Arbitrary style transfer in real time with adaptive instance normalization
1.
Arbitrary Style Transferin Real-time
with Adaptive Instance Normalization
Neural Style Transfer
Xun Huang and Serge Belongie
Department of Computer Science & Cornell Tech, Cornell University
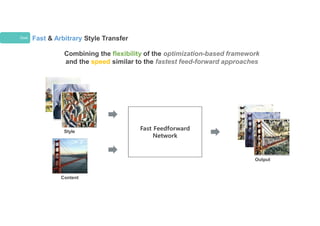
Previous Work Slow& Arbitrary Style Transfer
Loss Network
(VGG)
Style
Content
Output
Content Loss
Style Loss
Gatys et al., CVPR 2016
Li and Wand, CVPR 2016
Up to minutes
Optimization-based Framework - Flexibility
4.
Previous Work Fast& Restricted Style Transfer
Fast Feed Forward
Network
Content
Output
Ulyanov et al., ICML 2016
Johnson et al., ECCV 2016
Li and Wand, ECCV 2016
Model A
Fast Feed Forward
Network
Model B
Fast Feed Forward
Network
Model C
>20 FPS
Feed-forward Approaches – Speed
Inspired by BatchNormalization Vs. Instance Normalization
Batch Normalization (BN) Instance Normalization (IN)
데이터로부터 학습 데이터로부터 학습
7.
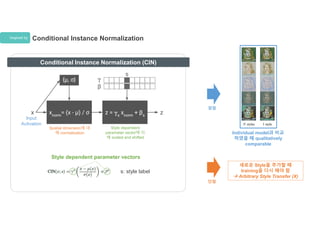
Inspired by ConditionalInstance Normalization
Conditional Instance Normalization (CIN)
Style dependent parameter vectors
s: style label
Input
Activation
Spatial dimension에 대
해 normalization
Style dependent
parameter vector에 의
해 scaled and shifted
새로운 Style을 추가할 때
training을 다시 해야 함
Arbitrary Style Transfer (X)
Individual model과 비교
하였을 때 qualitatively
comparable
장점
단점
8.
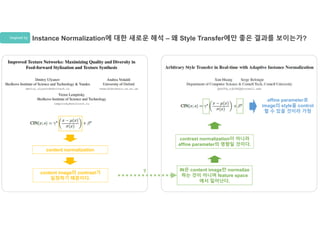
Inspired by InstanceNormalization에 대한 새로운 해석 – 왜 Style Transfer에만 좋은 결과를 보이는가?
content normalization
content image의 contrast가
일정하기 때문이다.
IN은 content image만 normalize
하는 것이 아니며 feature space
에서 일어난다.
contrast normalization이 아니라
affine parameter의 영향일 것이다.
affine parameter로
image의 style을 control
할 수 있을 것이라 가정
?
9.
Inspired by InstanceNormalization에 대한 새로운 해석 – 실험 및 증명
IN이 BN보다 빠르게 converge 한다.
모든 training image의 content를 같은 contrast를 가
지도록 histogram equalization
여전히 IN이 BN에 비해 빠르게
converge 함.
content normalization 때문에 style transfer
가 잘 되는 것이 아니다.
모든 training image를 같은 style로 normalize하였더
니 BN과 IN의 차이가 줄었다.
(Target Style과는 다르도록 함)
IN이 Style Normalization효과를 준다
는 사실을 입증
BN이 덜 수렴하는 이유는 batch단위로
style normalization을 하였기 때문
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Histogram
Equalization
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Pretrained
style
transfer
network [24]
content
normalization style
normalization
10.
Method Adaptive InstanceNormalization
content input
style input
style input으로 affine
parameter를 계산
normalized content image
affine parameter로 각 style 별로 다르
게 normalization하여 style을 구분
11.
Method Architecture
content
image
style
image
f(c): contentfeature
f(s): style feature
content feature의 mean과 standard deviation
을 style feature map에 align한다.
t: target feature map
AdaIN
Decoder
Feature map t를 image space로 돌려놓
는 역할
stylized image decoder
nearest up-sampling
IN이나 BN을 사용하지 않음 (사용하면 하
나의 style만 생성하게 됨)
12.
Method Training
content
image
style
image
MS-COCO Data(8만개)
WikiArt (약 80,000개)
Crop
(256x256)
Rescale
(512)
Pre-processing
짧은 면이 512
가 되도록
random하게
crop
Content Loss
target과 output image의
feature간 Euclidean distance
AdaIN의 output인 t를 content
target으로 함 convergence
가 약간 더 빠름
Style Loss
relu1_1, relu2_1, relu3_1, relu4_1에서의 mean과 Std. Dev. 차이
Style feature의 mean과 standard deviation만 이용하기 때문에 mean과 standard deviation
으로 loss를 구함
Gram Matrix와 결과가 유사
13.
Results Qualitative Examples
ArbitraryStyle
Transfer
Single style
Fast
Flexible Style
Slow
Flexible style
Medium
Single style model이므로 test
style이 학습되어 있는 케이스
전반적으로 나쁜 결과를 보임
유사한 결과
결과가 약간 떨어짐
14.
Results Quantitative Evaluations& Speed Analysis
Flexible Style
Slow
Single style
Fast
Arbitrary Style
Transfer
Arbitrary Style Transfer
Flexible Style Slow
Single style Fast
Flexible style Medium
32 styles Fast
15.
Experiments [AdaIN Vs.Concatenation] & [BN or IN in the Decoder]
AdaIN
Concatenation
Conc
at
Style image의
object contour
가 보임
Style loss는 낮
지만 content
loss가 높음
Decoder에서
사용시 IN이
image를 single
style로
normalize함





![Inspired by Instance Normalization에 대한 새로운 해석 – 실험 및 증명
IN이 BN보다 빠르게 converge 한다.
모든 training image의 content를 같은 contrast를 가
지도록 histogram equalization
여전히 IN이 BN에 비해 빠르게
converge 함.
content normalization 때문에 style transfer
가 잘 되는 것이 아니다.
모든 training image를 같은 style로 normalize하였더
니 BN과 IN의 차이가 줄었다.
(Target Style과는 다르도록 함)
IN이 Style Normalization효과를 준다
는 사실을 입증
BN이 덜 수렴하는 이유는 batch단위로
style normalization을 하였기 때문
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Histogram
Equalization
Training
Image
Improved Texture
Networks [52]
(BN)
Improved Texture
Networks [52]
(IN)
Pretrained
style
transfer
network [24]
content
normalization style
normalization](https://image.slidesharecdn.com/arbitrarystyletransferinreal-timewithadaptiveinstancenormalization-180416013451/85/Arbitrary-style-transfer-in-real-time-with-adaptive-instance-normalization-9-320.jpg)





![Experiments [AdaIN Vs. Concatenation] & [BN or IN in the Decoder]
AdaIN
Concatenation
Conc
at
Style image의
object contour
가 보임
Style loss는 낮
지만 content
loss가 높음
Decoder에서
사용시 IN이
image를 single
style로
normalize함](https://image.slidesharecdn.com/arbitrarystyletransferinreal-timewithadaptiveinstancenormalization-180416013451/85/Arbitrary-style-transfer-in-real-time-with-adaptive-instance-normalization-15-320.jpg)






![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[CVPR'22] Domain Generalization via Shuffled Style Assembly for Face Anti-Spo...](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr22domaingeneralizationviashuffledstyleassemblyforfaceanti-spoofing-230404065903-720fcc8d-thumbnail.jpg?width=640&height=640&fit=bounds)