Download as PDF, PPTX













![26
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• Example: Bucketing numerical columns, like pd.cut
• Return labels for half-open bins to which each value of column belongs
<0 ͢ A
(0, 10] ͢ B
(10, 20] ͢ c
>20 ͢ D](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-26-2048.jpg)
![27
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• Let's start with UDF implementation
@udf('string')
def cut_udf(value, bins, labels):
ranges = izip_longest(chain([None], bins), bins)
ranges_with_labels = zip(ranges, labels)
for (gt, lte), label in ranges_with_labels:
left_check = gt is None or value > gt
right_check = lte is None or value <= lte
if left_check and right_check:
return label
return None](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-27-2048.jpg)
![28
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• Let's start with UDF implementation
@udf('string')
def cut_udf(value, bins, labels):
ranges = izip_longest(chain([None], bins), bins)
ranges_with_labels = zip(ranges, labels)
for (gt, lte), label in ranges_with_labels:
left_check = gt is None or value > gt
right_check = lte is None or value <= lte
if left_check and right_check:
return label
return None](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-28-2048.jpg)
![29
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• Let's start with UDF implementation
@udf('string')
def cut_udf(value, bins, labels):
ranges = izip_longest(chain([None], bins), bins)
ranges_with_labels = zip(ranges, labels)
for (gt, lte), label in ranges_with_labels:
left_check = gt is None or value > gt
right_check = lte is None or value <= lte
