














![Spark Context
• Main entry point to Spark functionality
• Available in shell as variable sc
• In standalone programs, you should make your own
• import org.apache.spark.SparkContext
• import org.apache.spark.SparkContext.
• val sc = new SparkContext(master, appName, [sparkHome], [jars])](https://image.slidesharecdn.com/apachesparkmaster-150830121025-lva1-app6892/75/Apache-Spark-Core-25-2048.jpg)











![Fault Resiliency
• RDDs track series of transformations used to build them (their lineage) to re-compute lost
data
• messages = textFile.filter(lambda s: s.startsWith(“ERROR”)).map(lambda s: s.split(“t”)[2])
HDFS File Filtered RDD Mapped RDD
filter
(func = startsWith(…))
map
(func = split(...))](https://image.slidesharecdn.com/apachesparkmaster-150830121025-lva1-app6892/75/Apache-Spark-Core-45-2048.jpg)












![Transformation Functions
• map(func)
• filter(func)
• flatMap(func)
• mapPartitions(func)
• mapPartitionsWithIndex(func)
• sample(withReplacement, fraction, seed)
• union(otherDataset)
• intersection(otherDataset)
• distinct([numTasks]))
• groupByKey([numTasks])
• reduceByKey(func, [numTasks])](https://image.slidesharecdn.com/apachesparkmaster-150830121025-lva1-app6892/75/Apache-Spark-Core-62-2048.jpg)
![Transformation Functions
• aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
• sortByKey([ascending], [numTasks])
• join(otherDataset, [numTasks])
• cogroup(otherDataset, [numTasks])
• cartesian(otherDataset)
• pipe(command, [envVars])
• coalesce(numPartitions)
• repartition(numPartitions)
• repartitionAndSortWithinPartitions(partitioner)](https://image.slidesharecdn.com/apachesparkmaster-150830121025-lva1-app6892/75/Apache-Spark-Core-63-2048.jpg)
![Action Functions
• reduce(func)
• collect()
• count()
• first()
• take(n)
• takeSample(withReplacement, num,
[seed])
• takeOrdered(n, [ordering])
• saveAsTextFile(path)
• saveAsSequenceFile(path)
(Java and Scala)
• saveAsObjectFile(path)
(Java and Scala)
• countByKey()
• foreach(func)](https://image.slidesharecdn.com/apachesparkmaster-150830121025-lva1-app6892/75/Apache-Spark-Core-64-2048.jpg)

















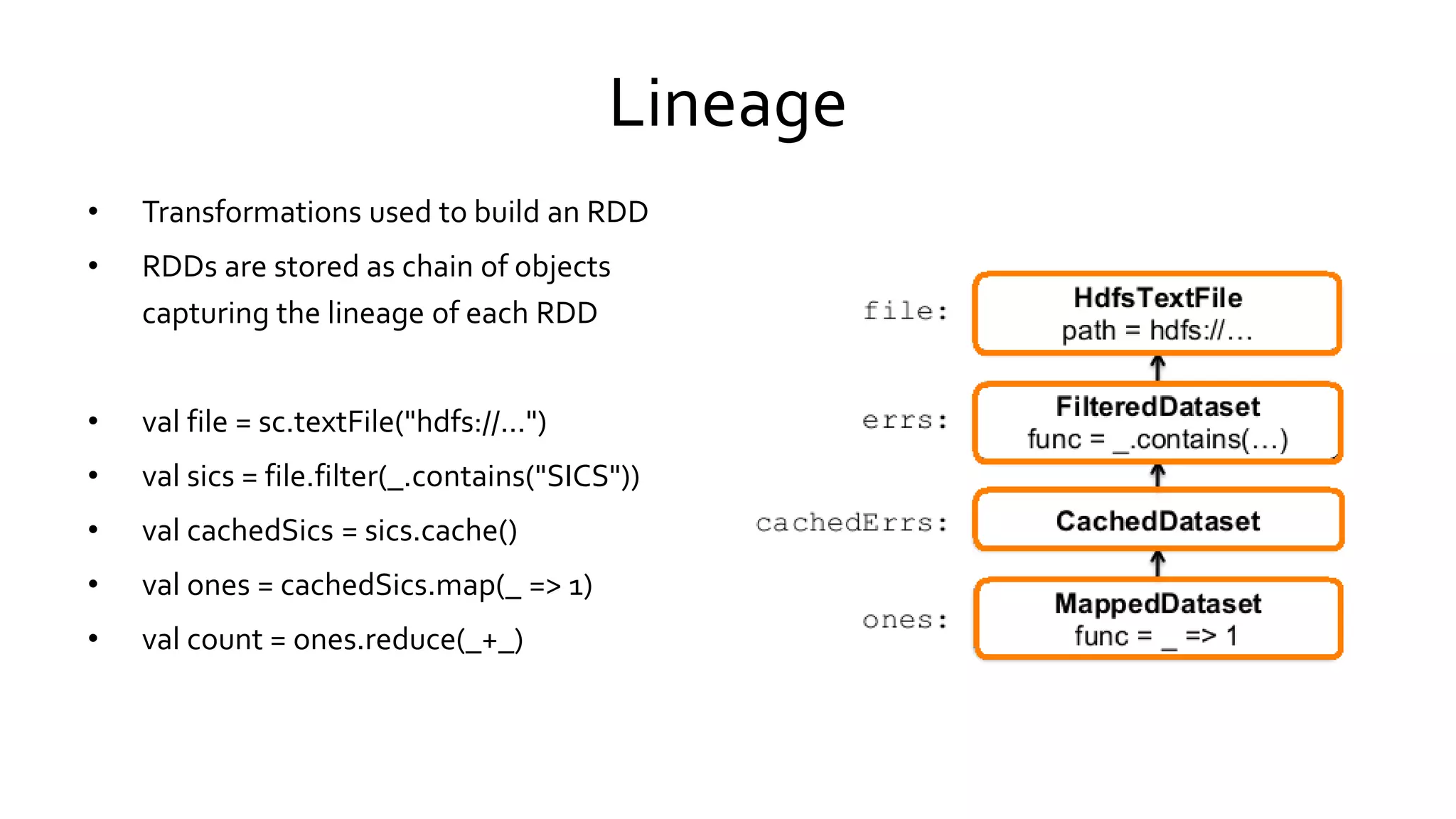



