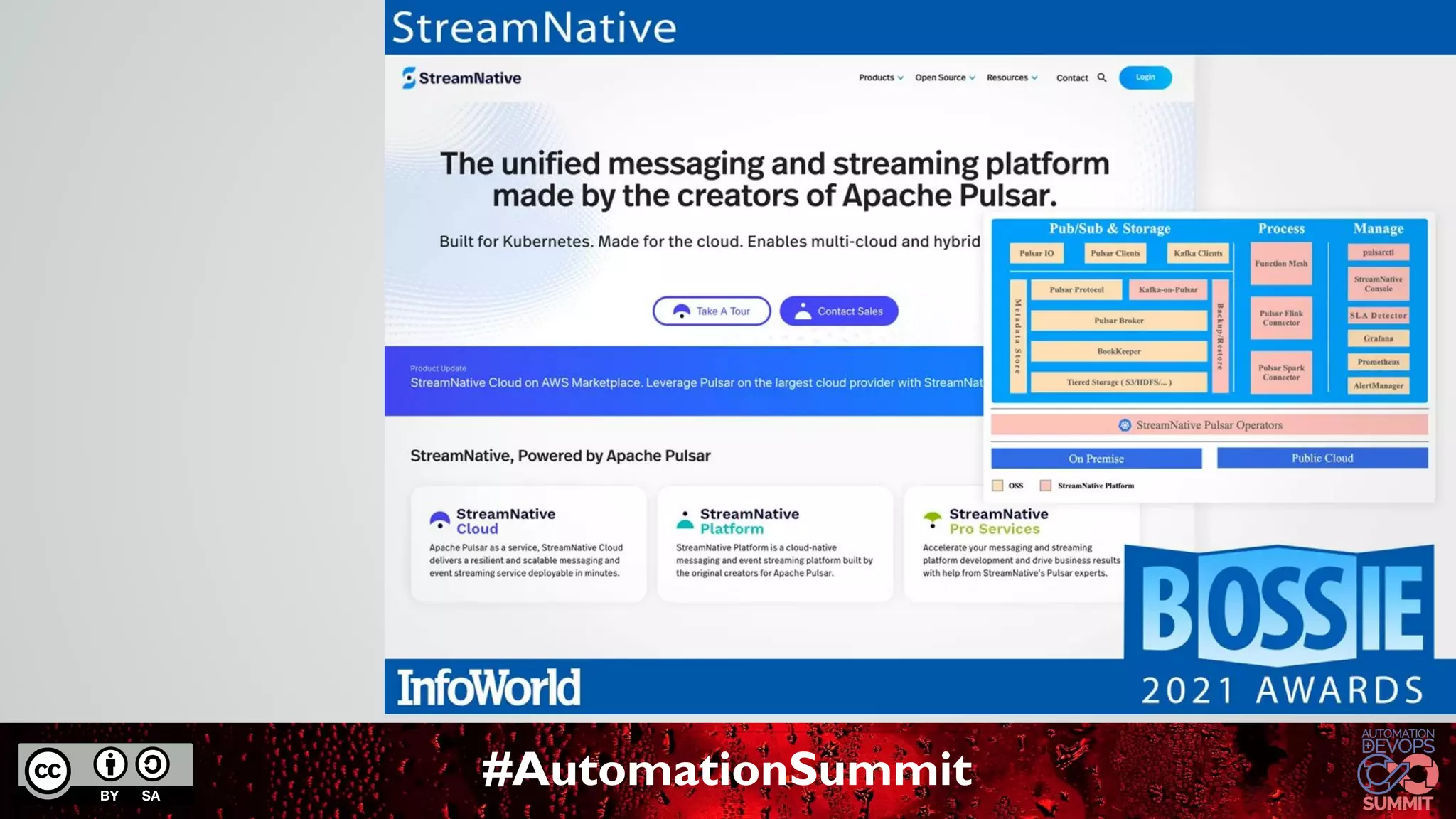
The document discusses Apache Pulsar, a cloud-native event streaming platform originally developed at Yahoo, which enables real-time data access with features like data durability, geo-replication, and a unified messaging model. It highlights key milestones in Pulsar's development, the architecture of its ecosystem, and its growing adoption in various industries. StreamNative provides a cloud-native messaging solution built on Pulsar, supporting multi-cloud strategies and advanced features for real-time analytics and data processing.









![[March sn meetup] apache pulsar + apache nifi for cloud data lake](https://cdn.slidesharecdn.com/ss_thumbnails/marchsnmeetupapachepulsarapachenififorclouddatalake-220311125943-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[AerospikeRoadshow] Apache Pulsar Unifies Streaming and Messaging for Real-Ti...](https://cdn.slidesharecdn.com/ss_thumbnails/aerospikeroadshowapachepulsarunifiesstreamingandmessagingforreal-timedata2-221103174214-18ce3fa2-thumbnail.jpg?width=640&height=640&fit=bounds)











