if left_check and right_check:
return label
return None](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-29-2048.jpg)
![30
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• You'd like to call it like this:
• But you can't you need to create array literals and it looks weird
df.select(cut_udf(
'number',
[0, 10, 20],
["A", "B", "C"],
))
df.select(cut_udf(
'number',
array(lit(0), lit(10), lit(20)),
array(lit("A"), lit("B"), lit("C"), lit("D")),
))](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-30-2048.jpg)
![31
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• How to get rid of this UDF and use pure Spark SQL / DataFrames?
• First of all, we don't need to pass bins and labels to every invocation
def cut(c, bins, labels):
ranges = izip_longest(chain([None], bins), bins)
ranges_with_labels = zip(ranges, labels)
@udf('string')
def _cut(value):
for (gt, lte), label in ranges_with_labels:
left_check = gt is None or value > gt
right_check = lte is None or value <= lte
if left_check and right_check:
return label
return None
return _cut(c)](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-31-2048.jpg)
![32
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• We can build the inner logic using when and otherwise built-in functions
def cut(col, bins, labels):
ranges = izip_longest(chain([None], bins), bins)
ranges_with_labels = zip(ranges, labels)
conditions = [lit(None).cast(str)]
for (gt, lte), label in ranges_with_labels:
left_check = lit(True) if gt is None else col > lit(gt)
right_check = lit(True) if lte is None else col <= lit(lte)
condition = when(left_check & right_check, label)
