Downloaded 68 times






































![Configuring Spark’s Runtime
Properties
• Once the SparkSession is instantiated, you can configure Spark’s
runtime config properties. For example, in this code snippet, we can
alter the existing runtime config options. Since configMap is a
collection, you can use all of Scala’s iterable methods to access the
data.
//set new runtime options
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//get all settings
val configMap:Map[String, String] = spark.conf.getAll()](https://image.slidesharecdn.com/sparksql-180901143146/75/Spark-sql-61-2048.jpg)














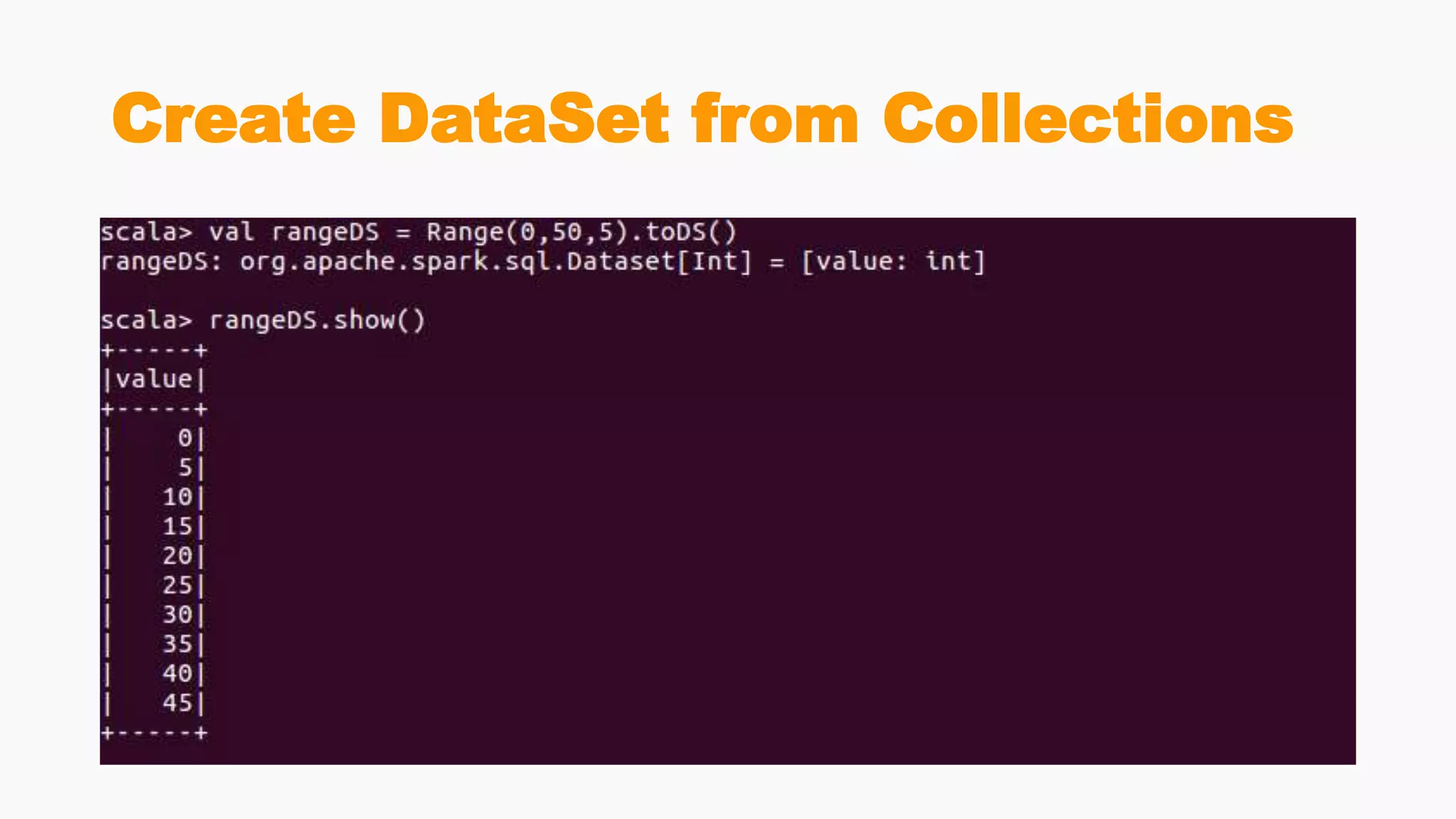
![DataSets
• provide an API that allows users to easily perform transformations on
domain objects
• provide performance and robustness advantages of the Spark SQL
execution engine
• compete to RDDs as they have overlapping functions
• DataFrame is an alias to Dataset[Row].
• Datasets are optimized for typed engineering tasks, for which you
want types checking and object-oriented programming interface,
• while DataFrames are faster for interactive analytics and close to SQL
style](https://image.slidesharecdn.com/sparksql-180901143146/75/Spark-sql-86-2048.jpg)








![Datasets
• Since Spark 2.0 DataFrame is an alias for a collection of generic
objects Dataset[Row], where a Row is a generic untyped JVM object](https://image.slidesharecdn.com/sparksql-180901143146/75/Spark-sql-96-2048.jpg)












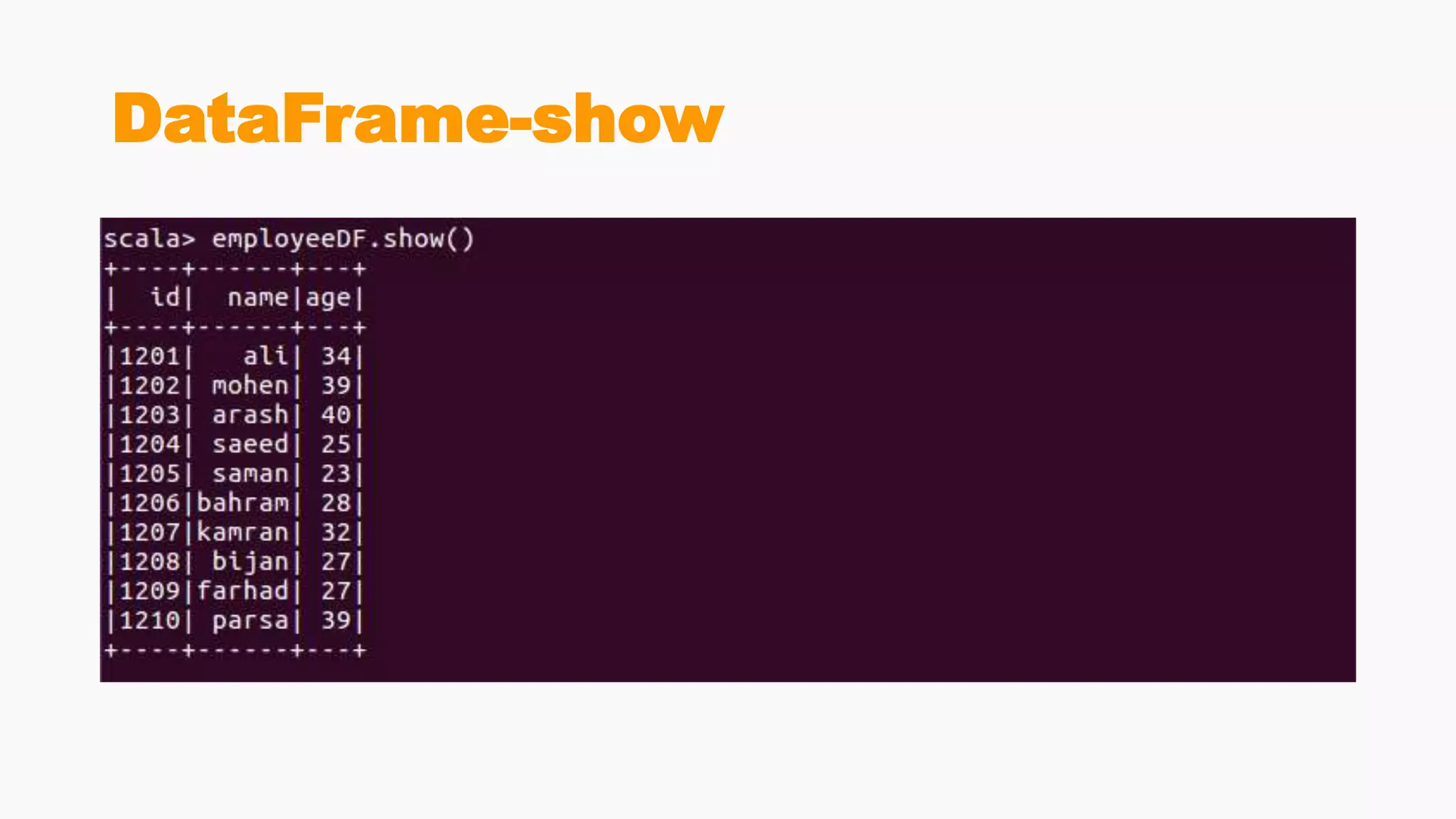
Spark SQL is a module for structured data processing in Spark. It provides DataFrames and the ability to execute SQL queries. Some key points: - Spark SQL allows querying structured data using SQL, or via DataFrame/Dataset APIs for Scala, Java, Python, and R. - It supports various data sources like Hive, Parquet, JSON, and more. Data can be loaded and queried using a unified interface. - The SparkSession API combines SparkContext with SQL functionality and is used to create DataFrames from data sources, register databases/tables, and execute SQL queries.
