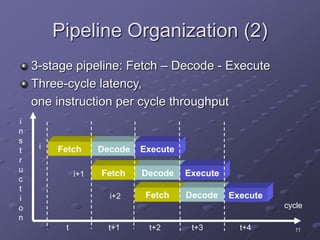
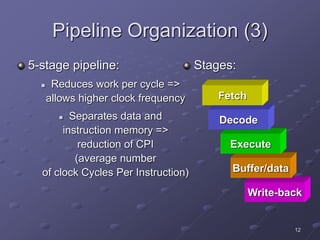
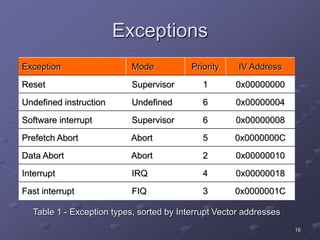
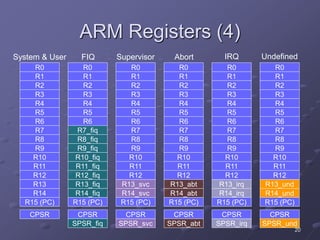
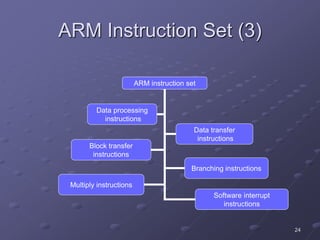
ARM is a RISC microprocessor architecture developed in the 1980s that is widely used in embedded systems. It has a simple design which allows for small, low-power implementations. ARM has become the dominant architecture for embedded applications due to its architectural simplicity, low power consumption, and high performance. The ARM instruction set includes data processing, data transfer, and branching instructions. It has undergone numerous revisions over time to improve performance and functionality.