conditions.append(condition)
condition = reduce(lambda a, b: b.otherwise(a), conditions)
return condition](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-32-2048.jpg)
![33
BEST PRACTICES & TIPS FOR WRITING HIGH-PERFORMANCE PYSPARK APPLICATIONS
#1 Stick to DataFrames when possible
• We got rid of UDF entirely, and can call this function like this:
• Readability of the cut function might be slightly worse, but has improved
performance because it avoids Python execution with all the attached
costs
df.select(cut(
col('number'),
[0, 10, 20],
["A", "B", "C", "D"],
))](https://image.slidesharecdn.com/diveintopyspark-180305120741/75/Dive-into-PySpark-33-2048.jpg)

















The document is a presentation by Mateusz Buśkiewicz focused on PySpark, covering topics such as its architecture, internal workings, and best practices for performance optimization. It emphasizes the importance of using DataFrames over Python UDFs to enhance execution speed and provides insights into asynchronous execution and vectorized UDFs. The content is aimed at data engineering and data science professionals looking to improve their skills in using PySpark effectively.
Introduction to the speaker Mateusz Buśkiewicz and the agenda covering PySpark basics, internals, best practices, and performance tips.
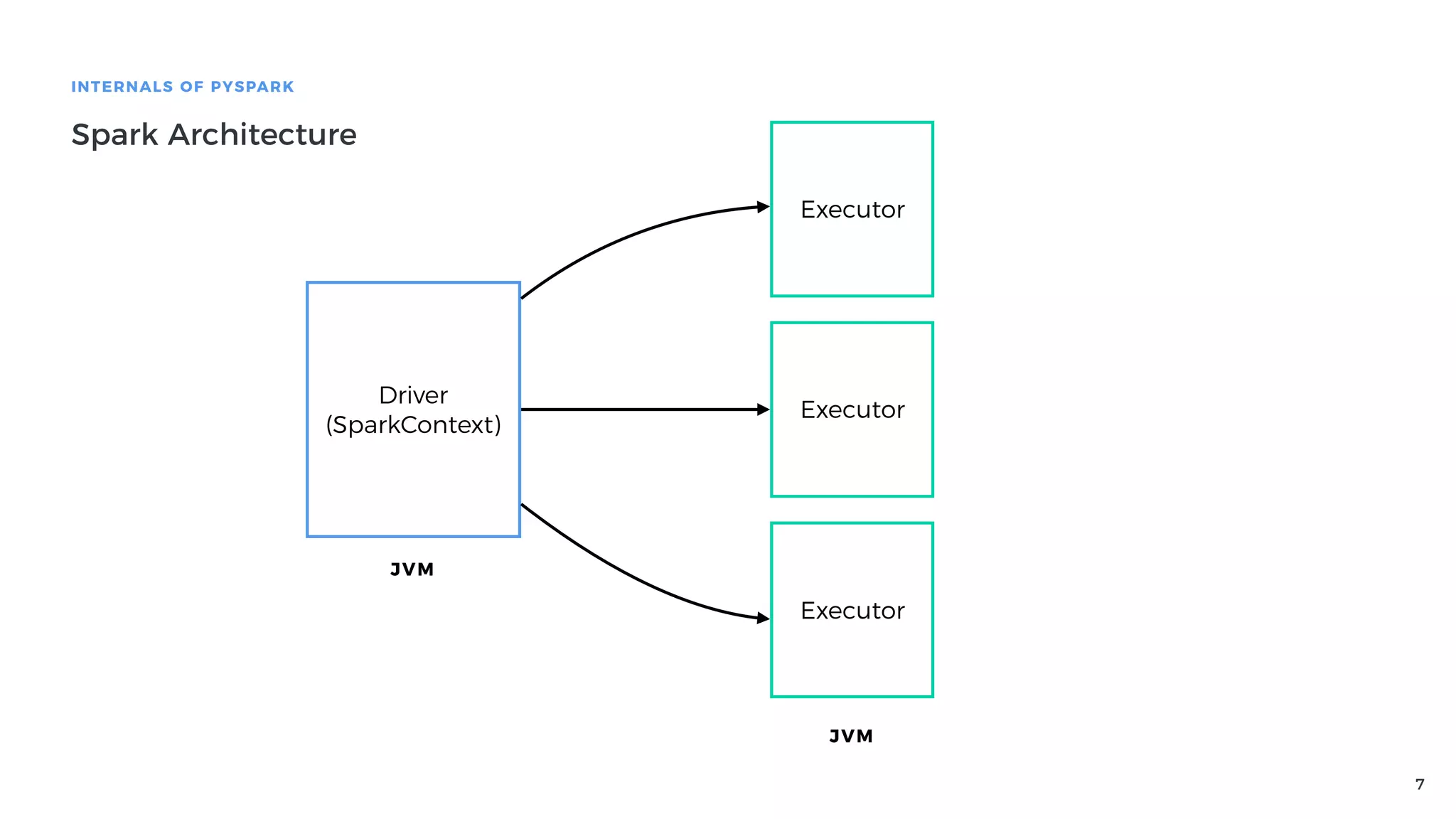
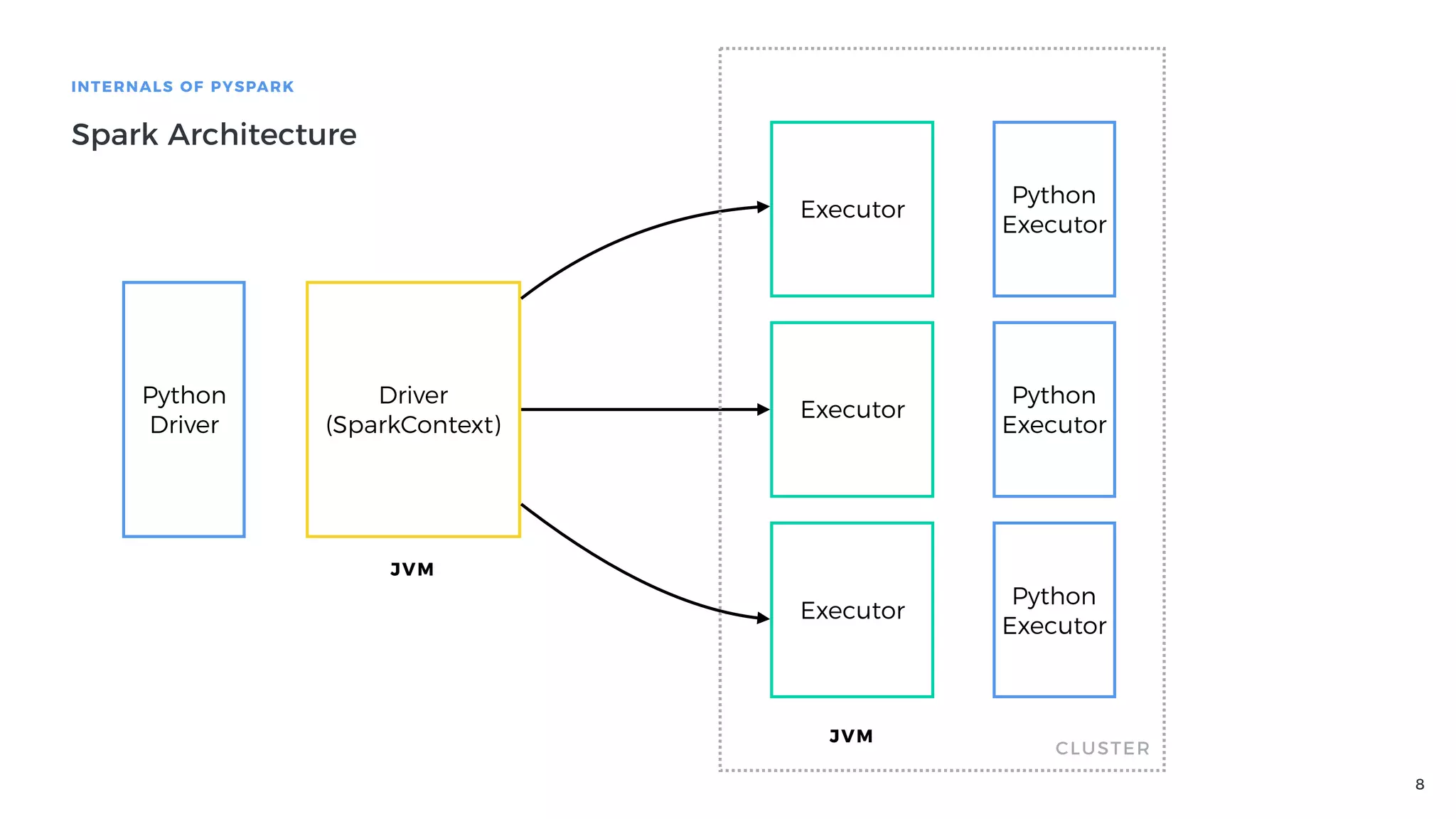
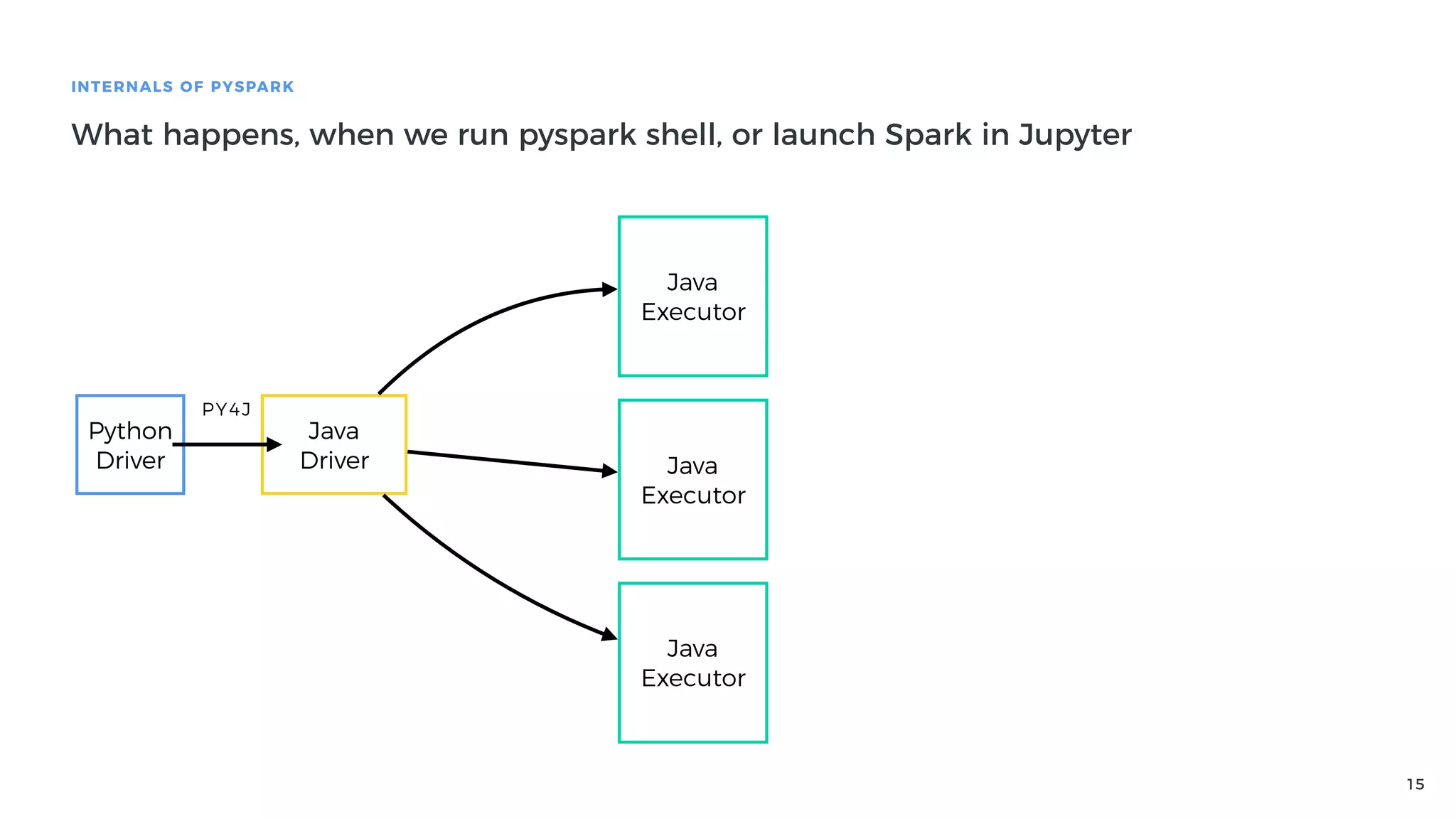
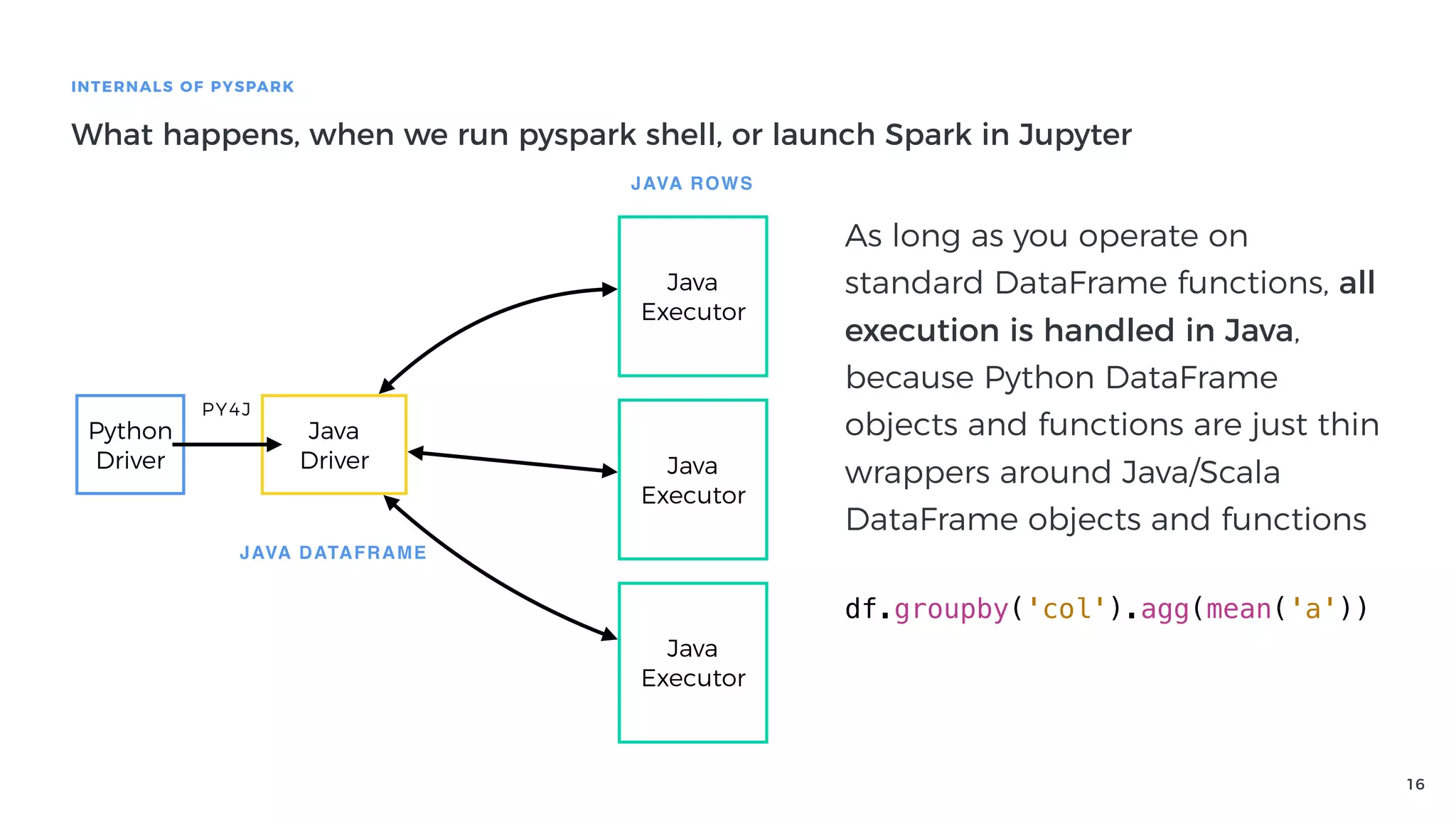
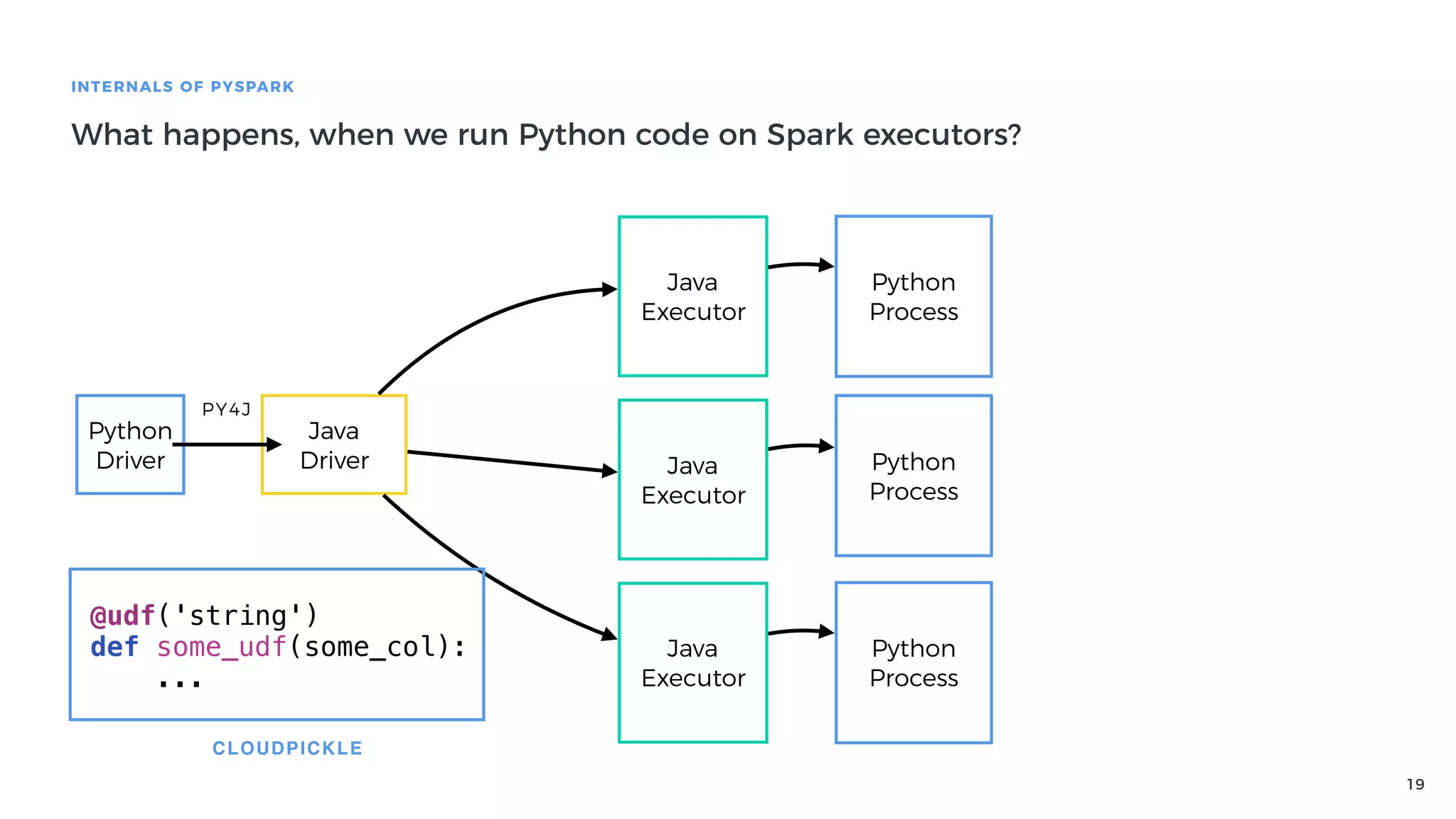
Definition of PySpark as a fast distributed processing system, featuring its API, and explaining Spark architecture and its components.
