Downloaded 24 times





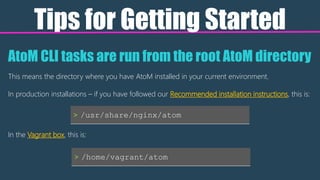

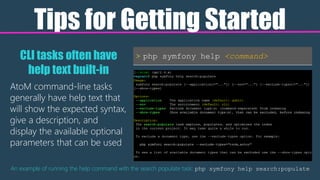


















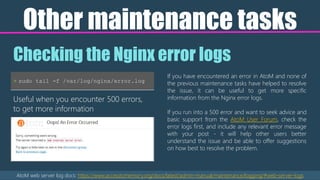


The document serves as an introduction to Atom's command line interface (CLI) tools, detailing their usage for maintenance, troubleshooting, and efficiency improvements. It includes video tutorials, key commands for tasks such as repopulating search indexes and generating slugs, as well as advice on installation locations and command structure. Additionally, it emphasizes the importance of learning CLI for better application understanding and community support.




















































