Course on Spark SQL overview, covering fundamentals, session structure, and various topics like DataFrames and SQL features.
Explains Spark SQL's role for structured data processing, including features like Hive compatibility, scalability, and data source integration.
Introduces DataFrames in Spark SQL, their construction, optimization techniques, and various supported data formats.
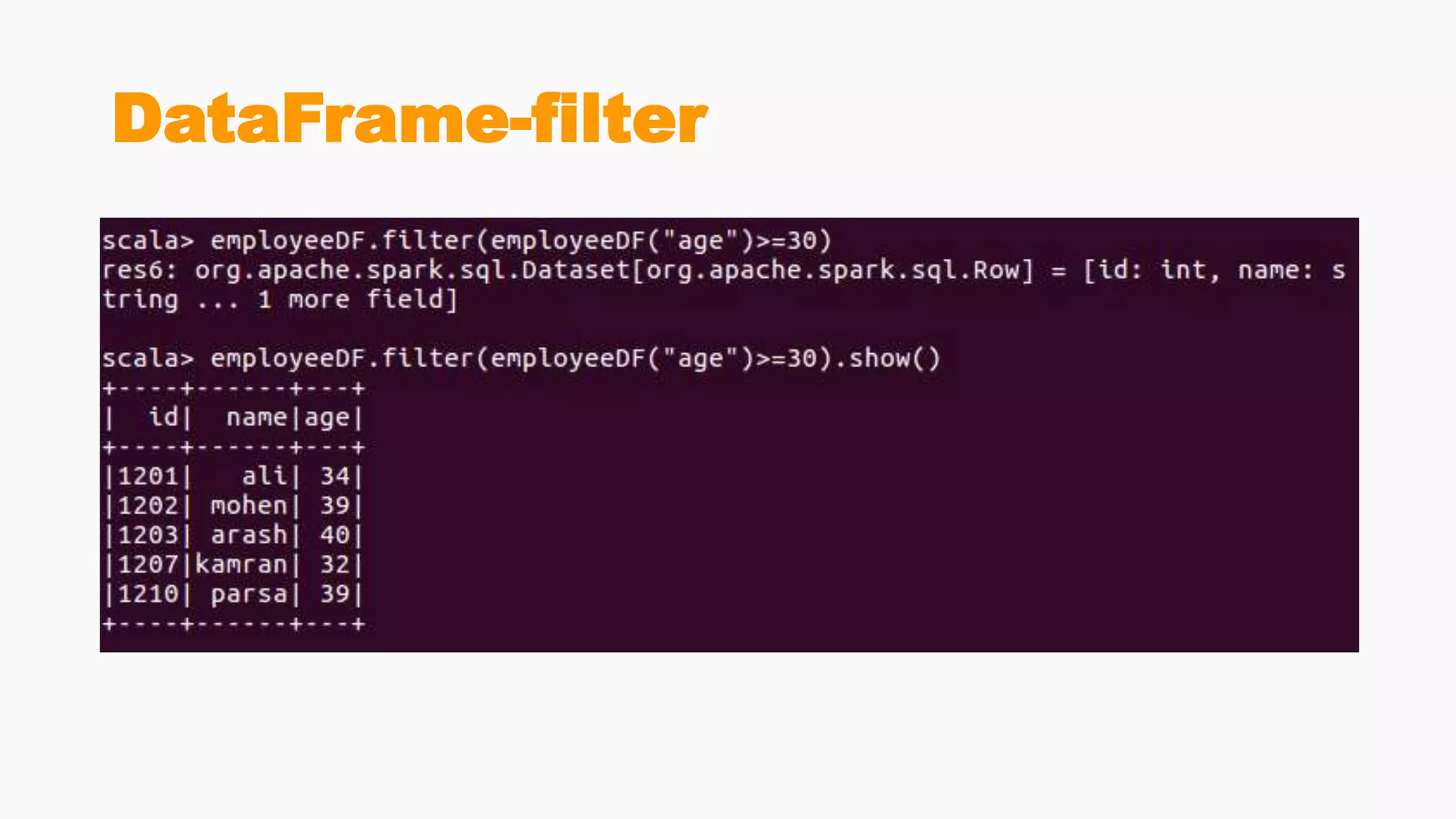
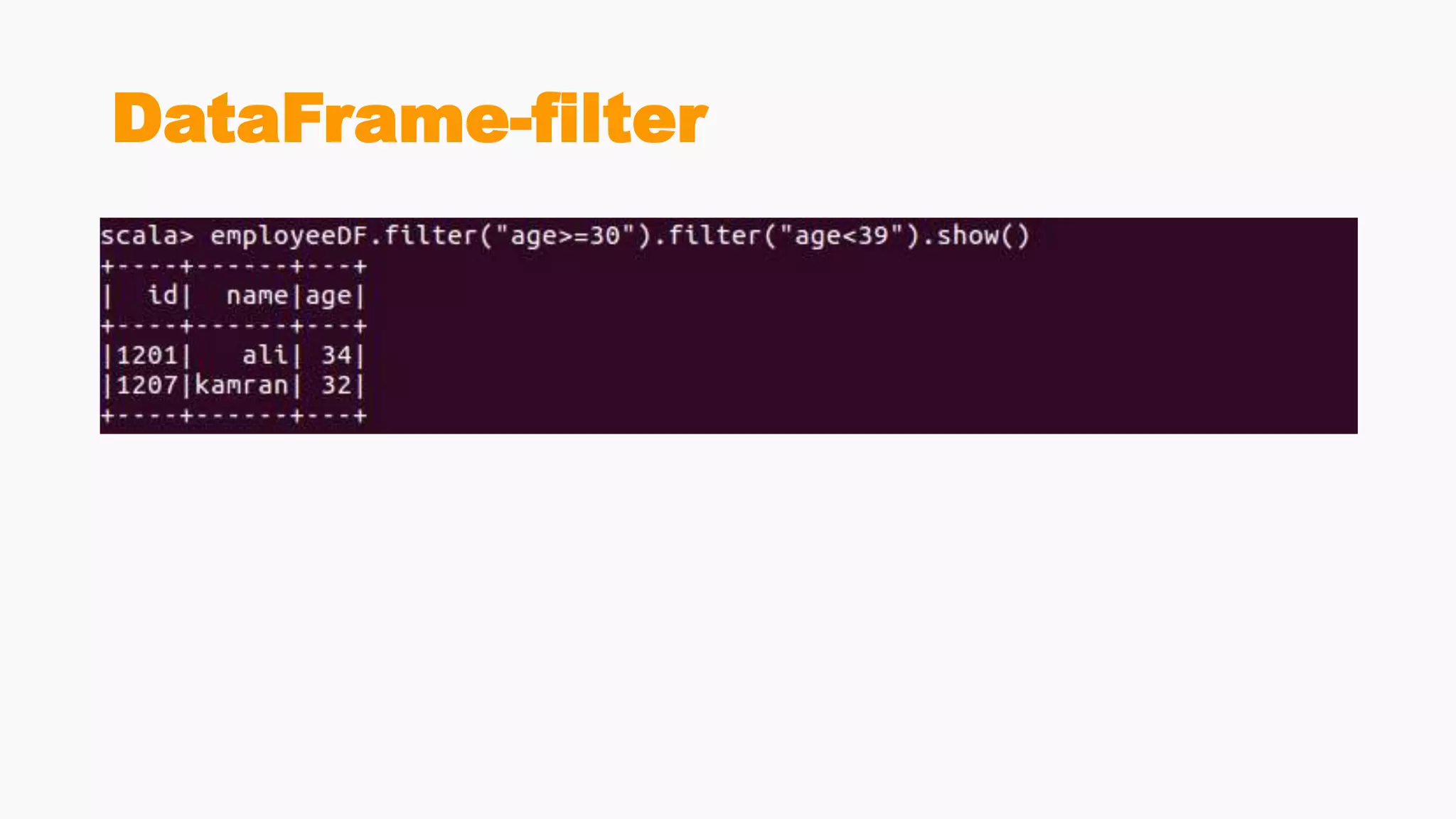
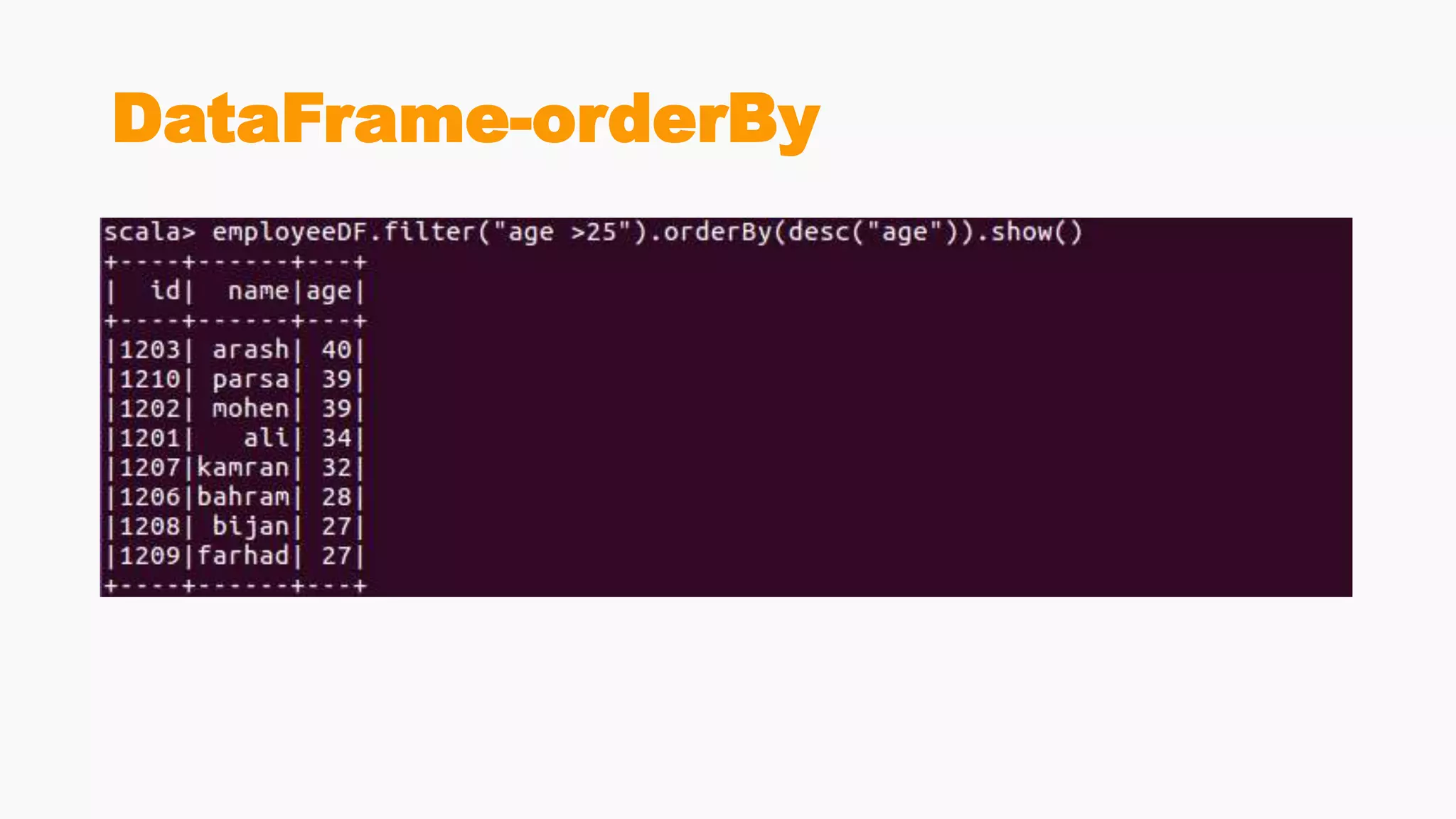
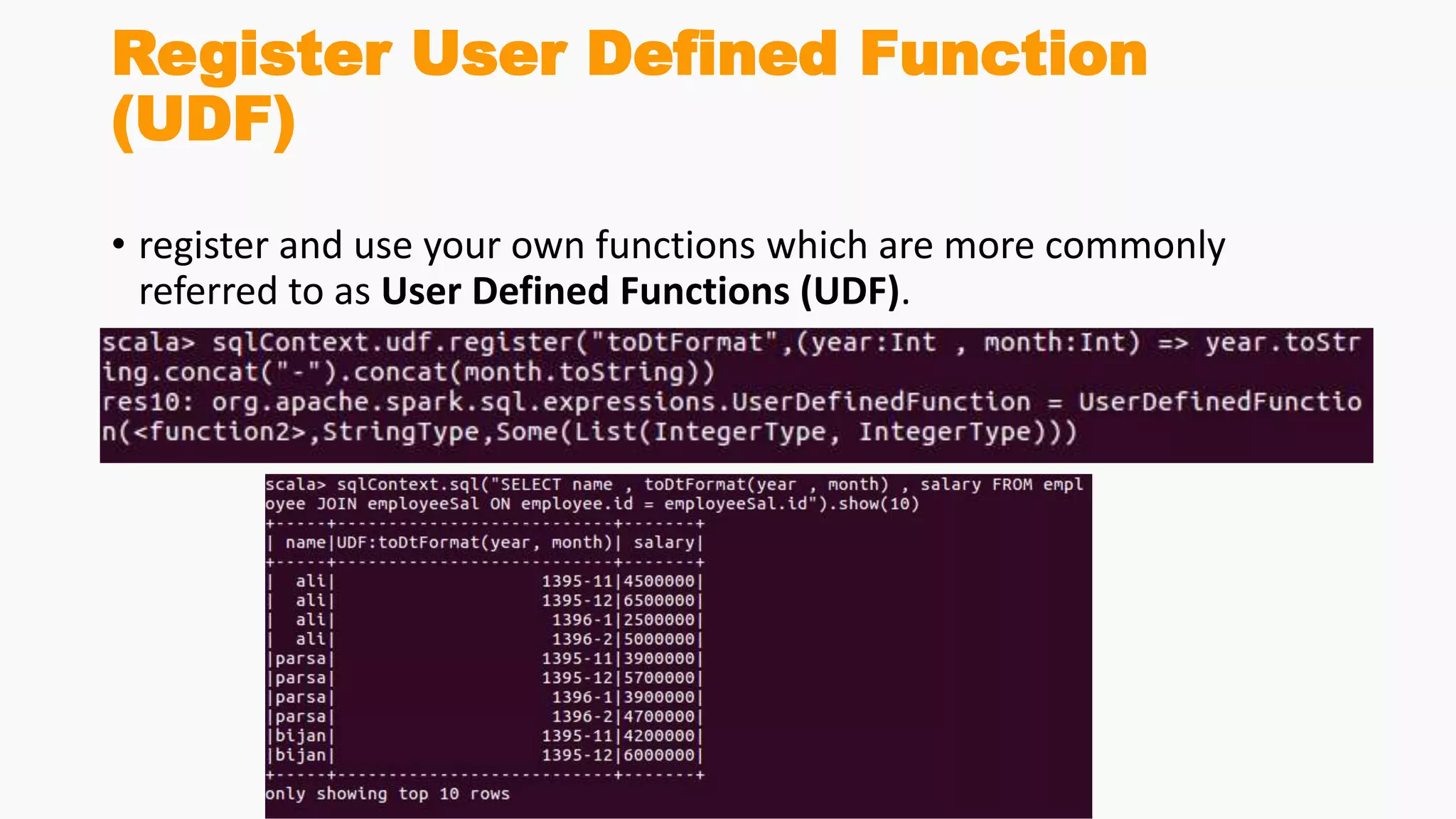