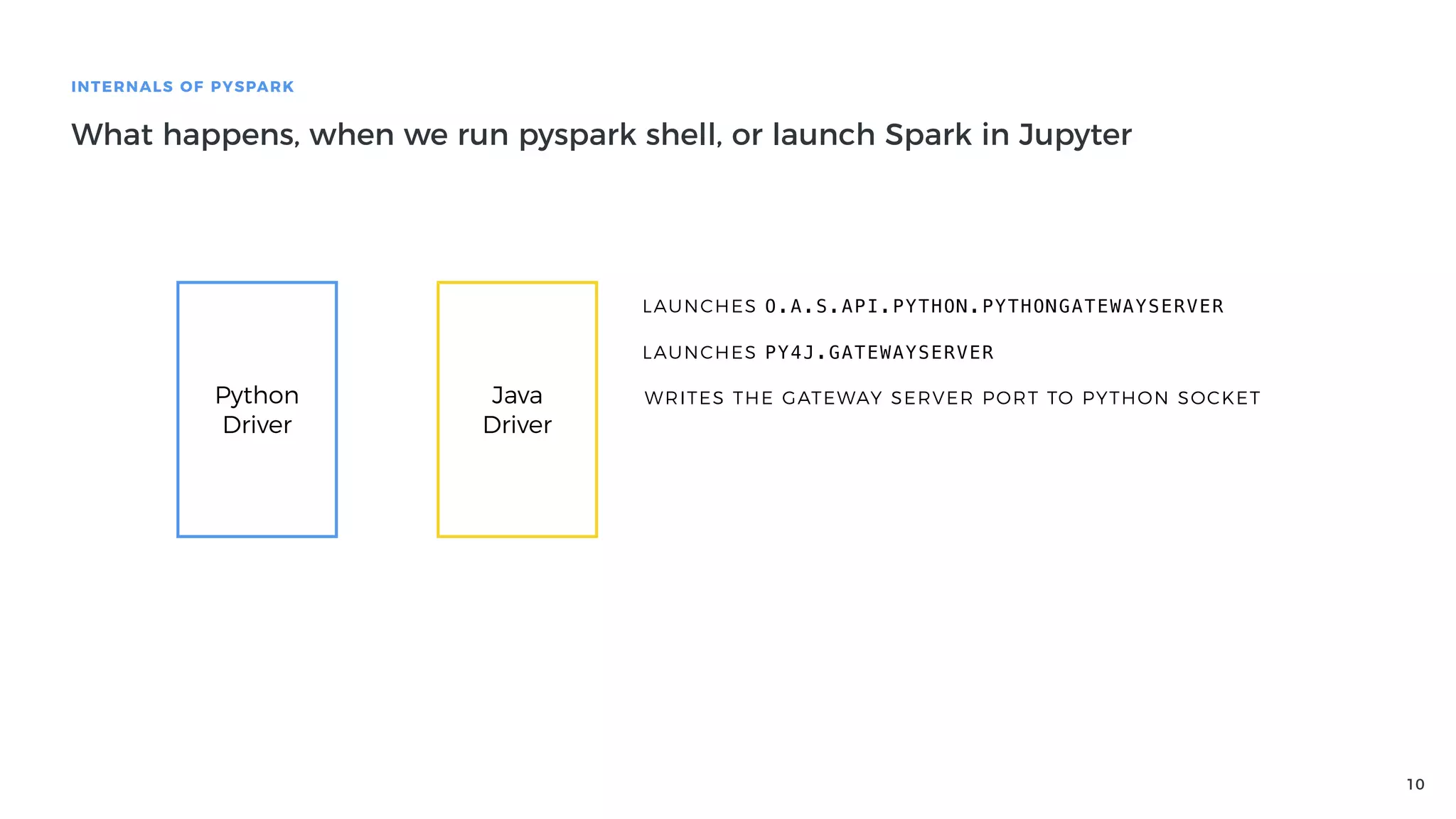
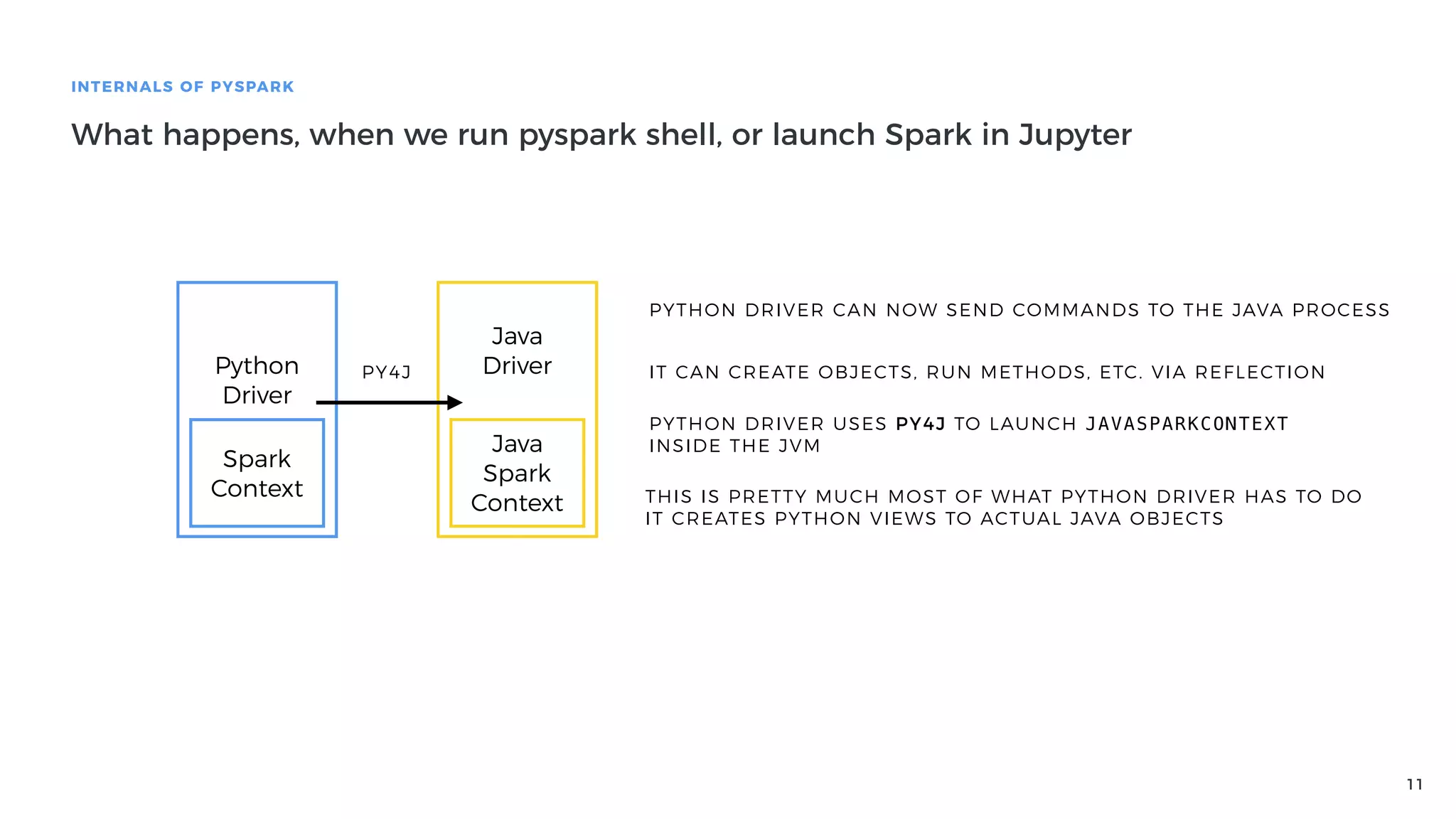
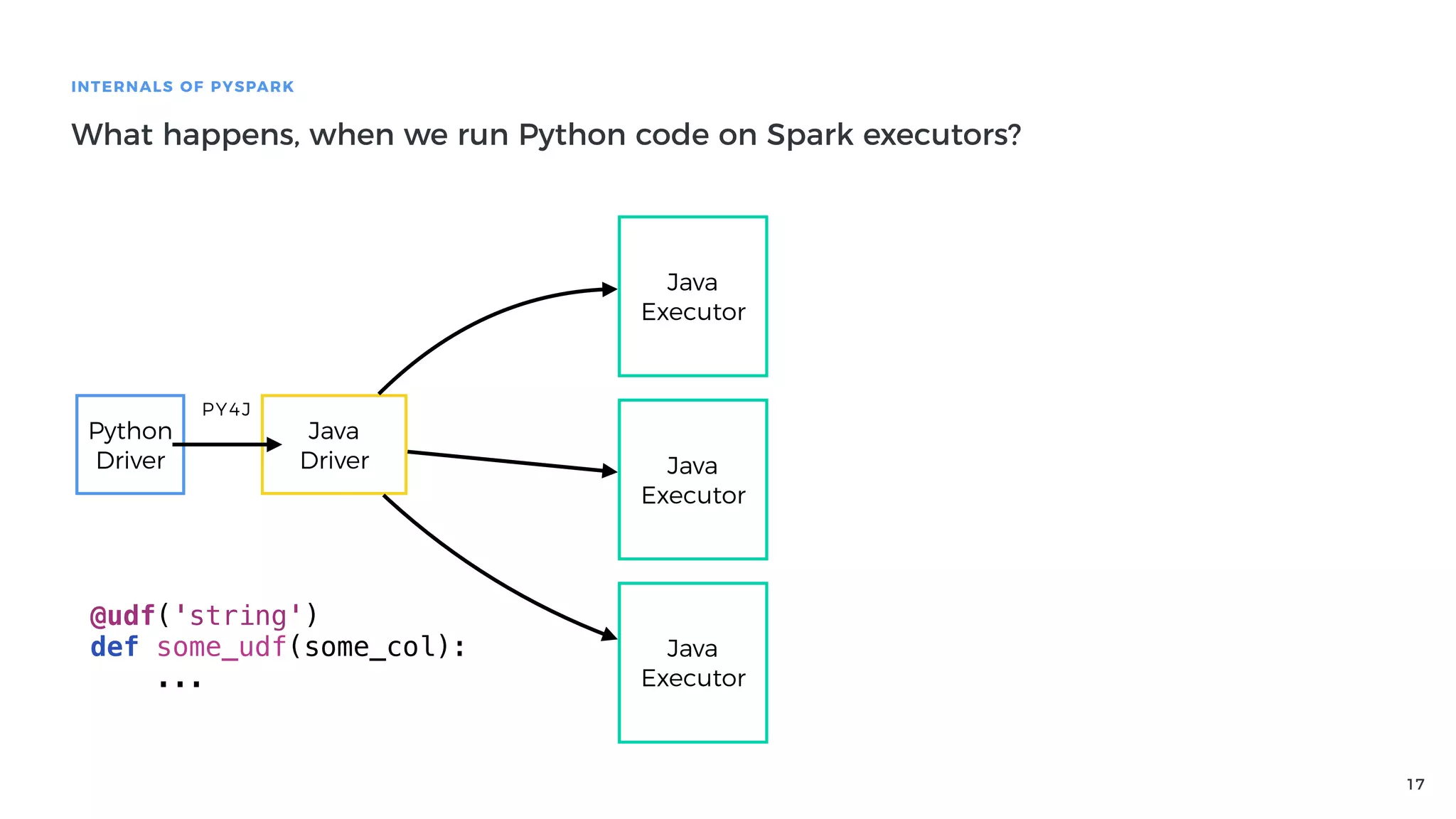
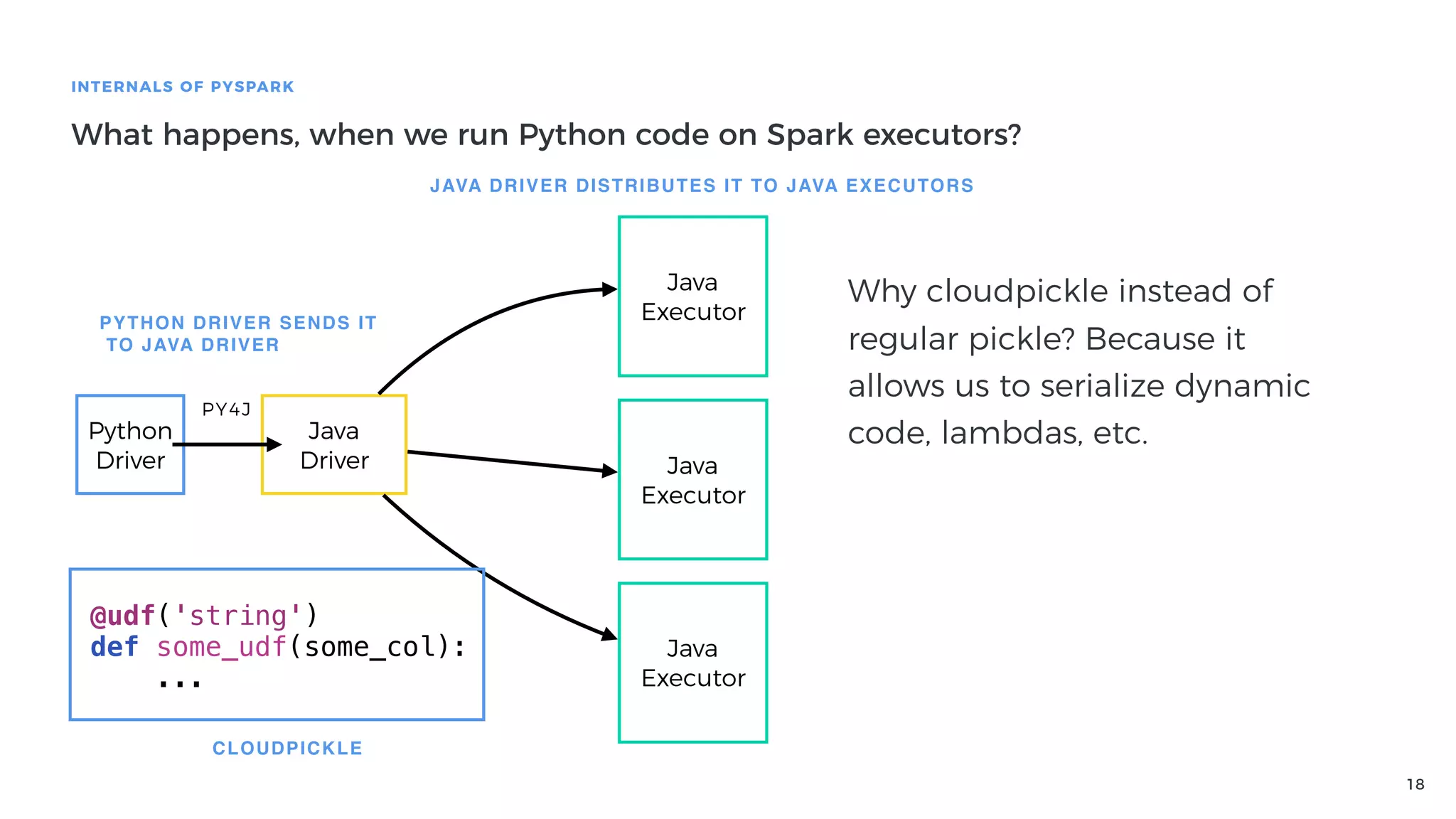
