Download to read offline





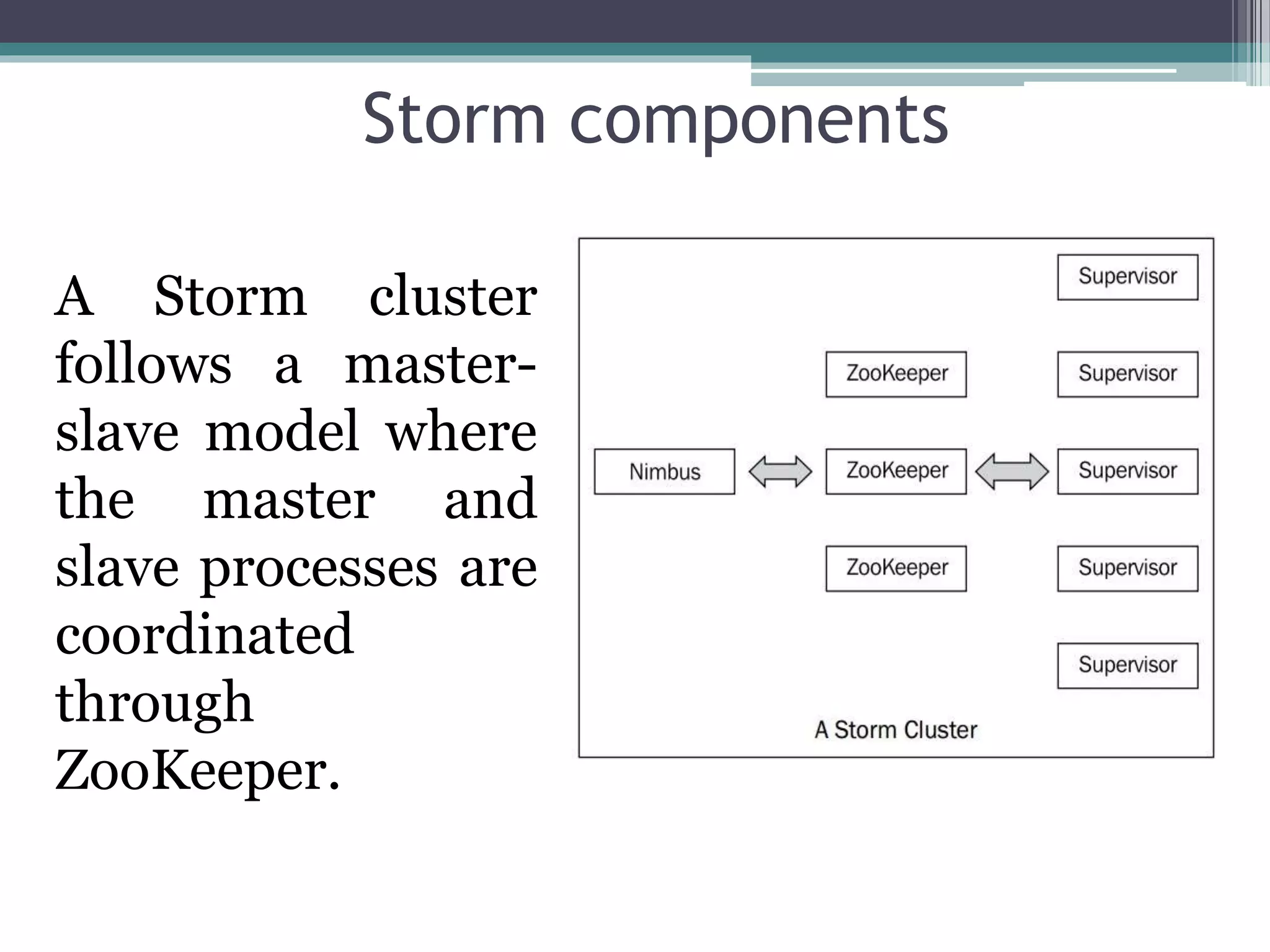




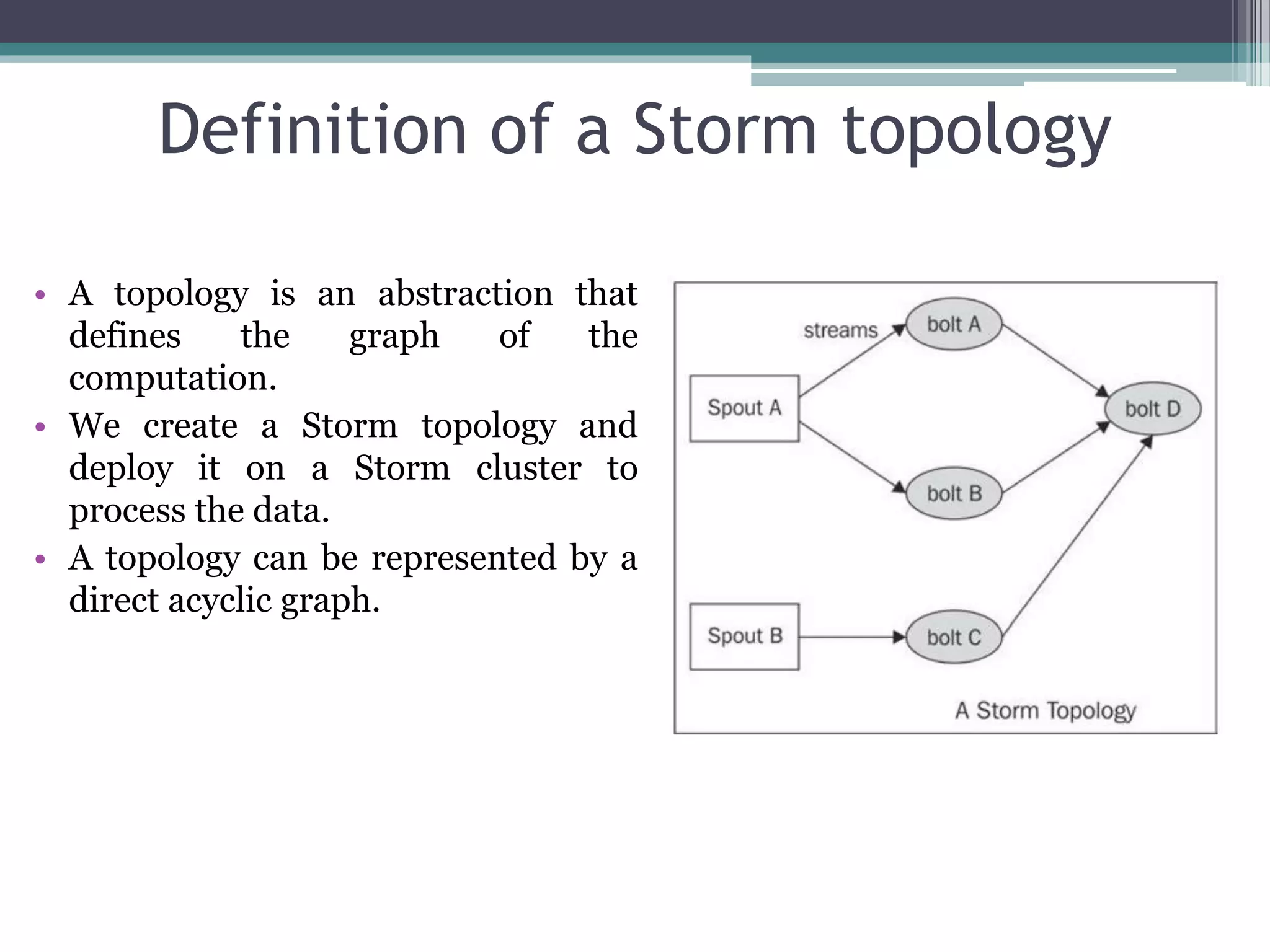






Storm is an open source distributed real-time processing system. It allows real-time processing of streaming data through spouts that emit tuples into streams, which are then processed by bolts. A Storm cluster has a master node called Nimbus that coordinates task assignment, and worker nodes called supervisors that execute the tasks. All state is stored in a ZooKeeper cluster for fault tolerance. Topologies define the graph of computation through spouts, streams, and bolts.















