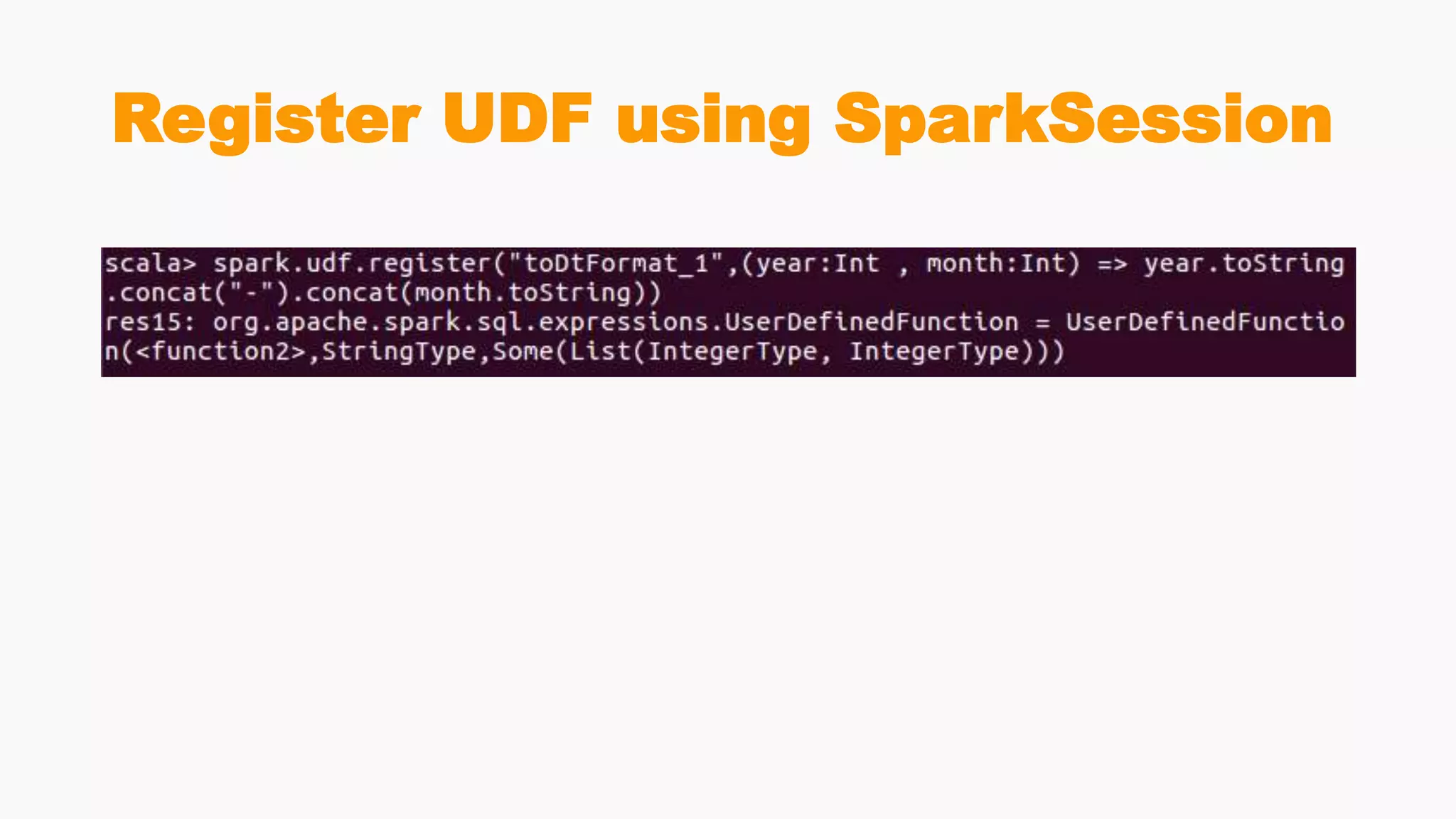
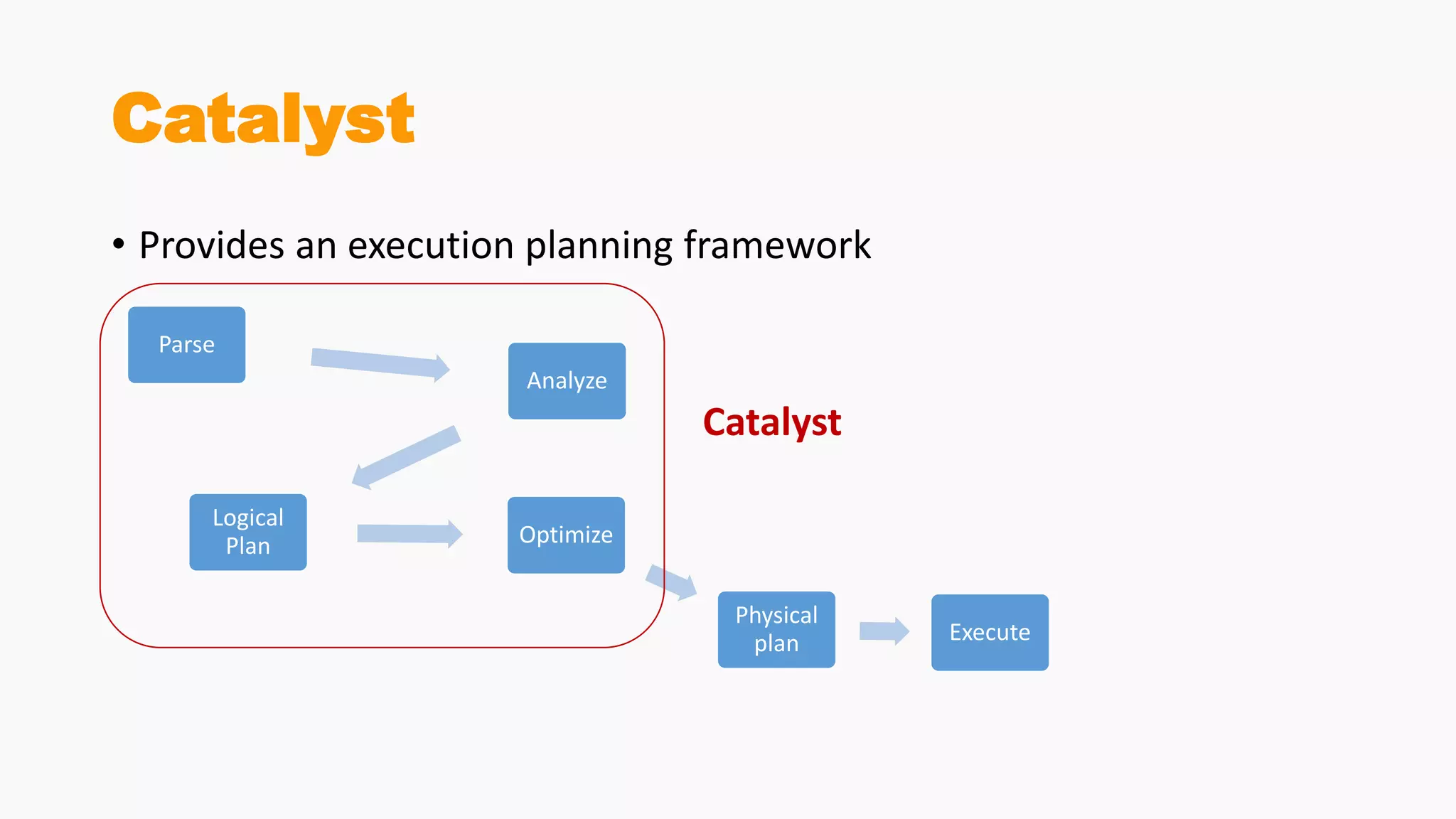
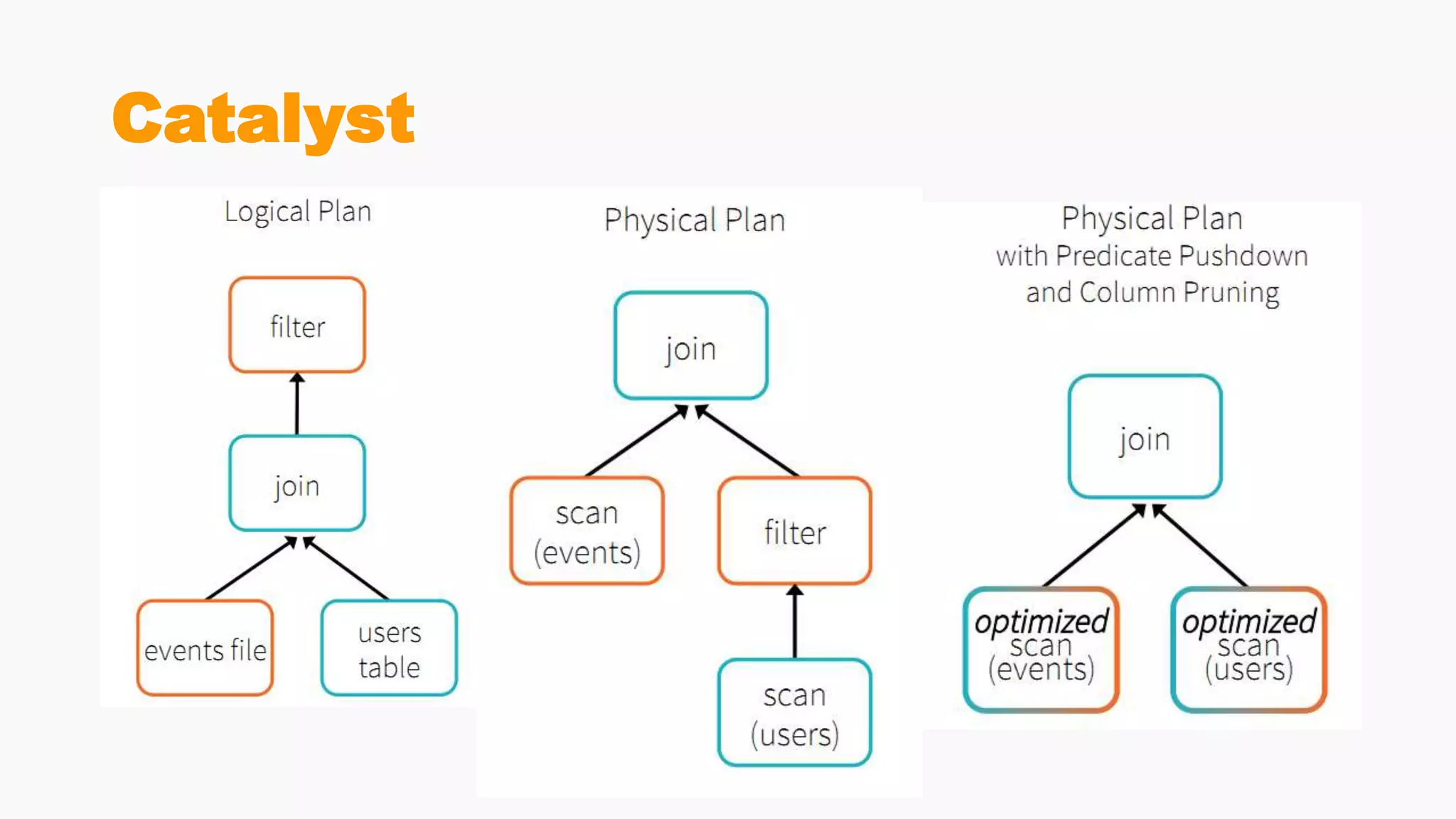
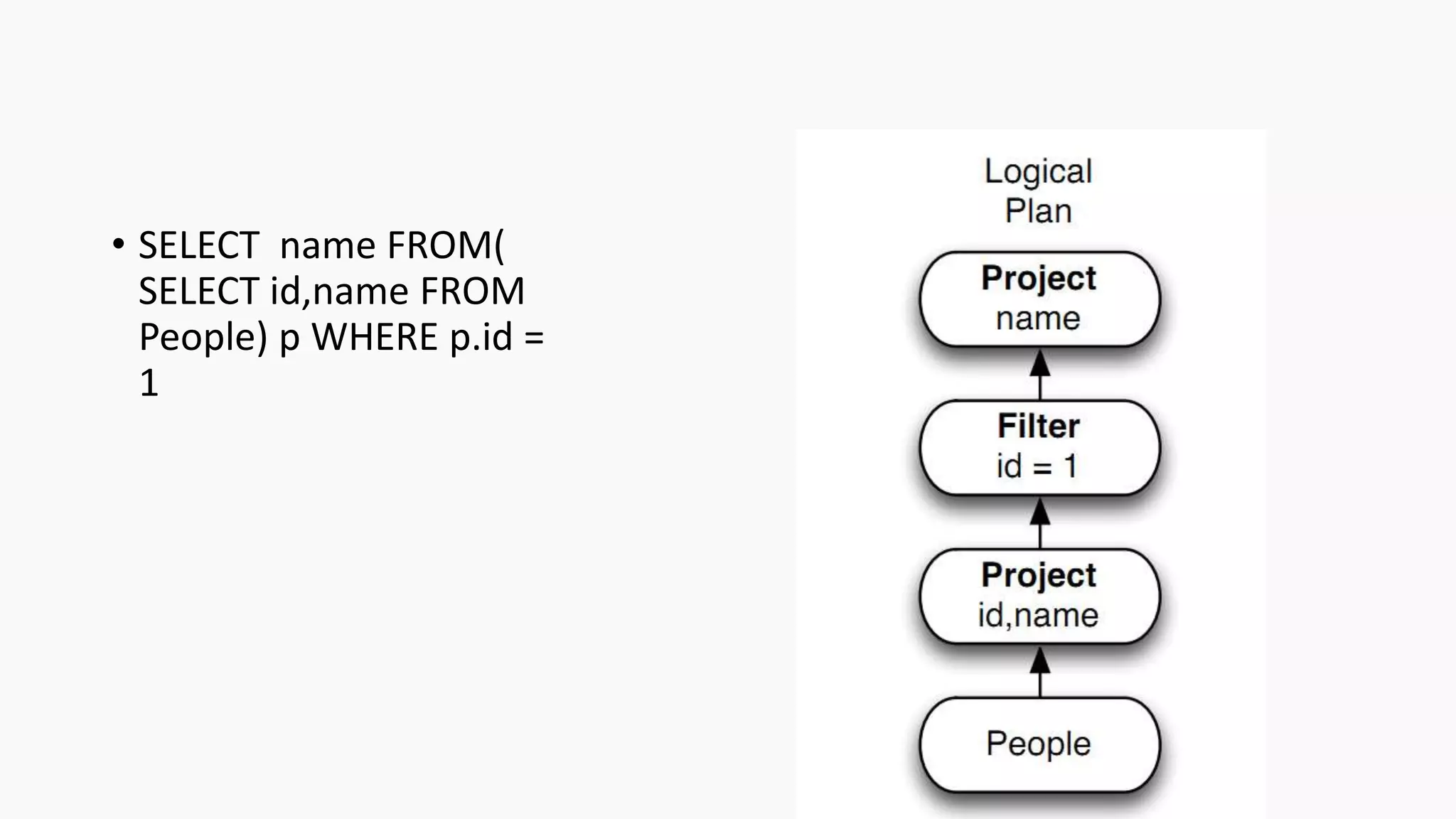
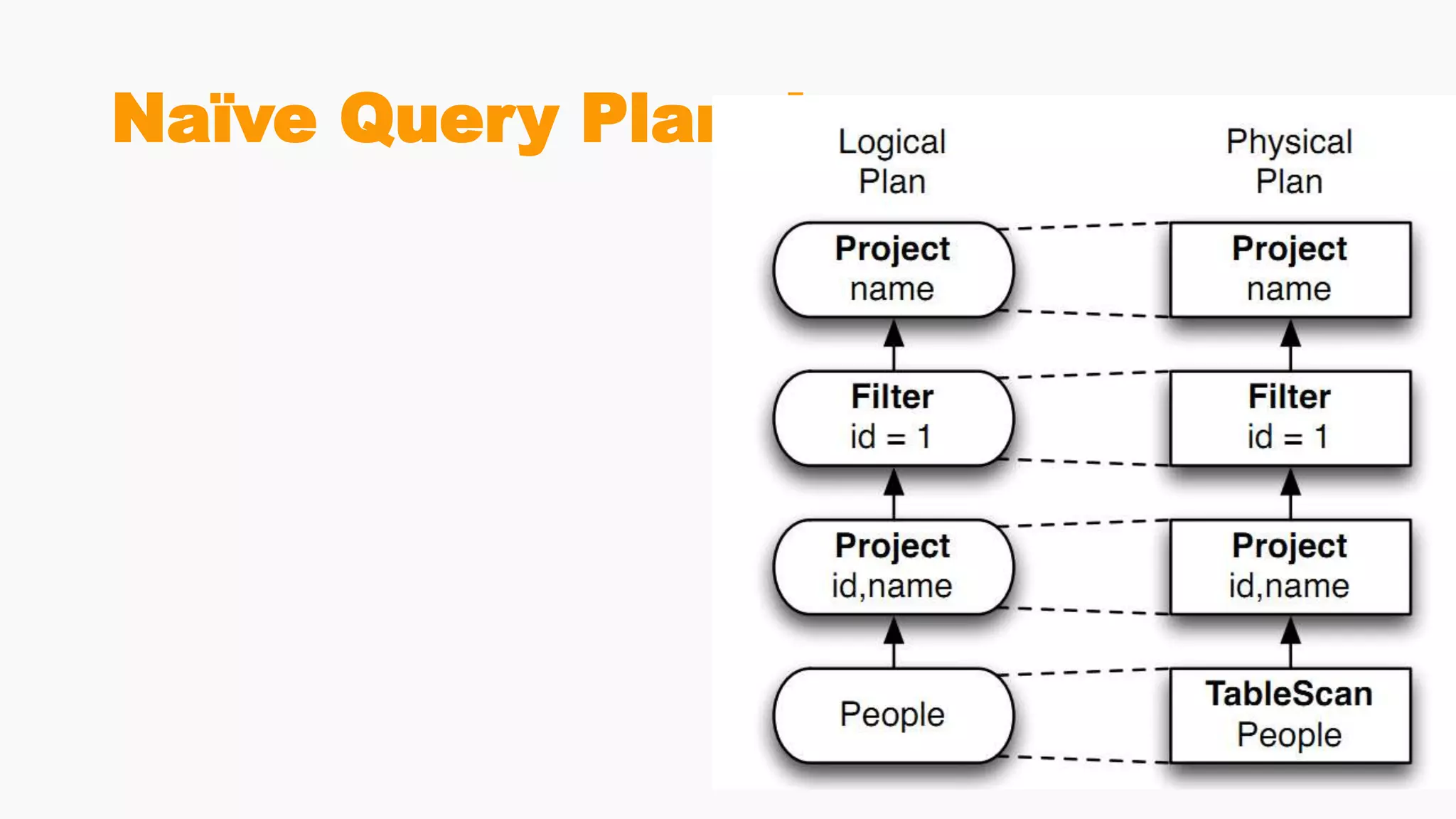
Demonstrates creation of DataFrames, filtering, transformation methods, and using SQL for querying structured data.Discusses the creation and registration of UDFs, and Spark Catalyst's role in query planning and optimization.
Comparative analysis of using SQL queries versus DataFrame API, emphasizing error handling and performance benefits.