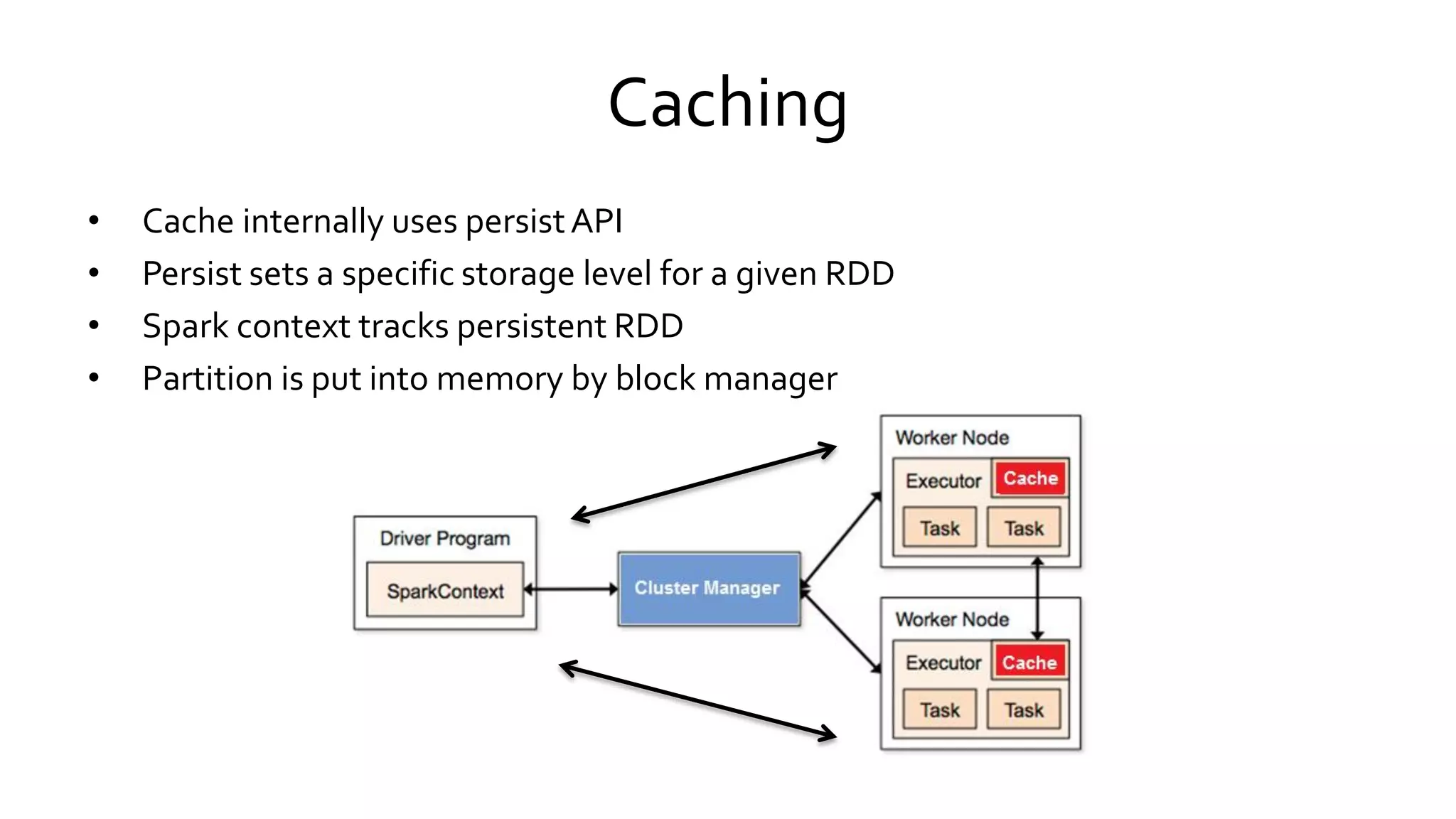


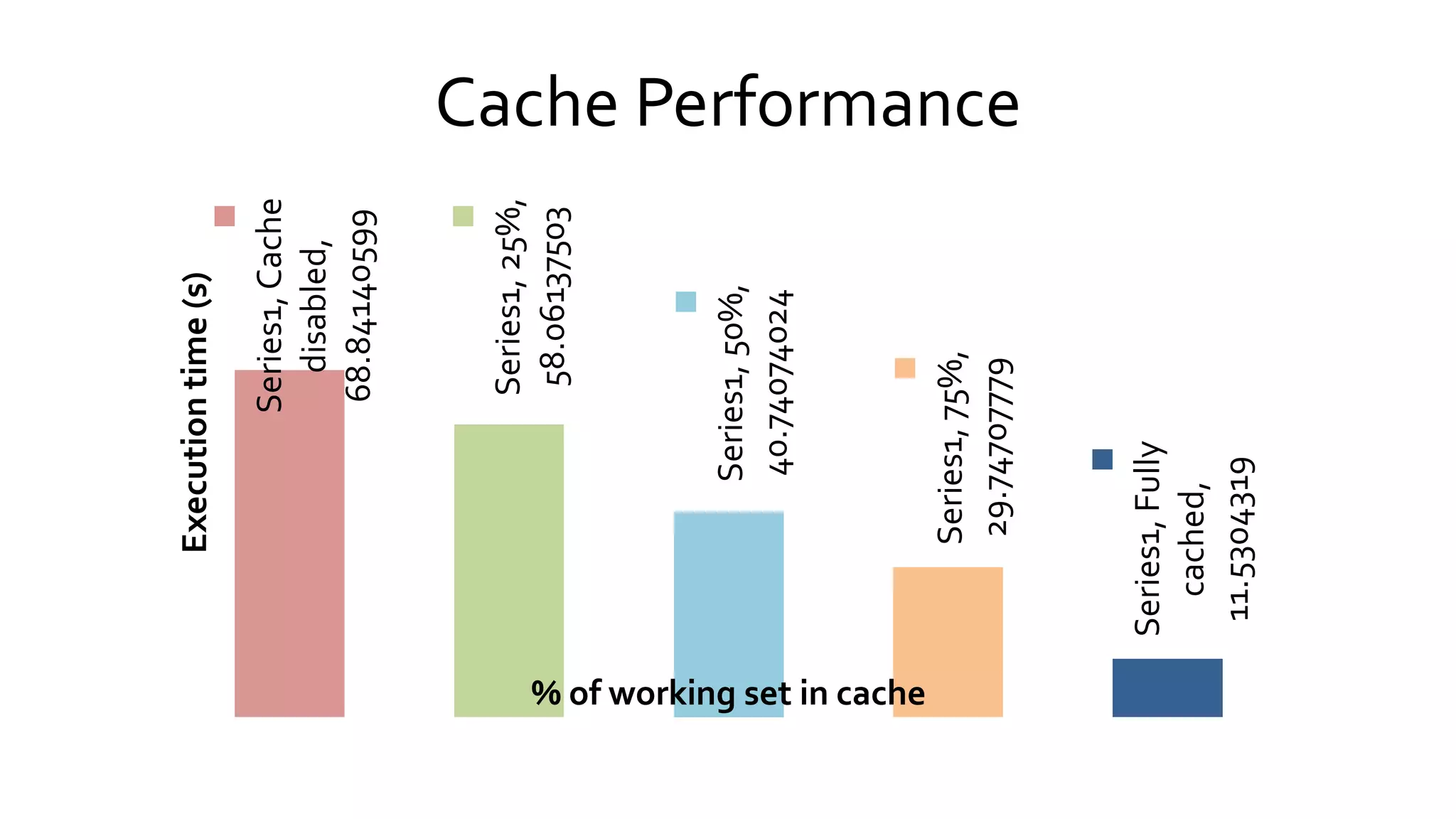









Spark is an open-source cluster computing framework that uses in-memory processing to allow data sharing across jobs for faster iterative queries and interactive analytics, it uses Resilient Distributed Datasets (RDDs) that can survive failures through lineage tracking and supports programming in Scala, Java, and Python for batch, streaming, and machine learning workloads.
Introduces Apache Spark, an open-source cluster computing framework for real-time data analysis, emphasizing in-memory data sharing, scalability, and programming model.
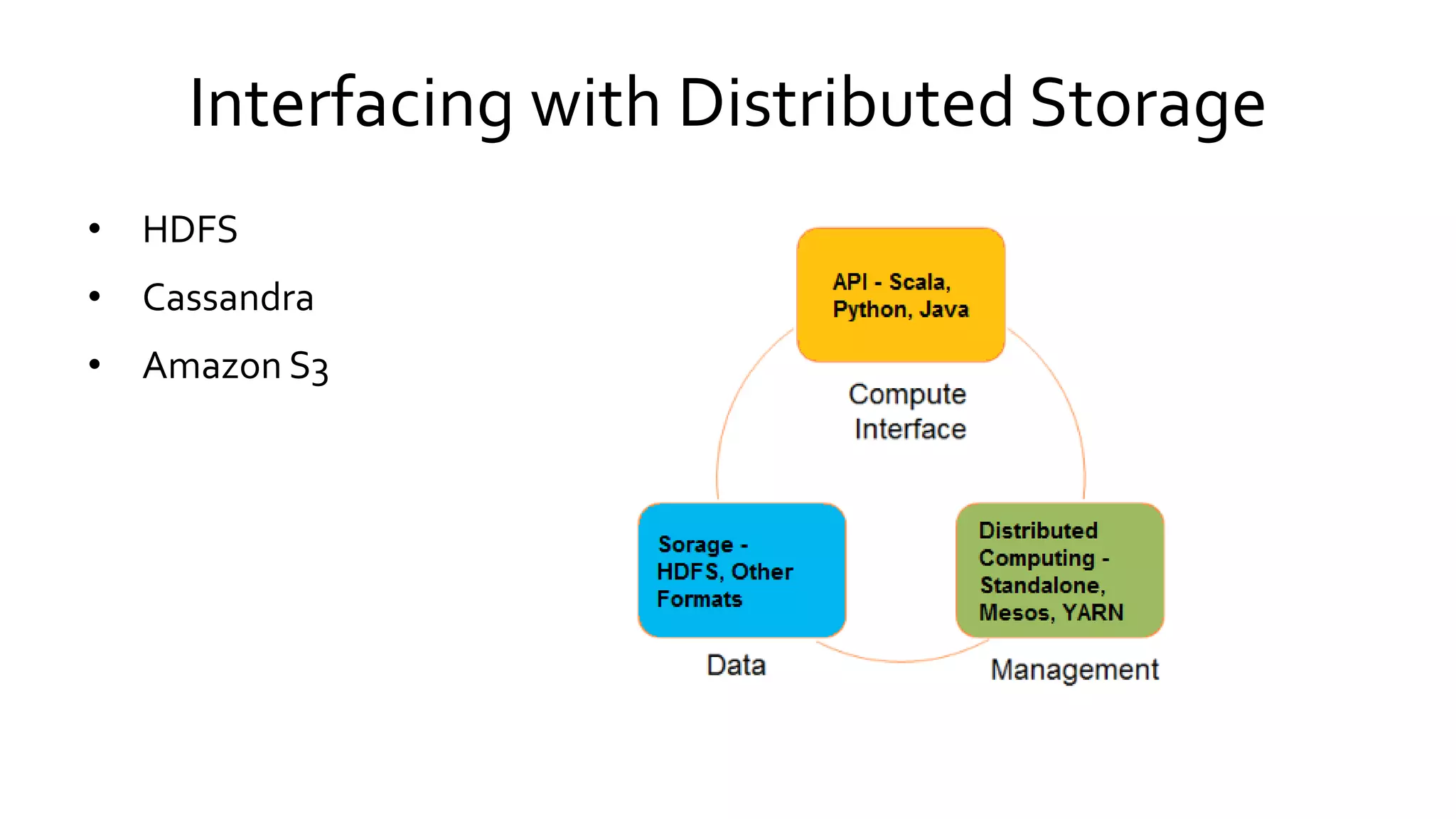
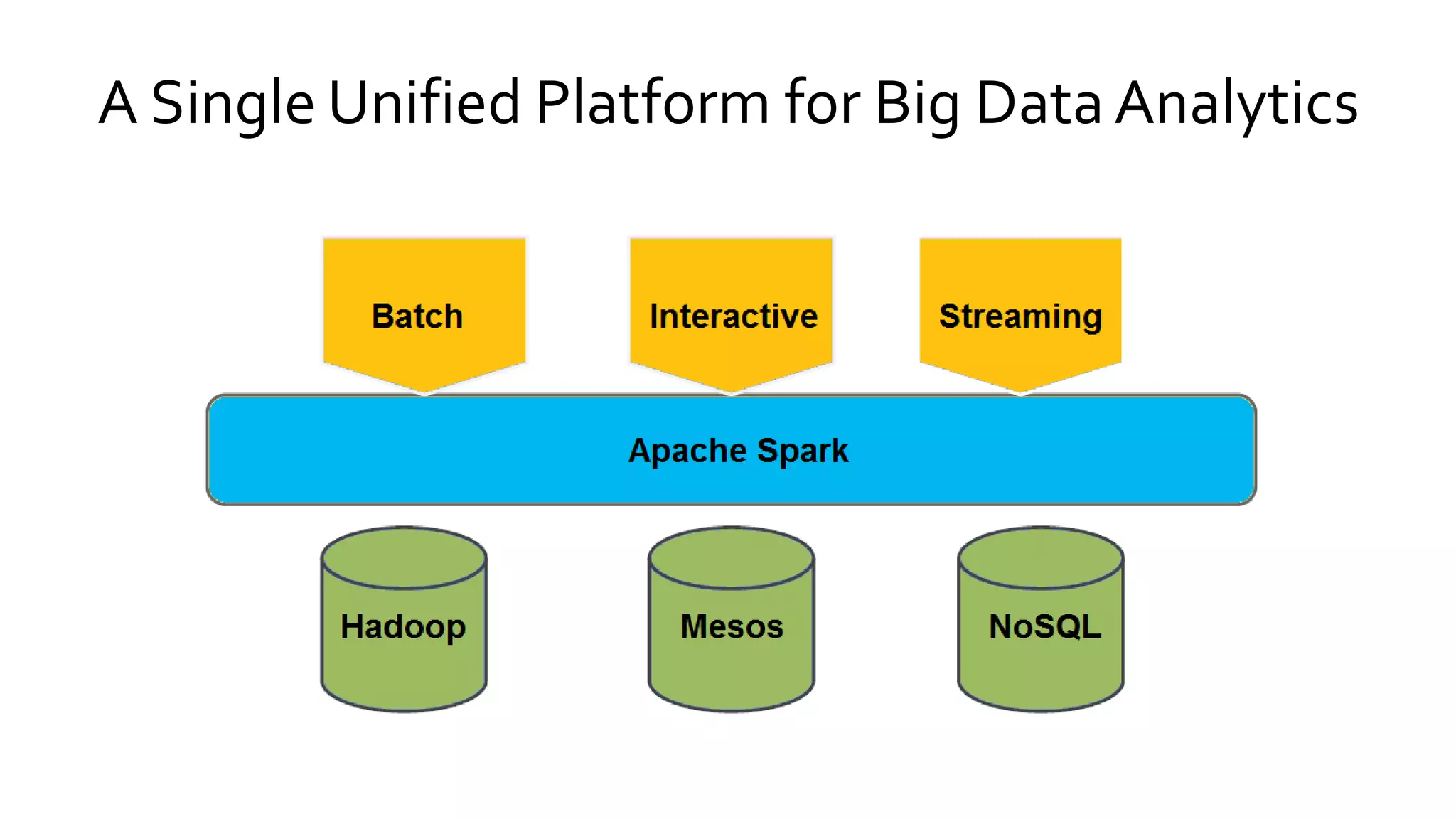
Details types of Spark deployments and its unified platform capabilities for big data analytics, highlighting compatibility with various storage systems.
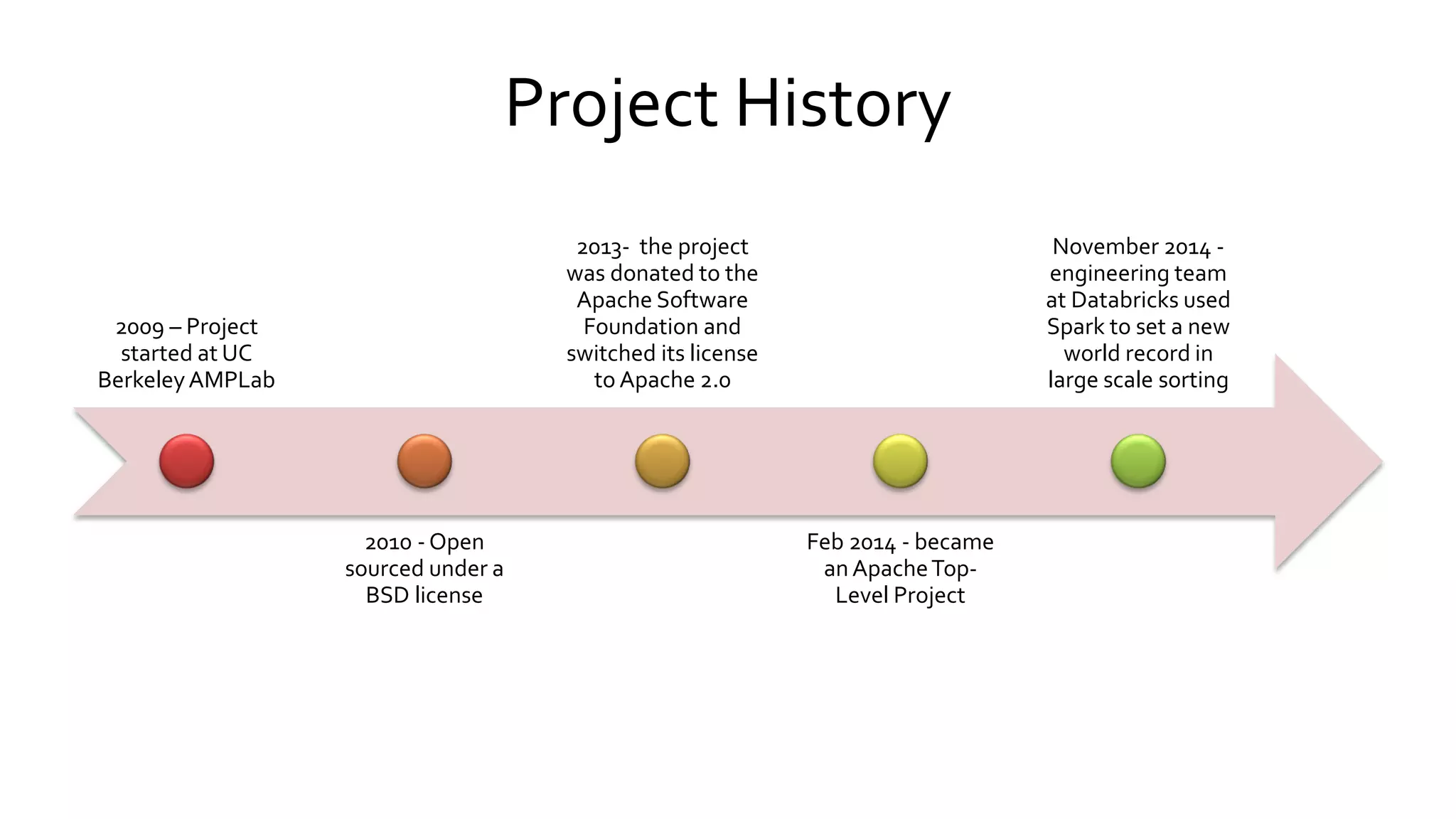
Chronicles the history of Spark from its inception at UC Berkeley to its rise as a top-level Apache project, noting its active community contributions.
