Downloaded 49 times


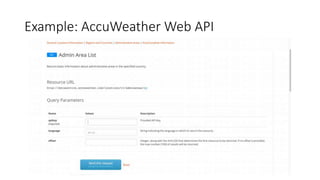
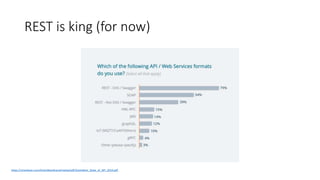
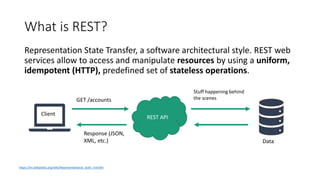




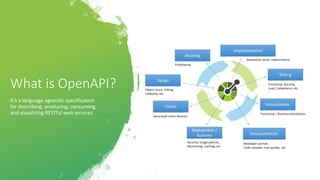
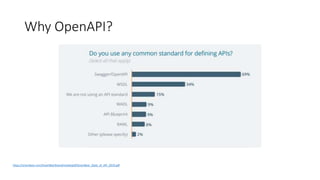






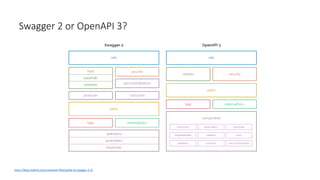
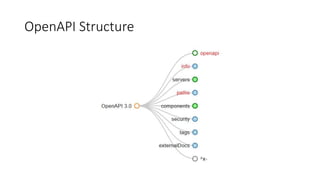





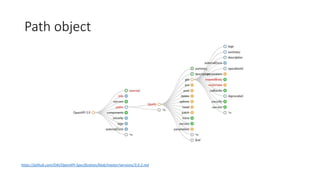
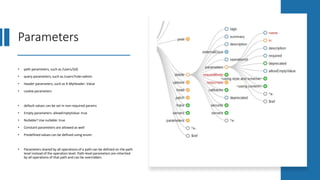


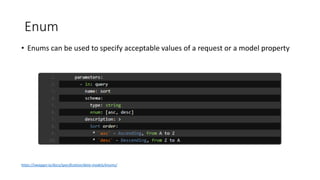

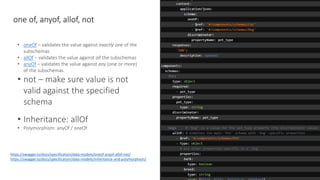


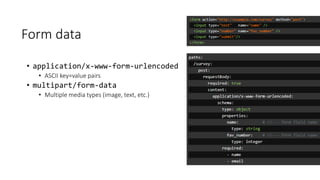




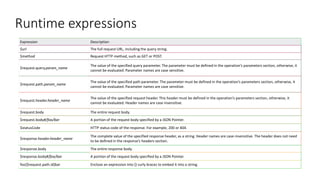


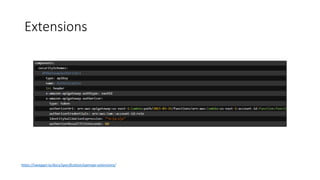






The document provides an introduction and overview of APIs, REST, and OpenAPI specification. It discusses key concepts like resources, HTTP verbs, and OpenAPI structure. It also demonstrates OpenAPI syntax using JSON and YAML examples and highlights best practices for documenting APIs with OpenAPI.



































