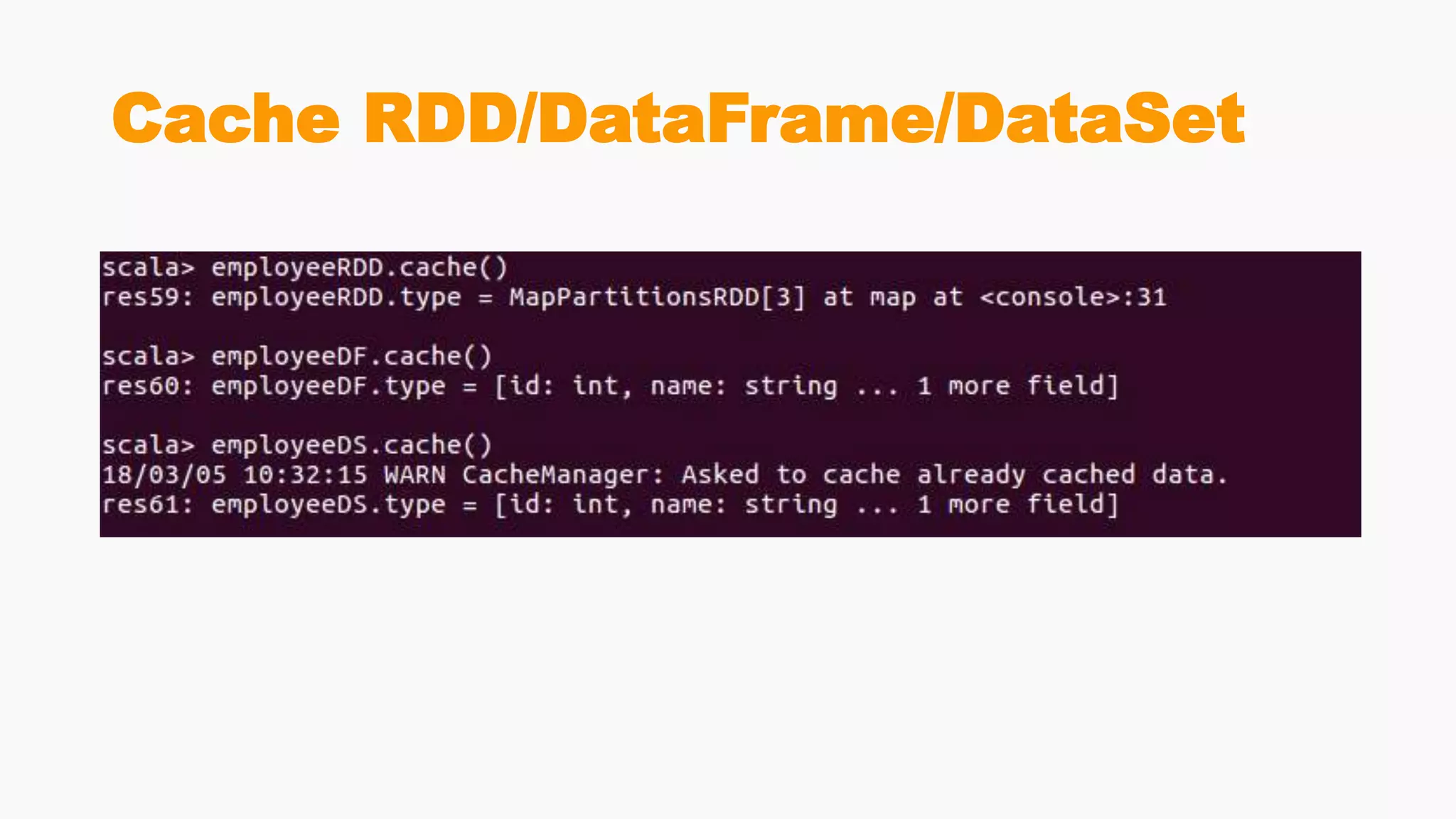
Explains caching strategies in Spark for efficient data processing across diverse applications and algorithms.
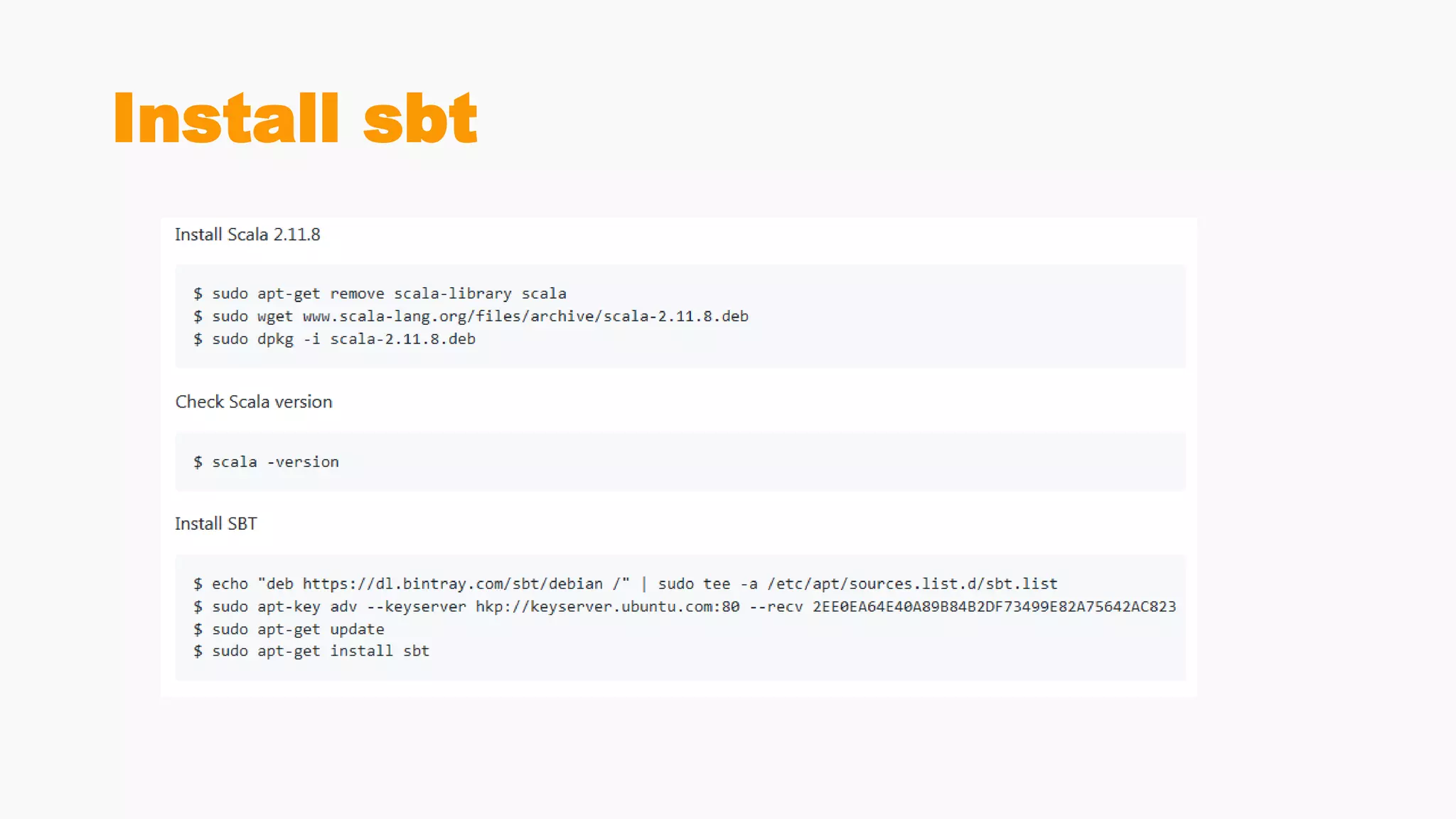