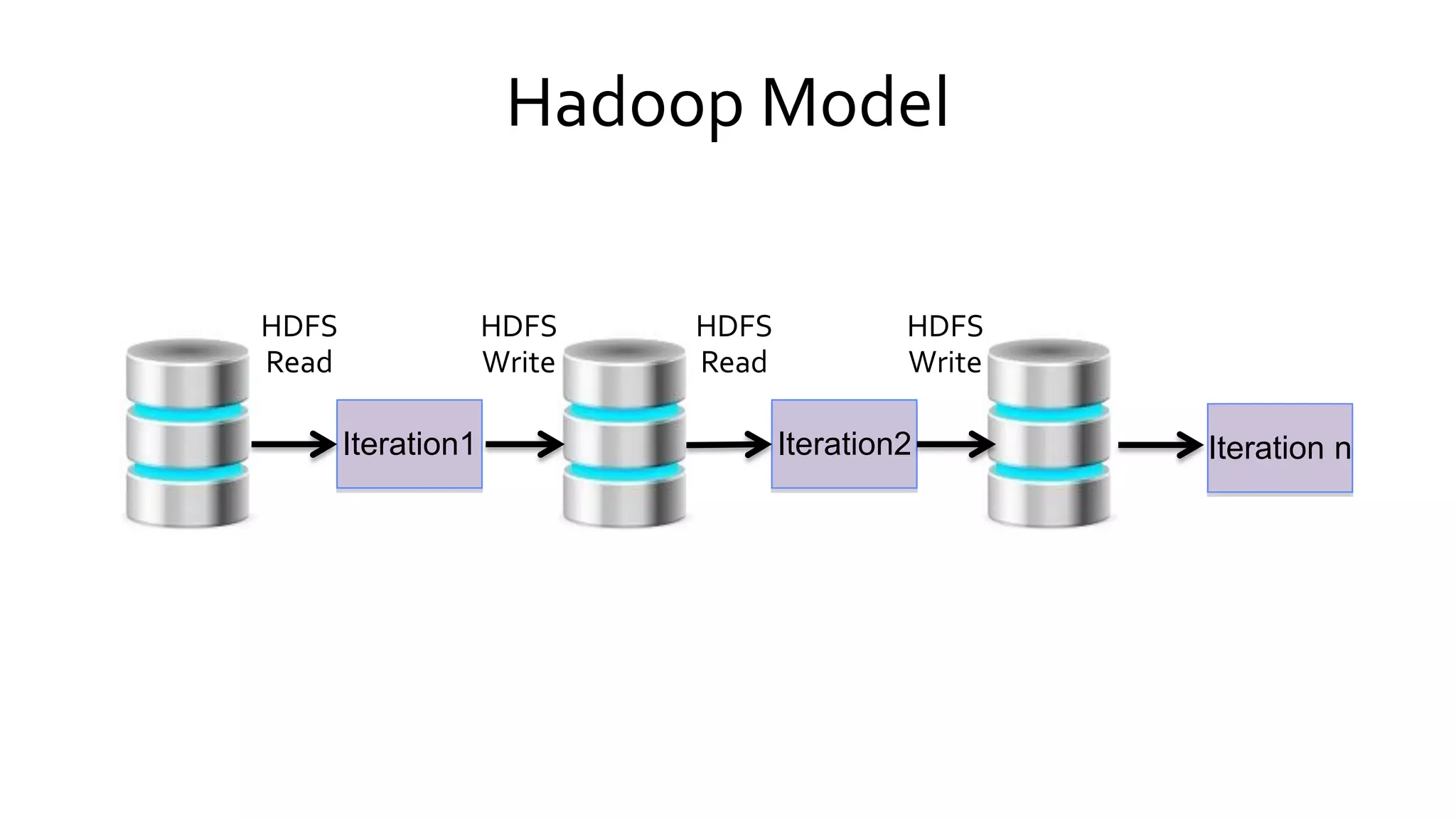
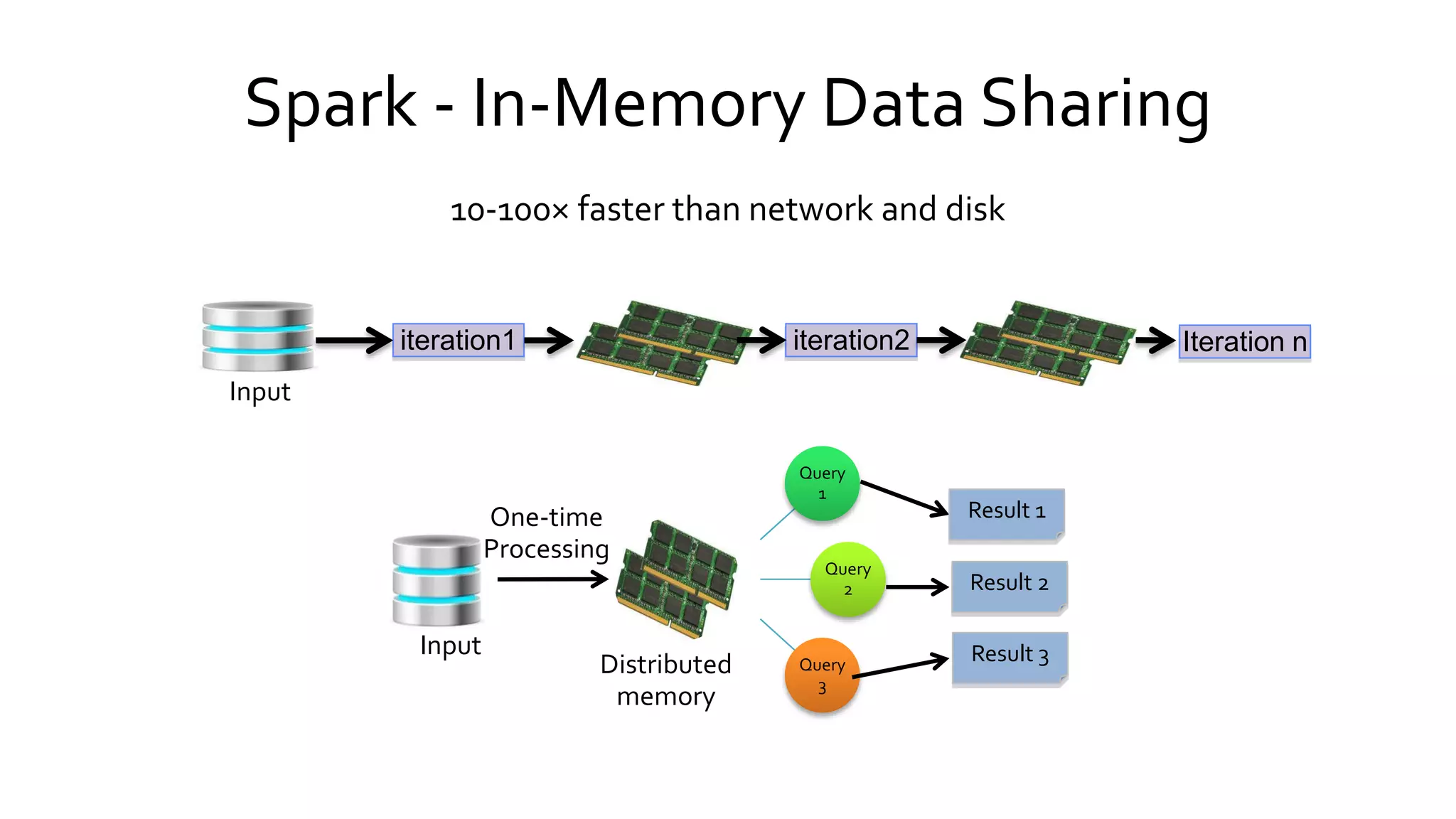
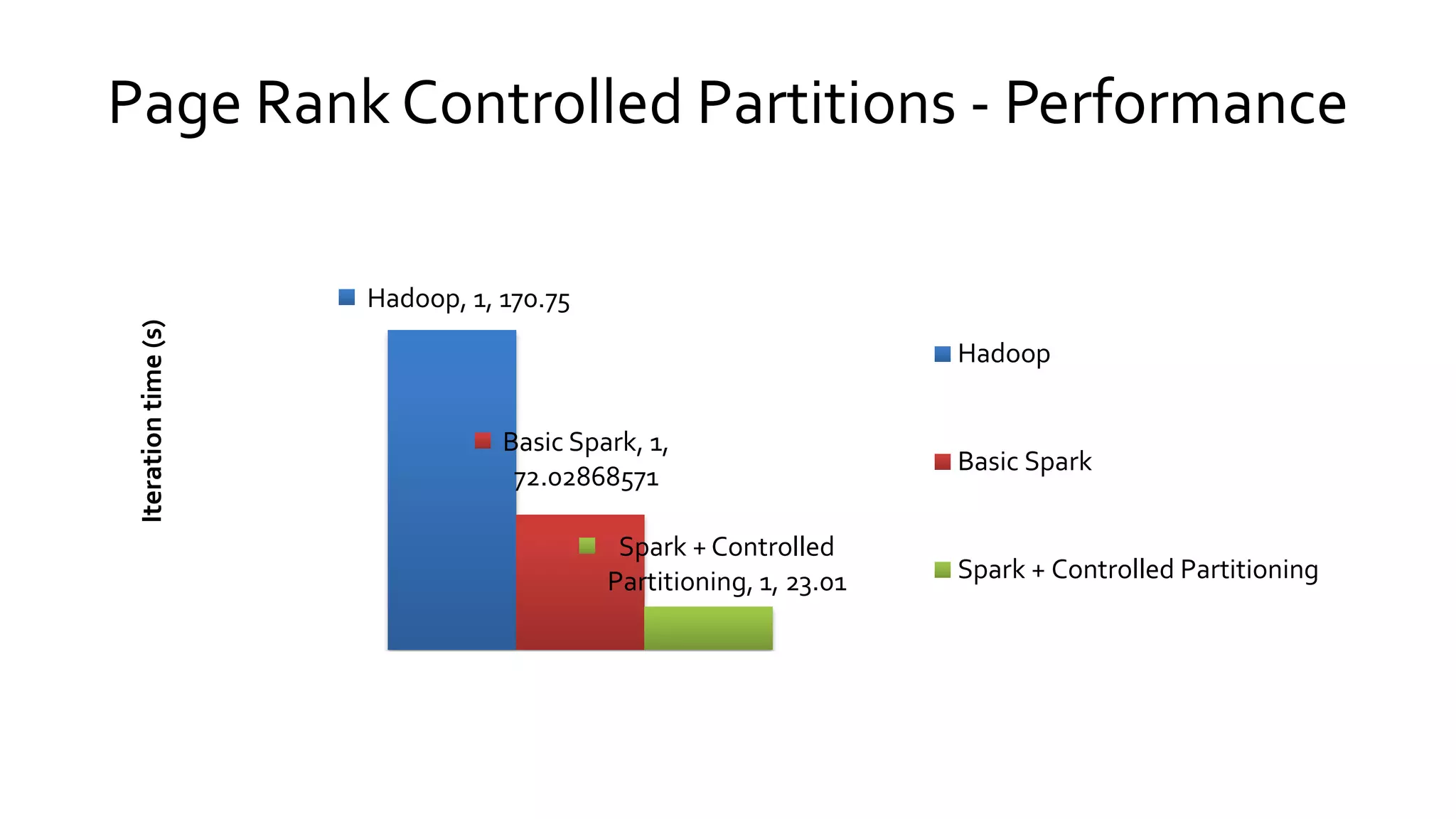
Compares Hadoop's data processing model with Spark's in-memory capabilities, emphasizing Spark's speed and efficiency over traditional disk-based processing.
