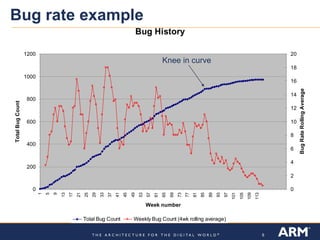
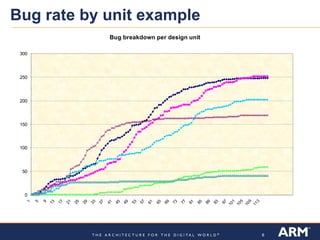
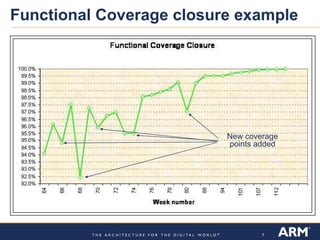
Verification metrics are important for predicting the functional closure of a CPU design project and avoiding schedule delays and cost overruns. There are two key types of metrics: verification test plan-based metrics like the amount of testing completed and assertions written, and health of the design metrics like simulation passing rates and bug rates. Both have limitations and challenges, such as test plans growing over time and needing historical data for comparisons. Metrics should be used carefully along with other factors, as focusing only on metrics could influence behaviors and historical data may mislead.