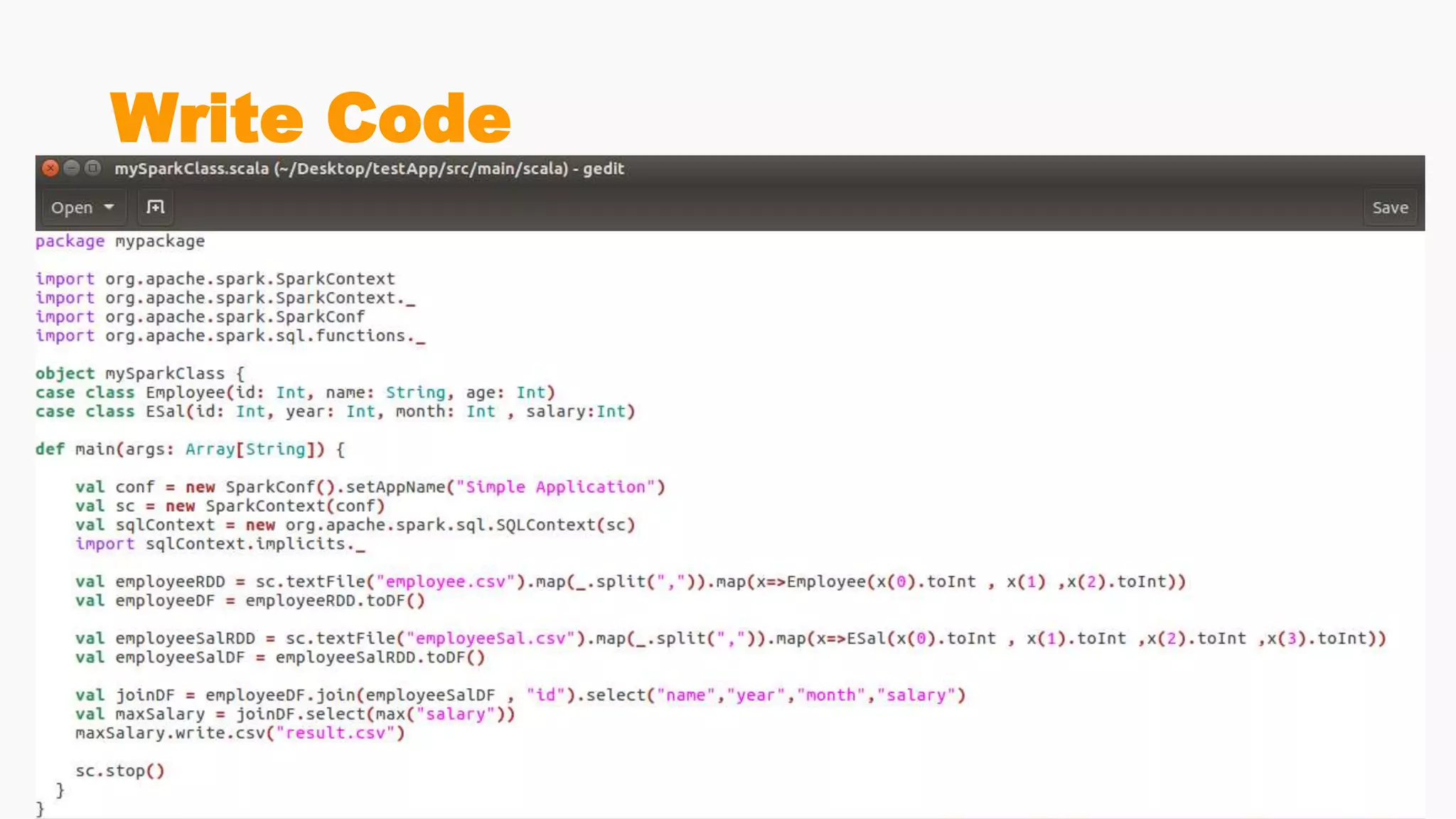
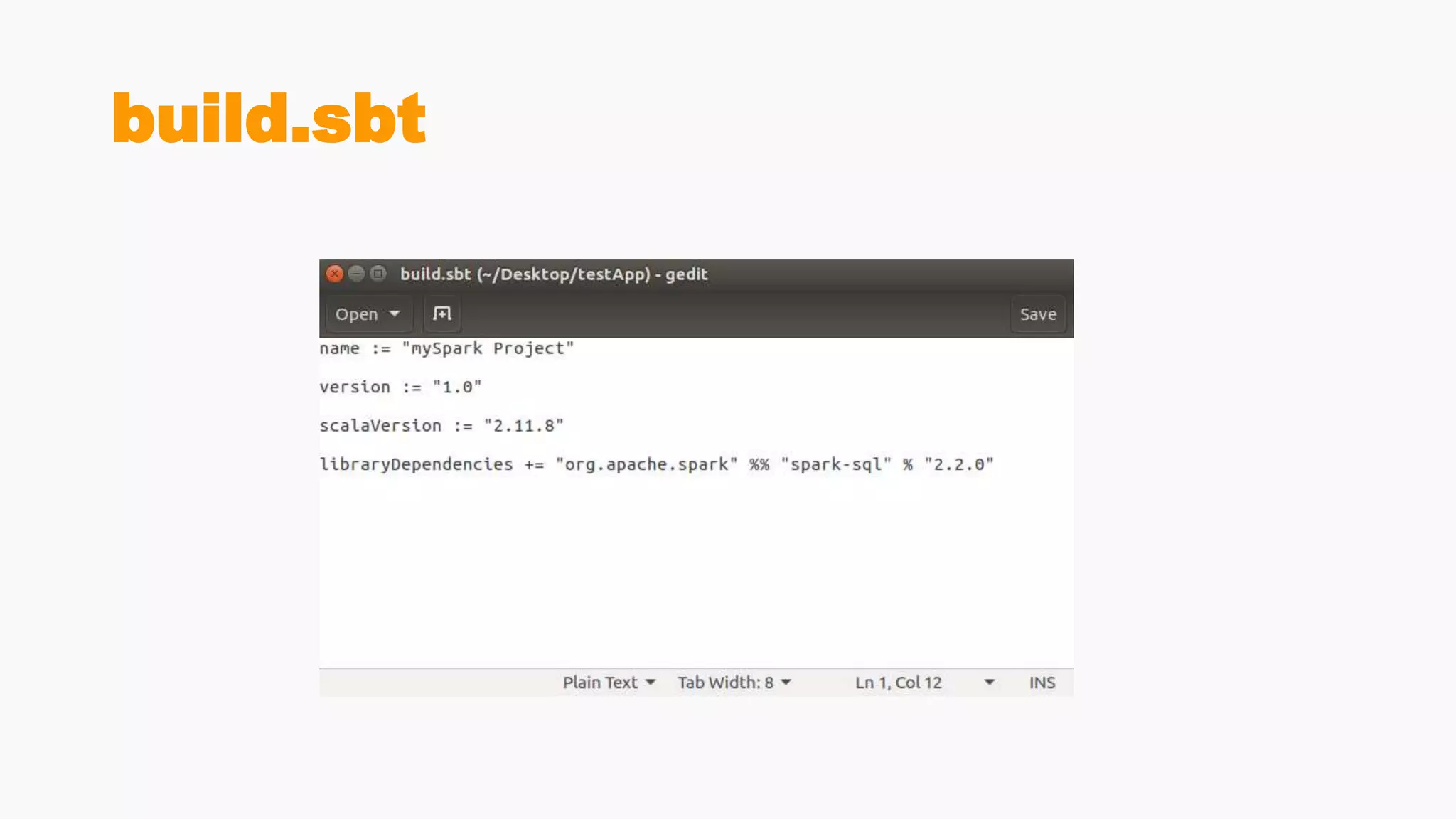
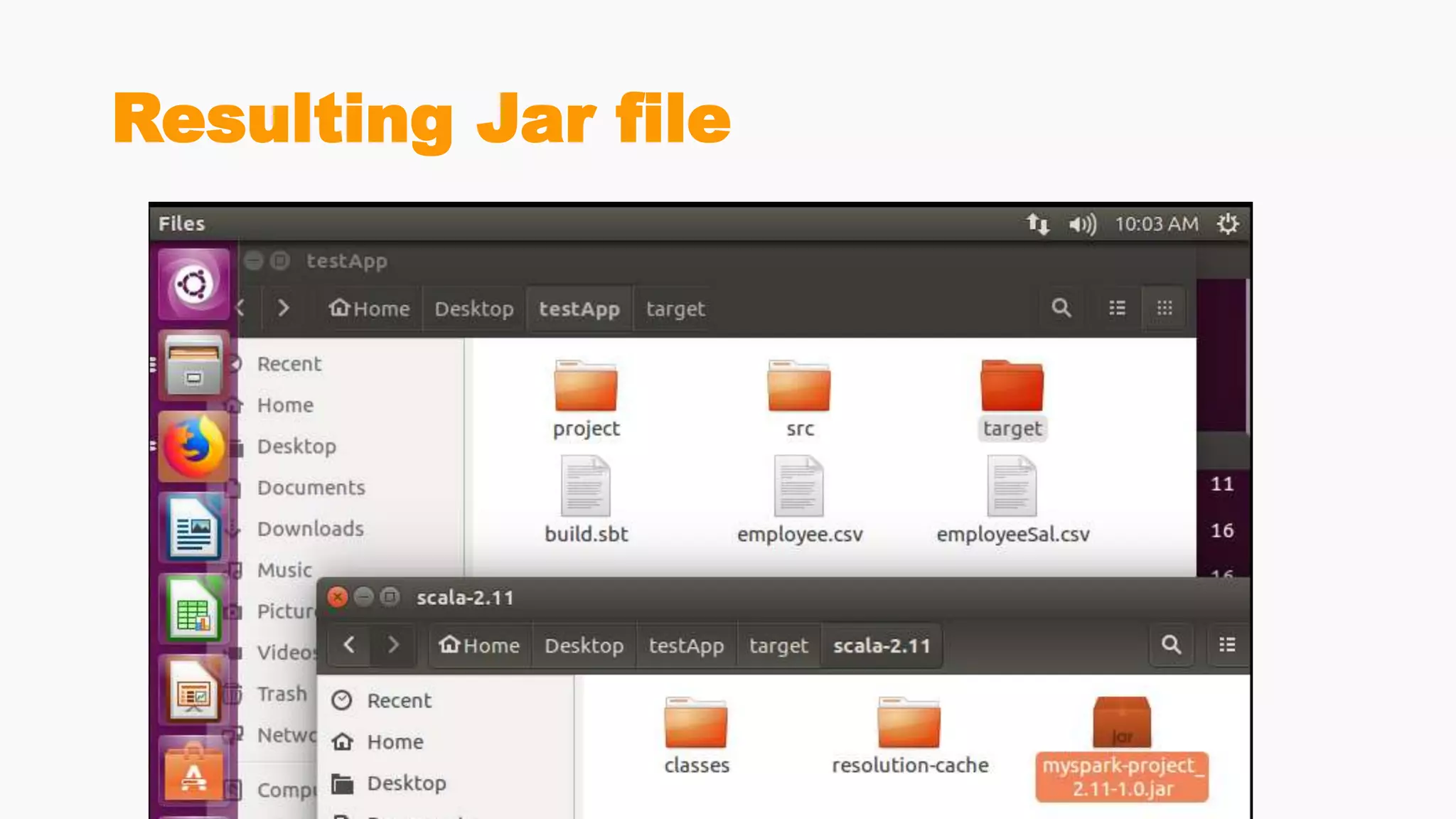
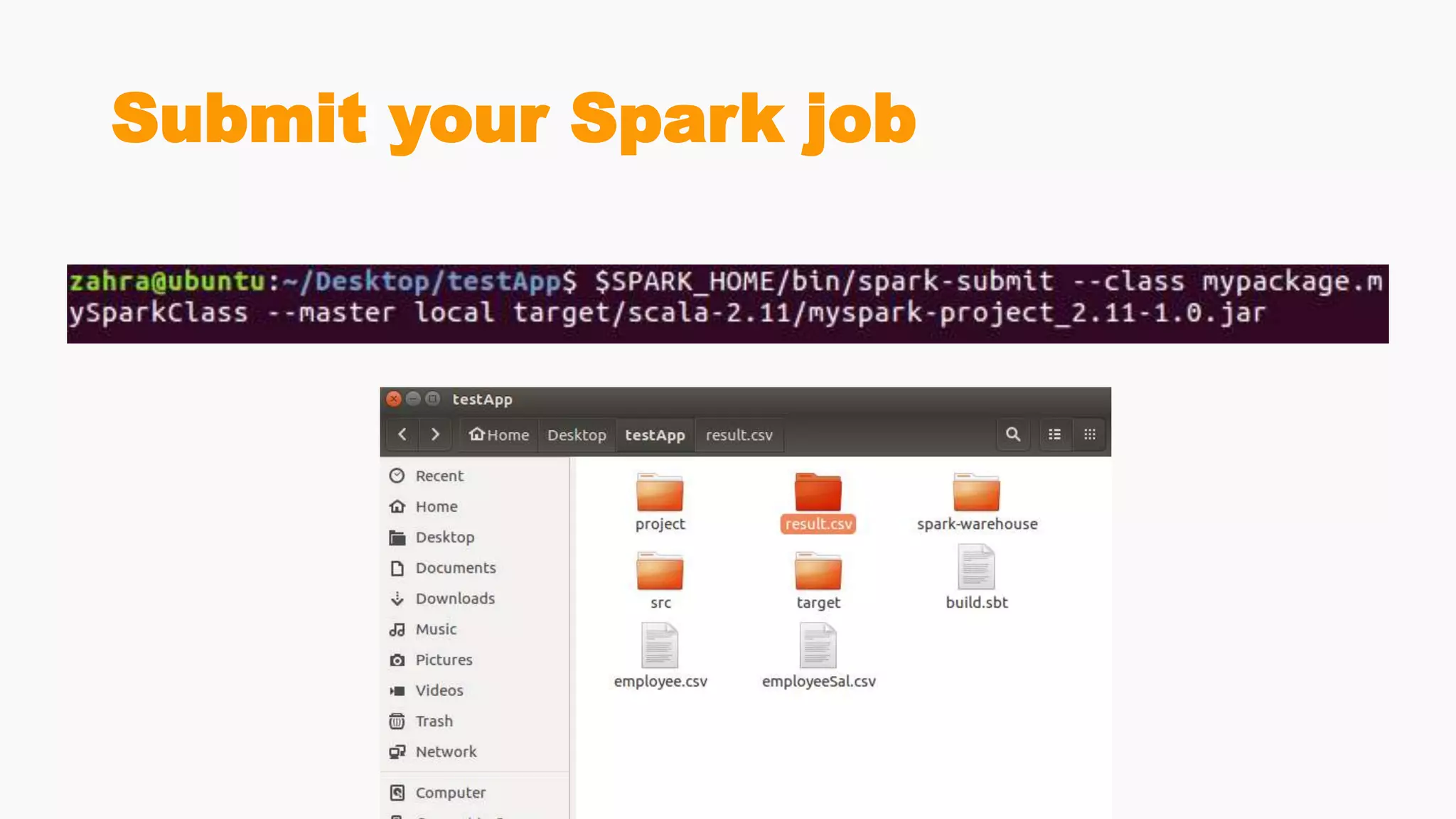
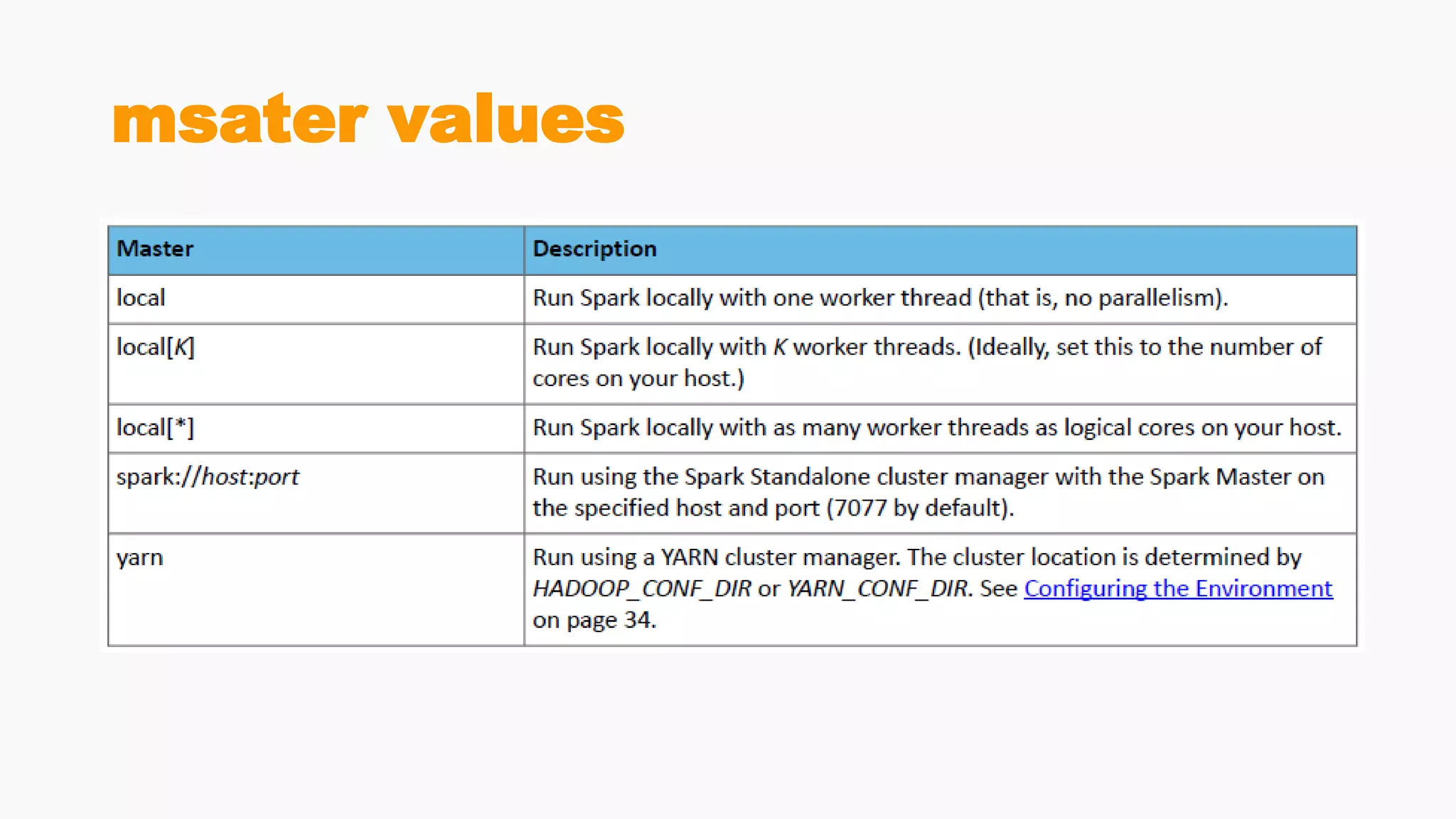
Steps for building and submitting Spark applications in Scala, including code writing, packaging, and deploying on clusters.

















































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