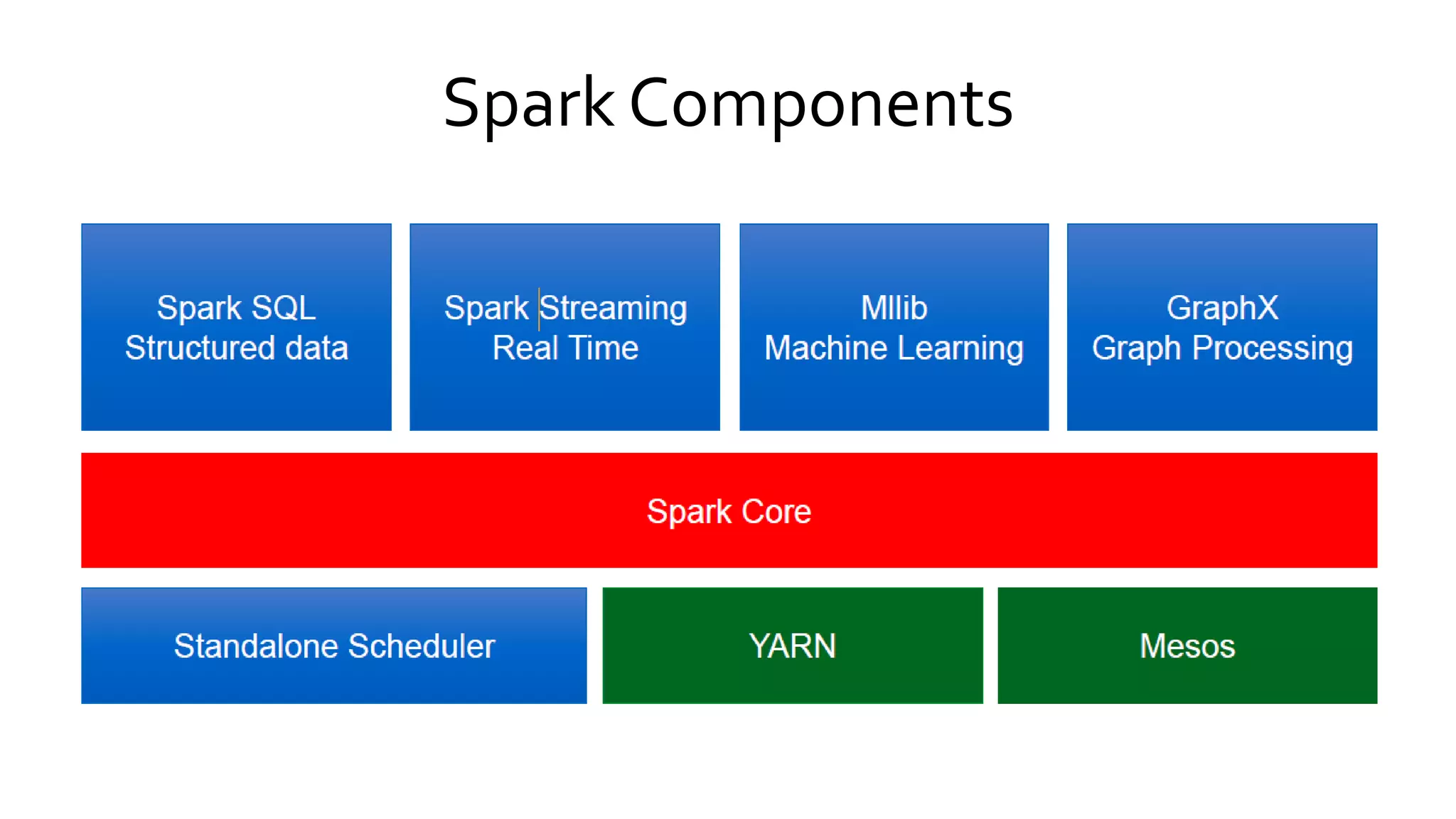
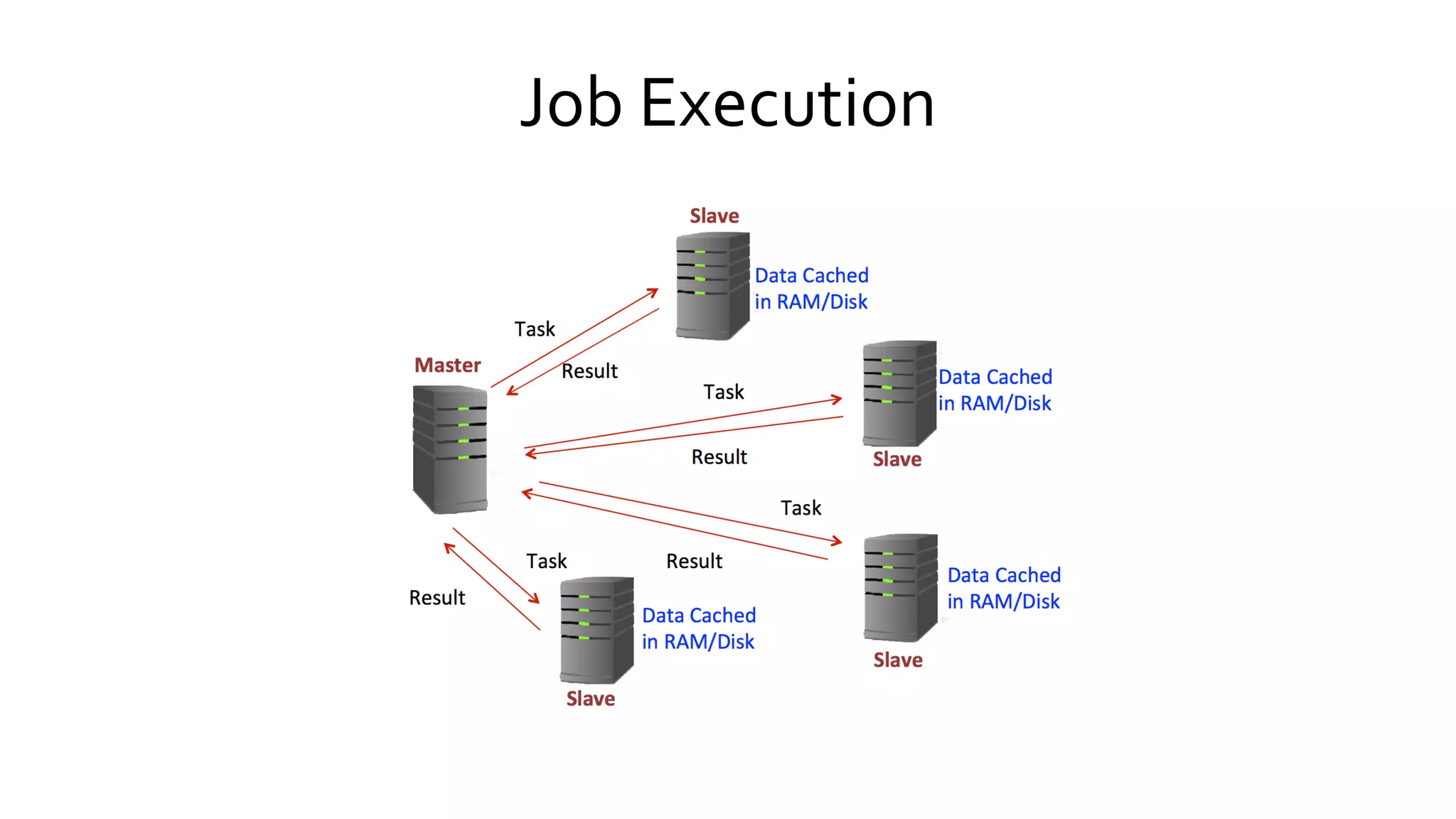
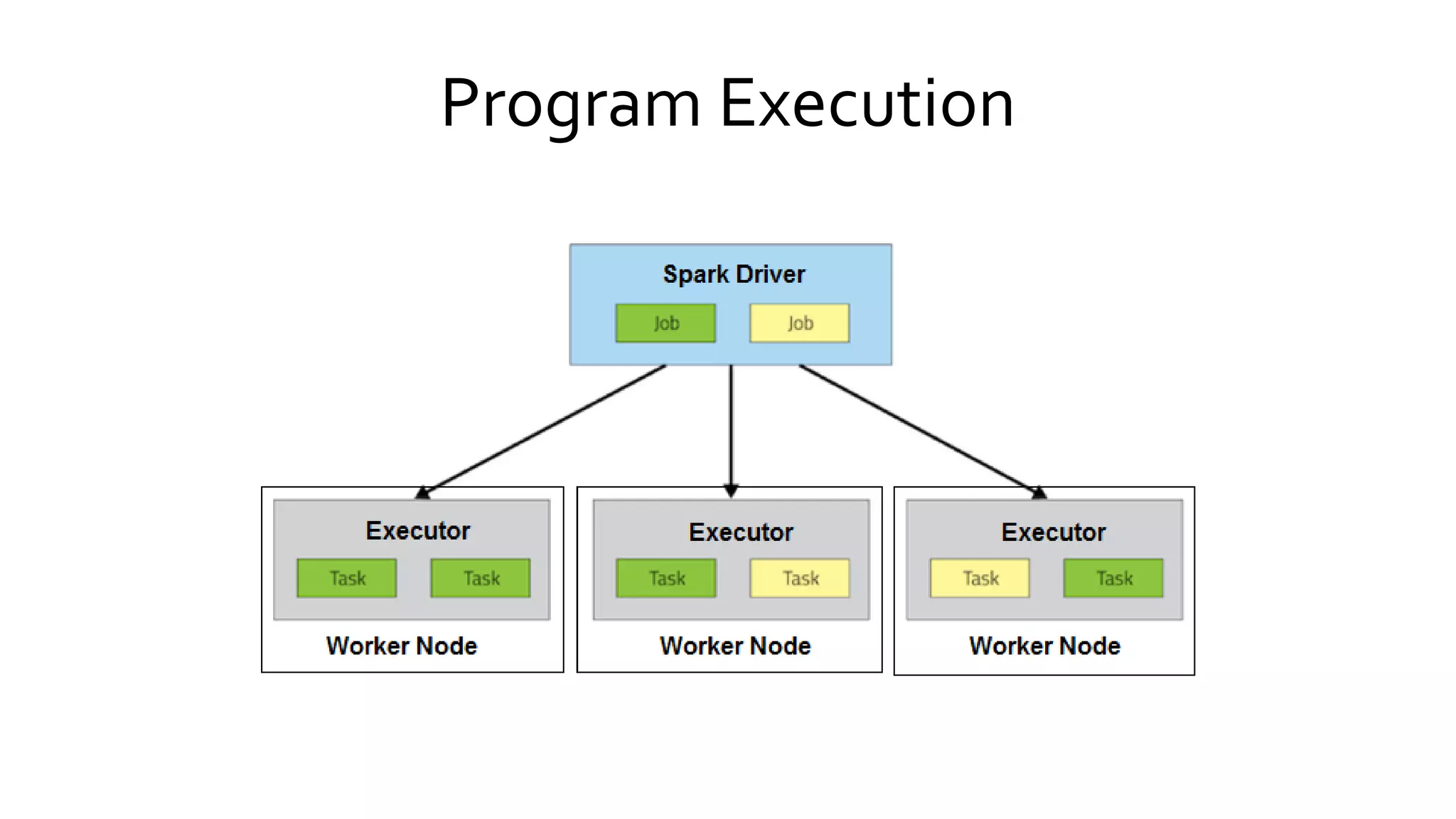
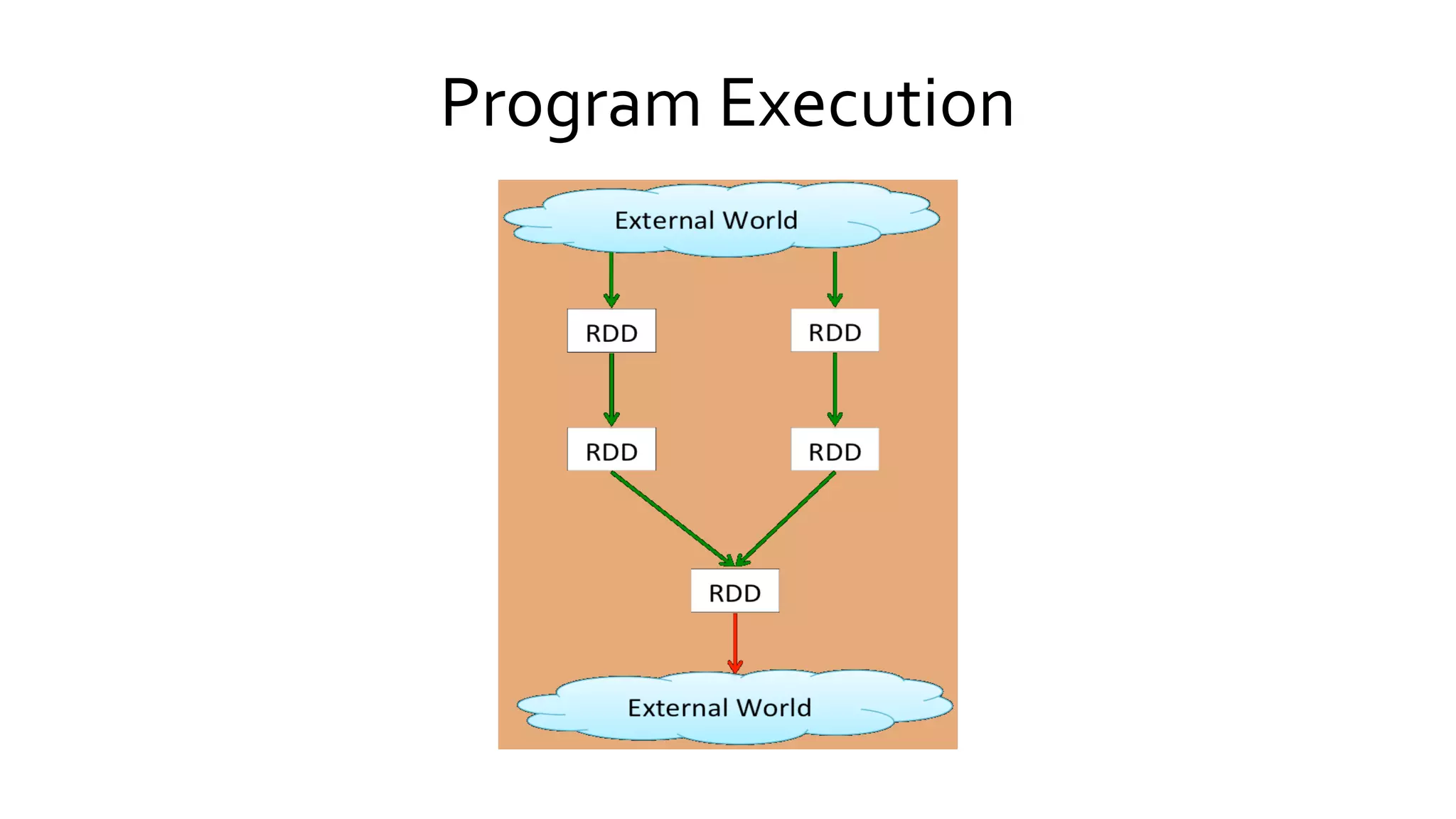
Explains Spark's execution model focusing on the in-memory sharing of data, and outlines its core components and their functionalities.