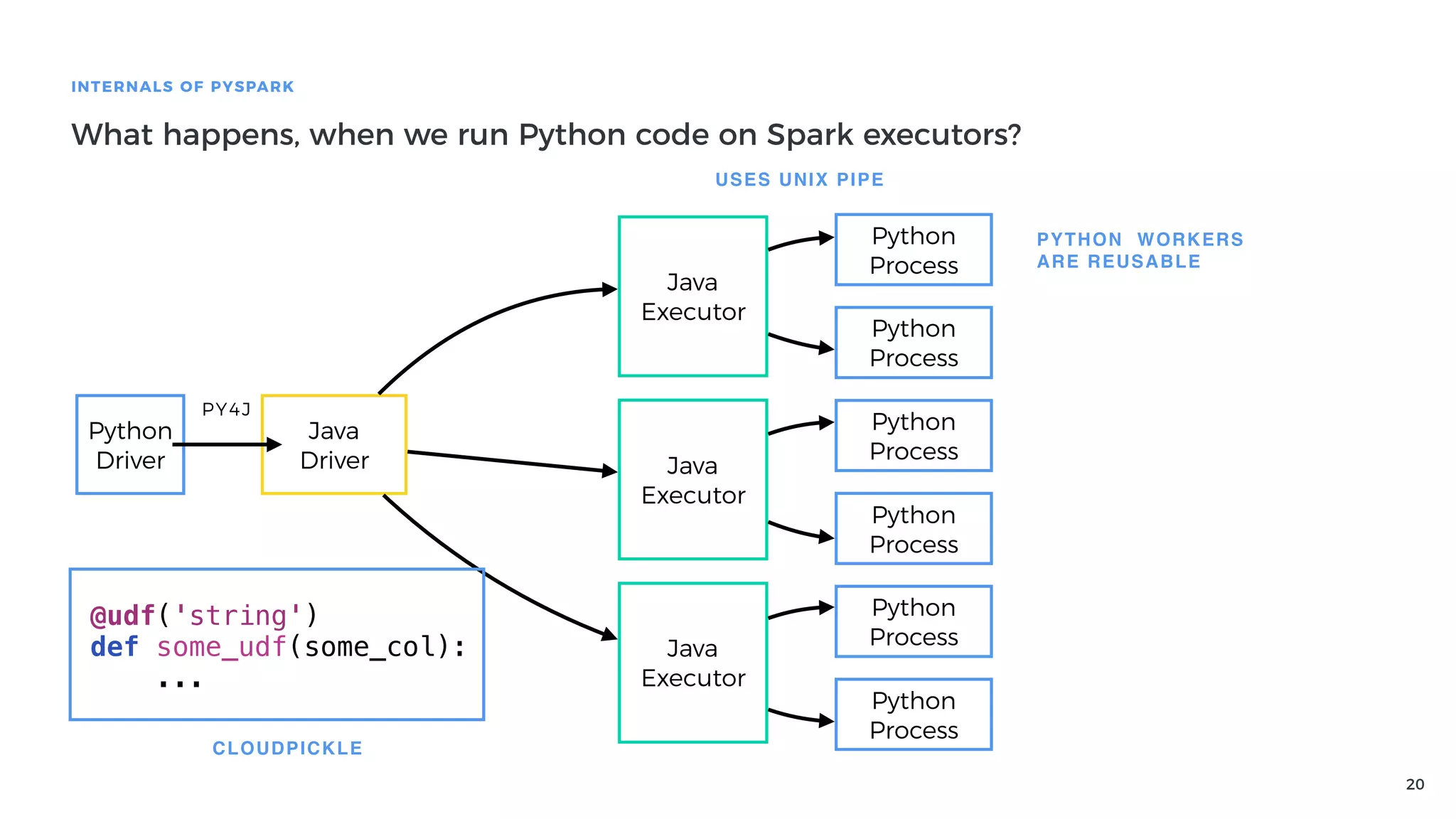
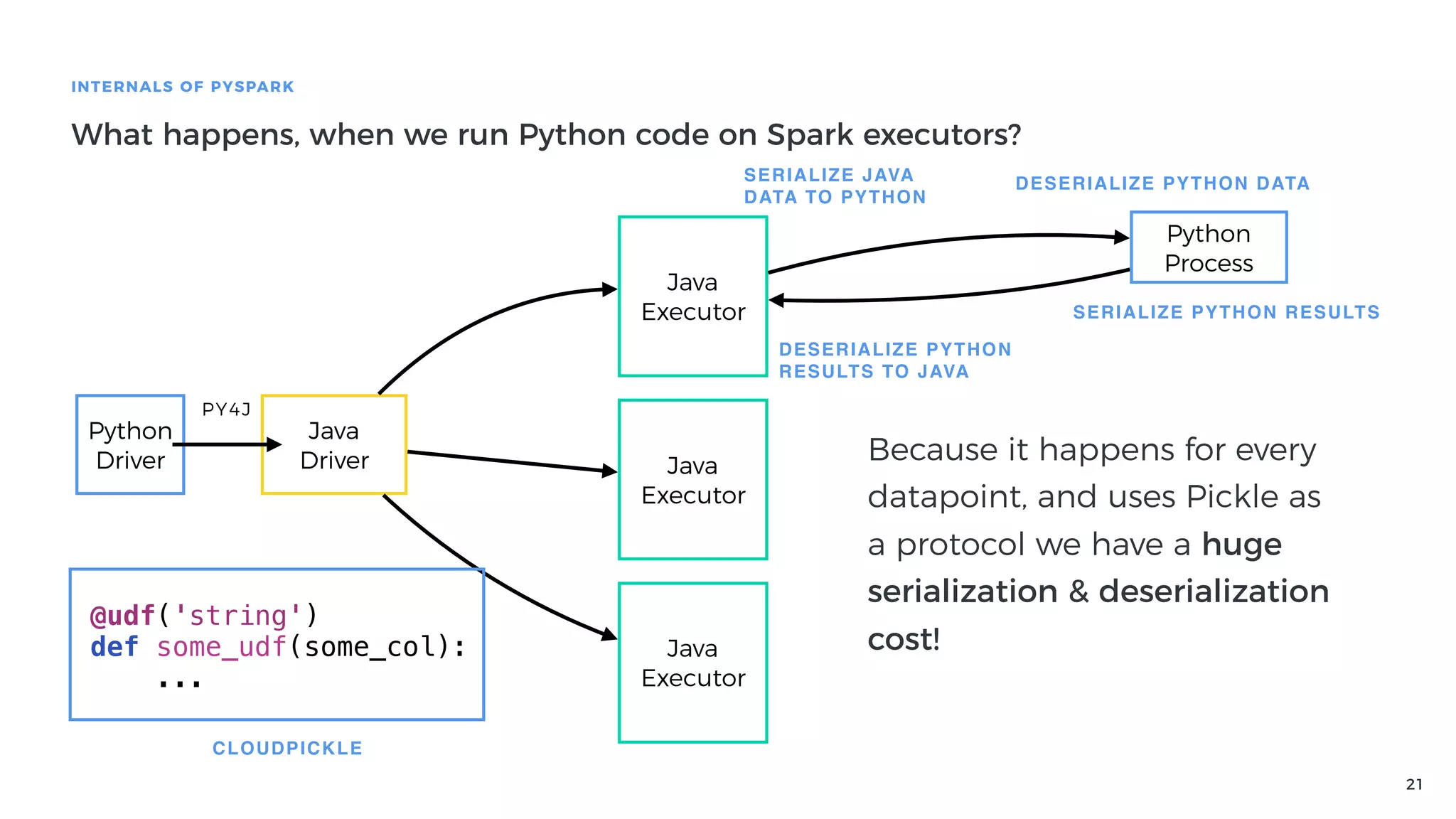
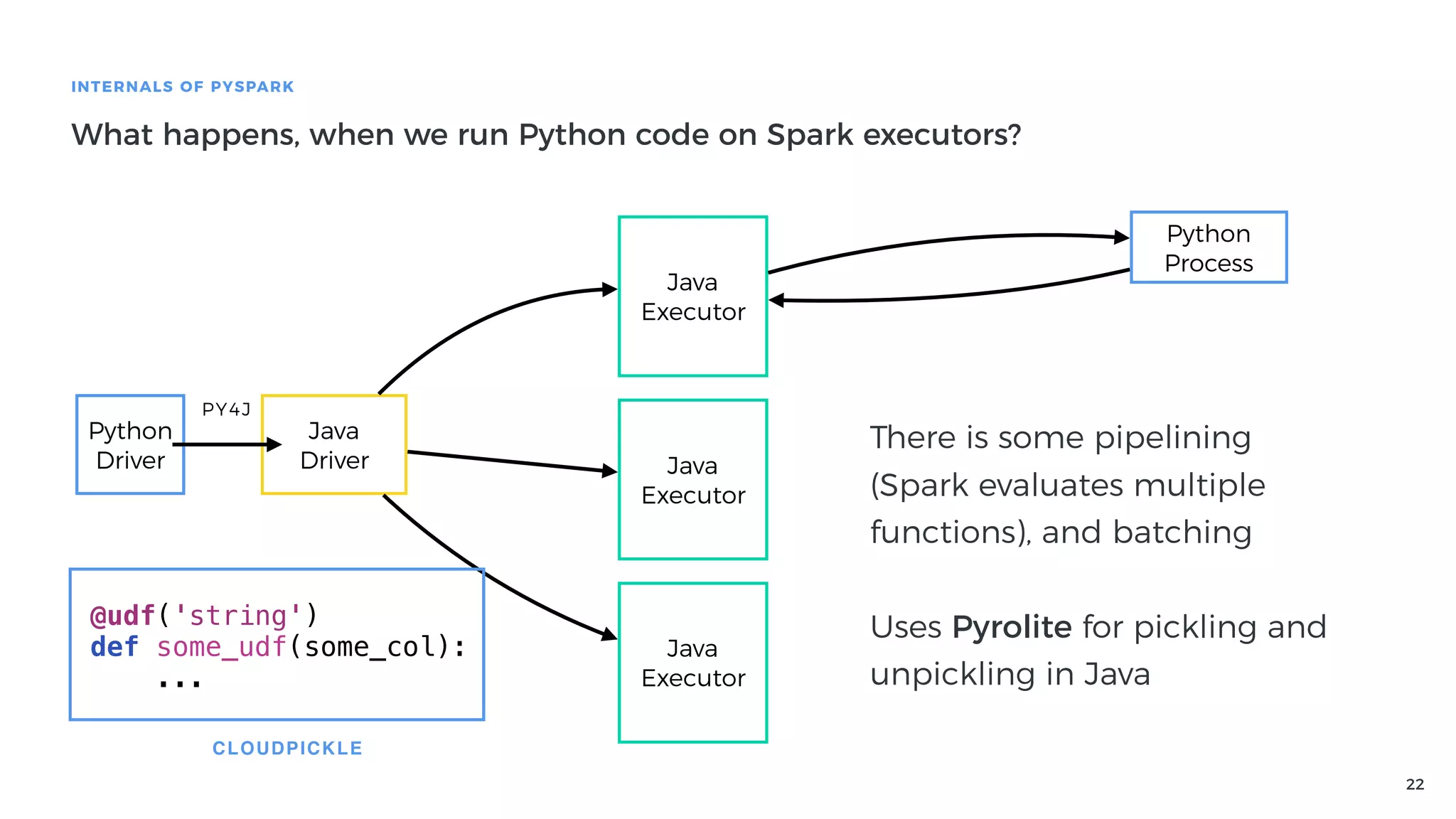
Explanation of how Py4J bridges Python and Java in PySpark, detailing how Python code execution and data serialization occur.
Performance issues related to using Py4J and Python execution in PySpark and the costs of serialization.
Tips for writing high-performance PySpark applications, focusing on using DataFrames and avoiding Python execution.
Guidelines for making PySpark methods asynchronous, enhancing the efficiency of interactive analyses.