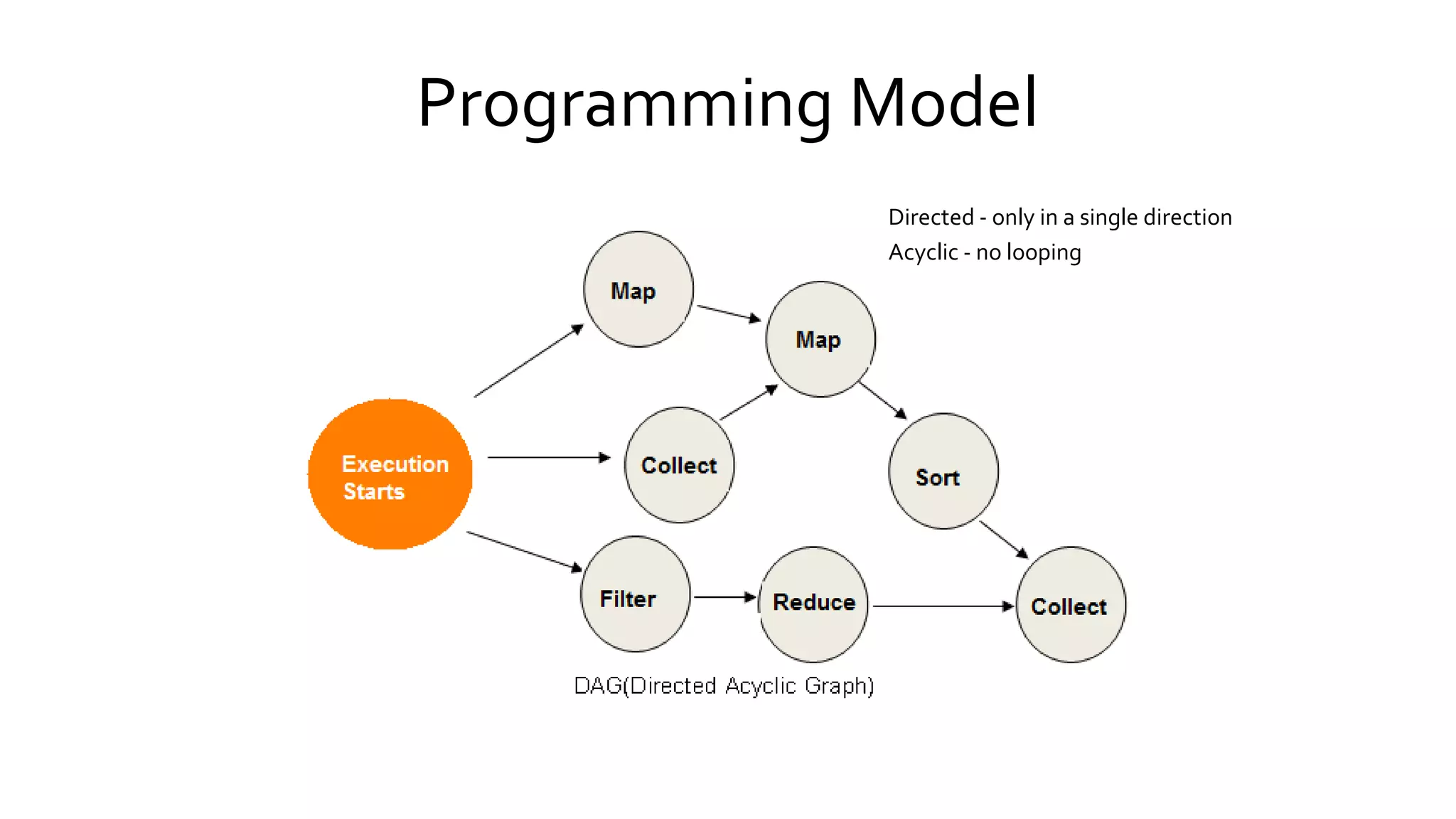
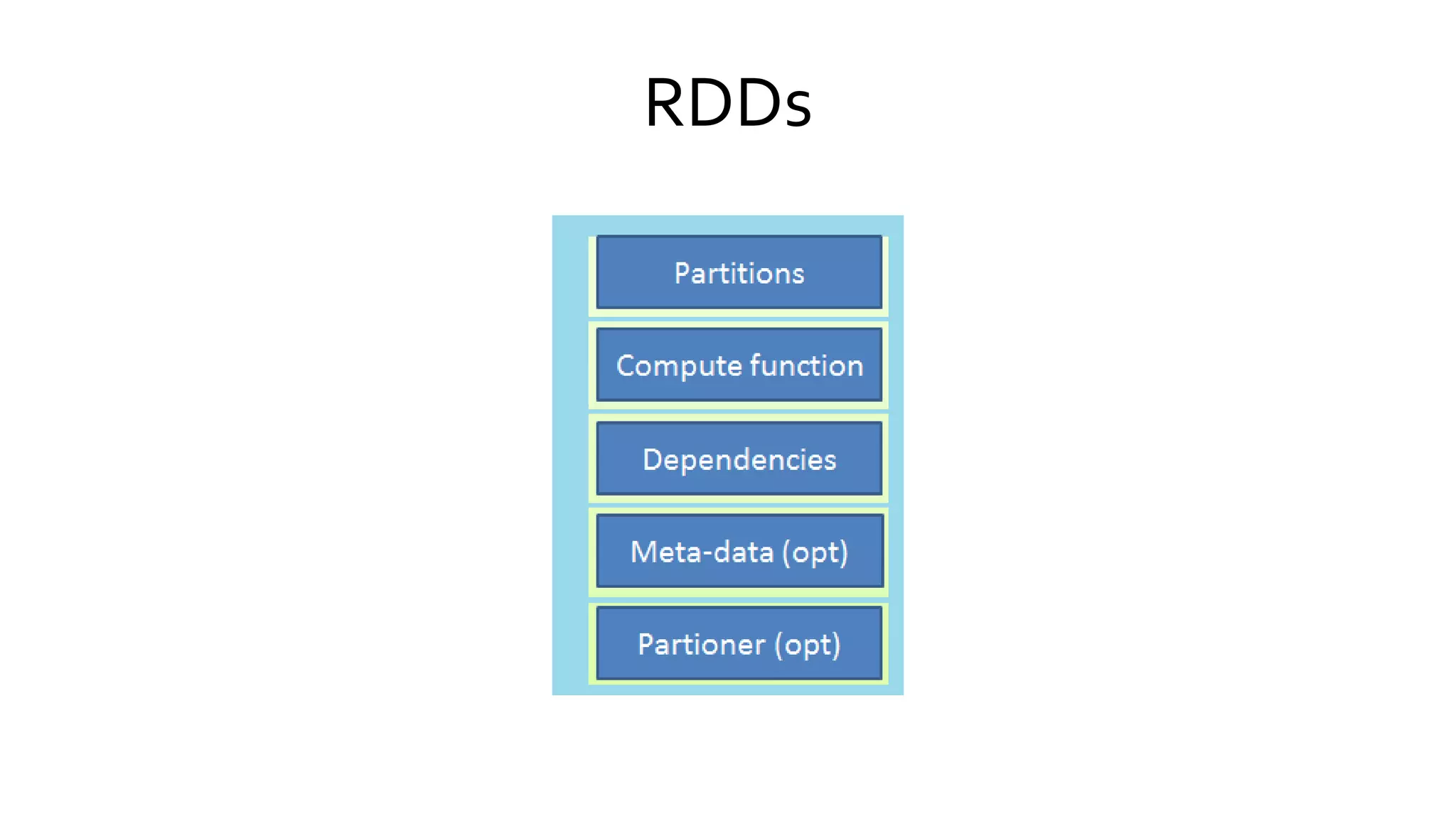
Explores Spark's programming model based on RDDs (Resilient Distributed Datasets), detailing their properties, transformations, and resilience.