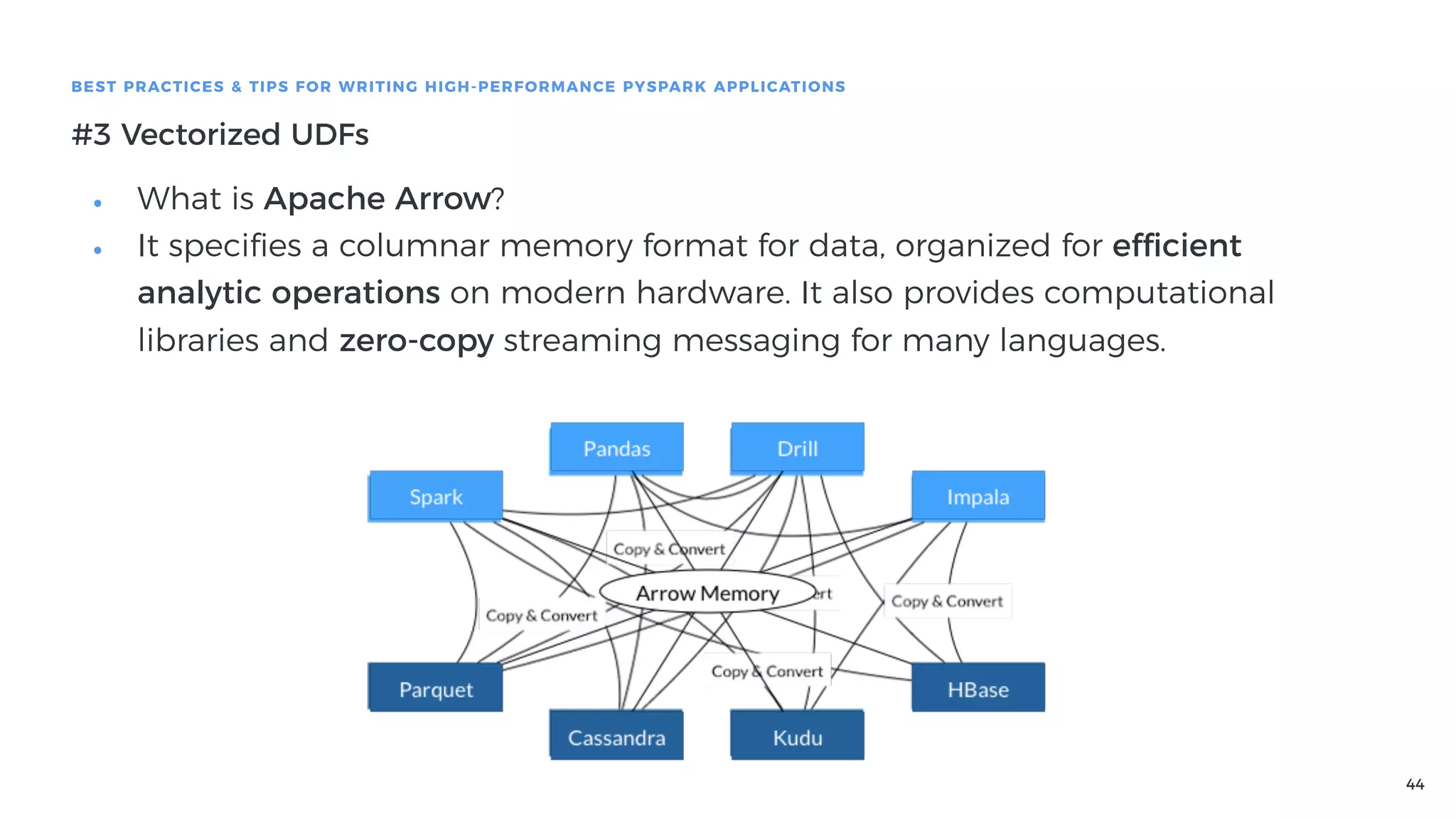
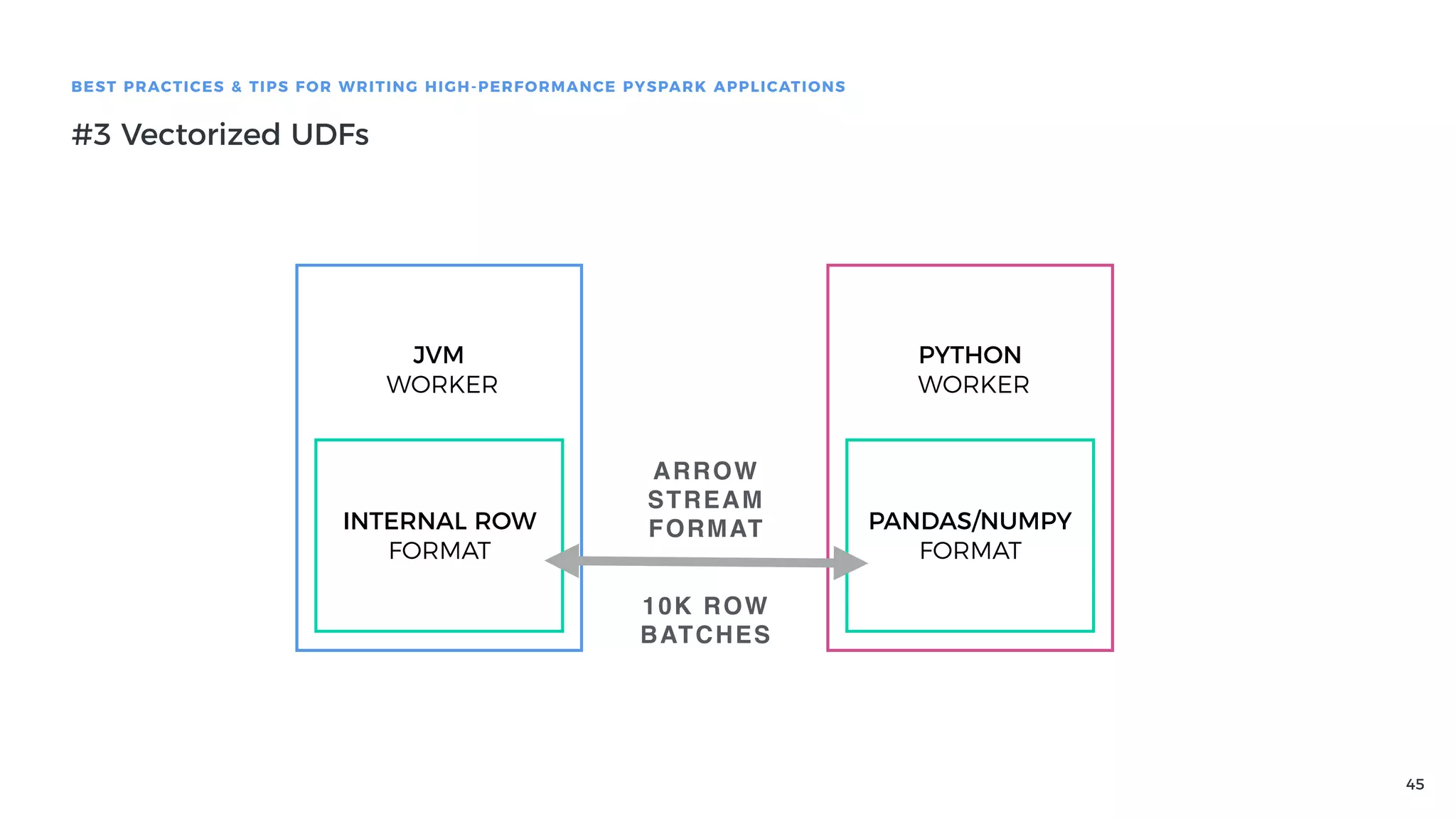
Introduction to Vectorized UDFs based on Apache Arrow, highlighting their efficiency over traditional UDFs and usage in PySpark.
Request for audience feedback and conclusion of the presentation.

















































![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)