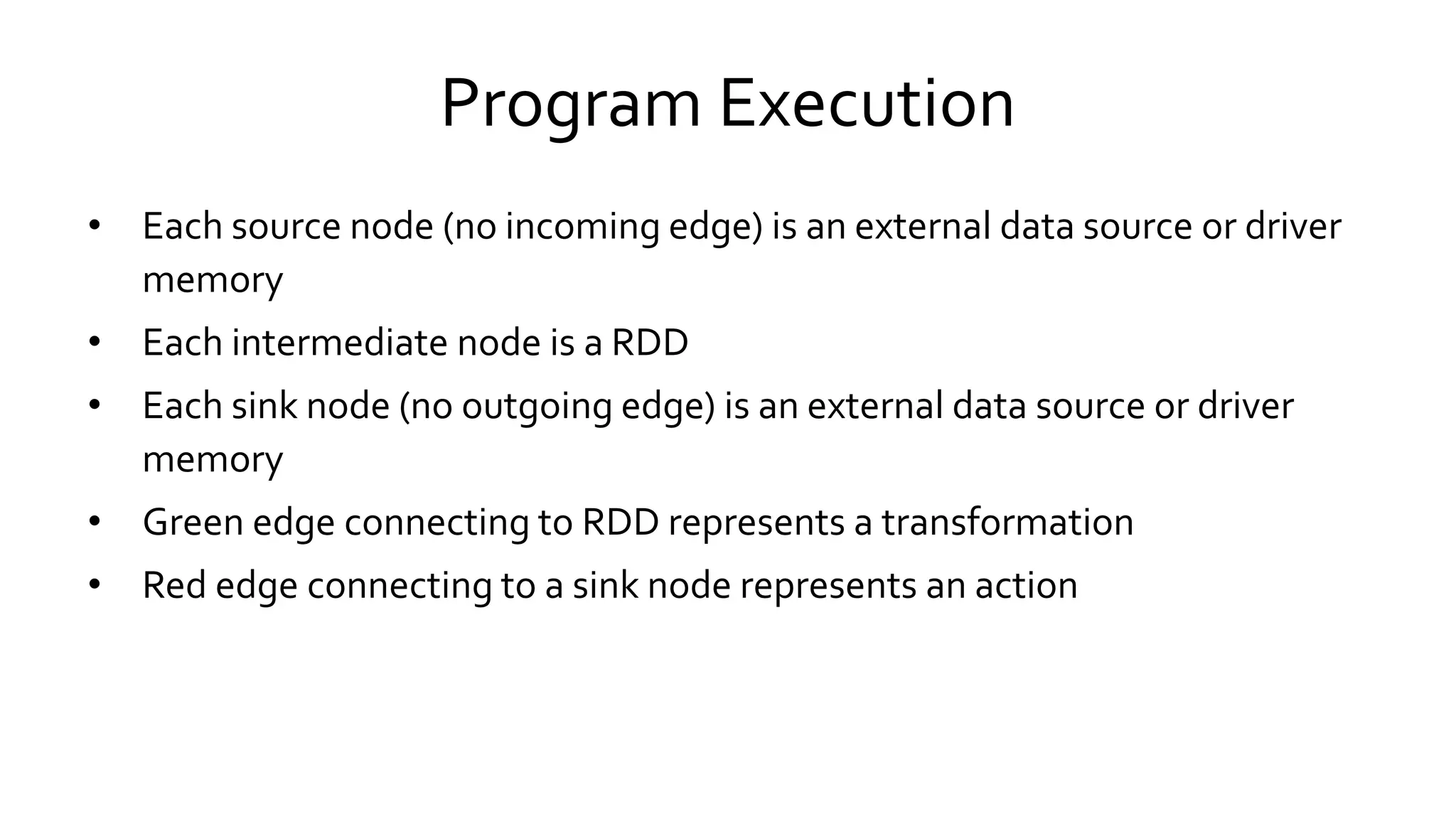
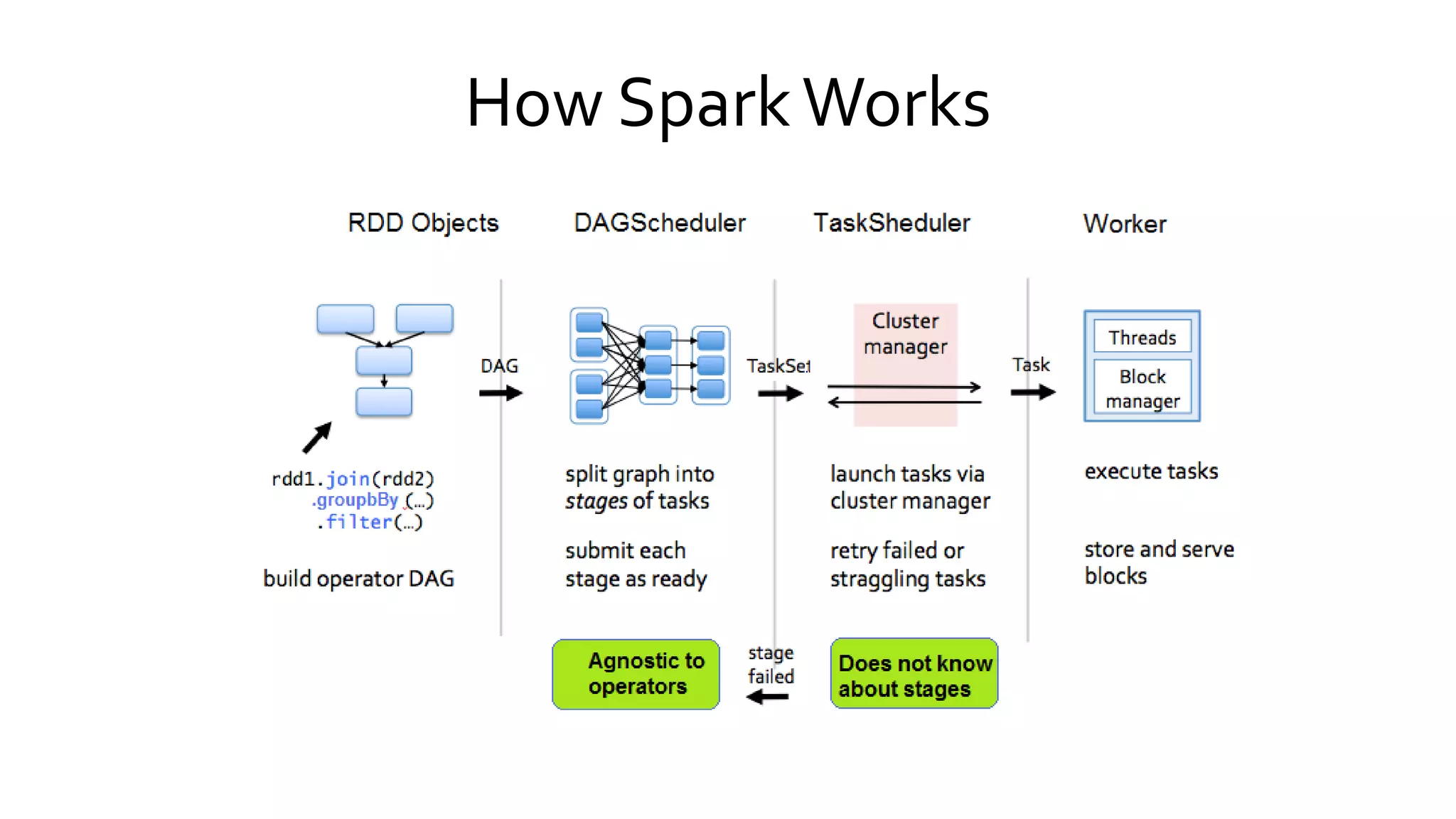
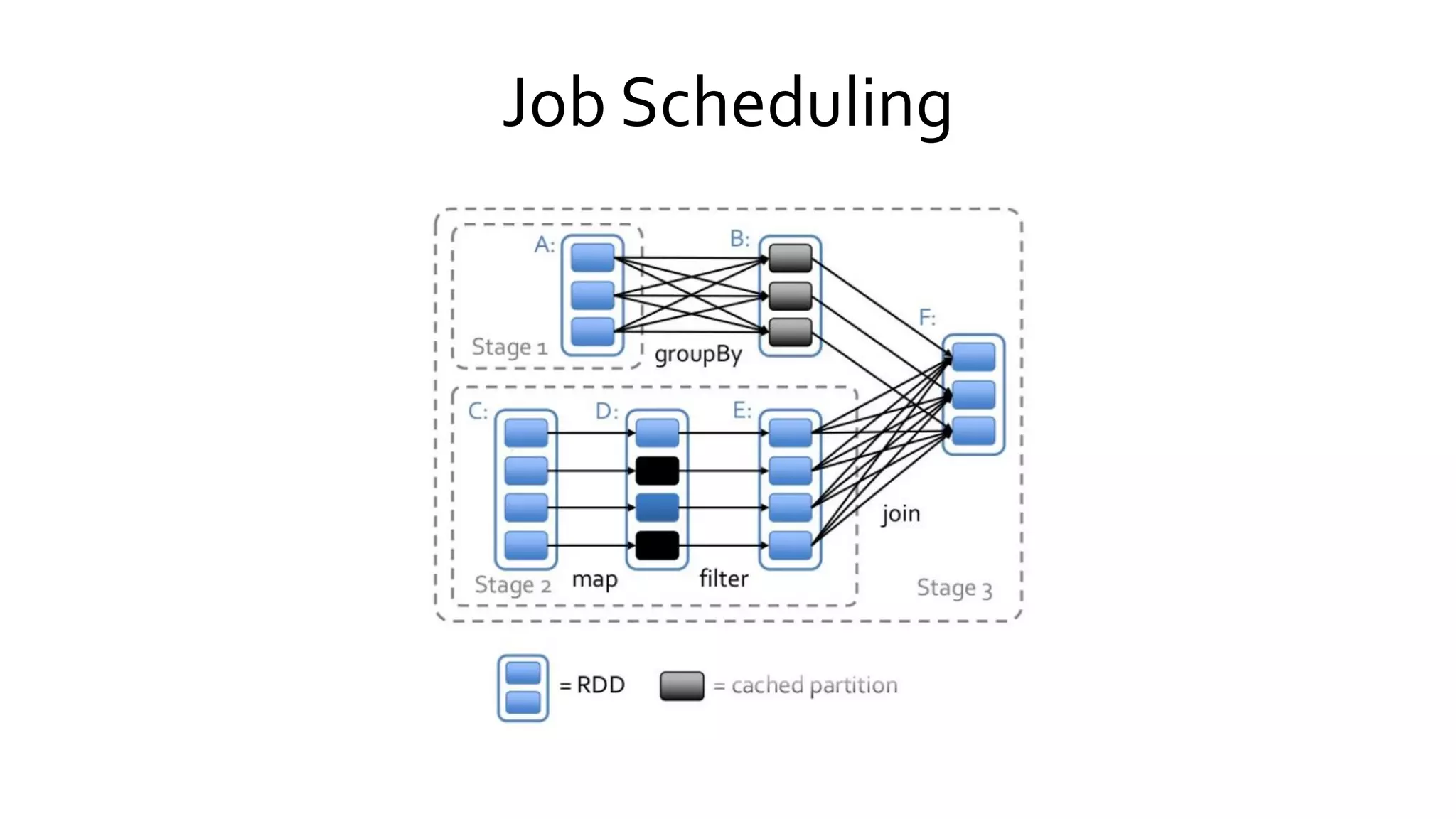
Describes how Spark executes jobs including DAG graph construction, scheduling, and task execution across the cluster.
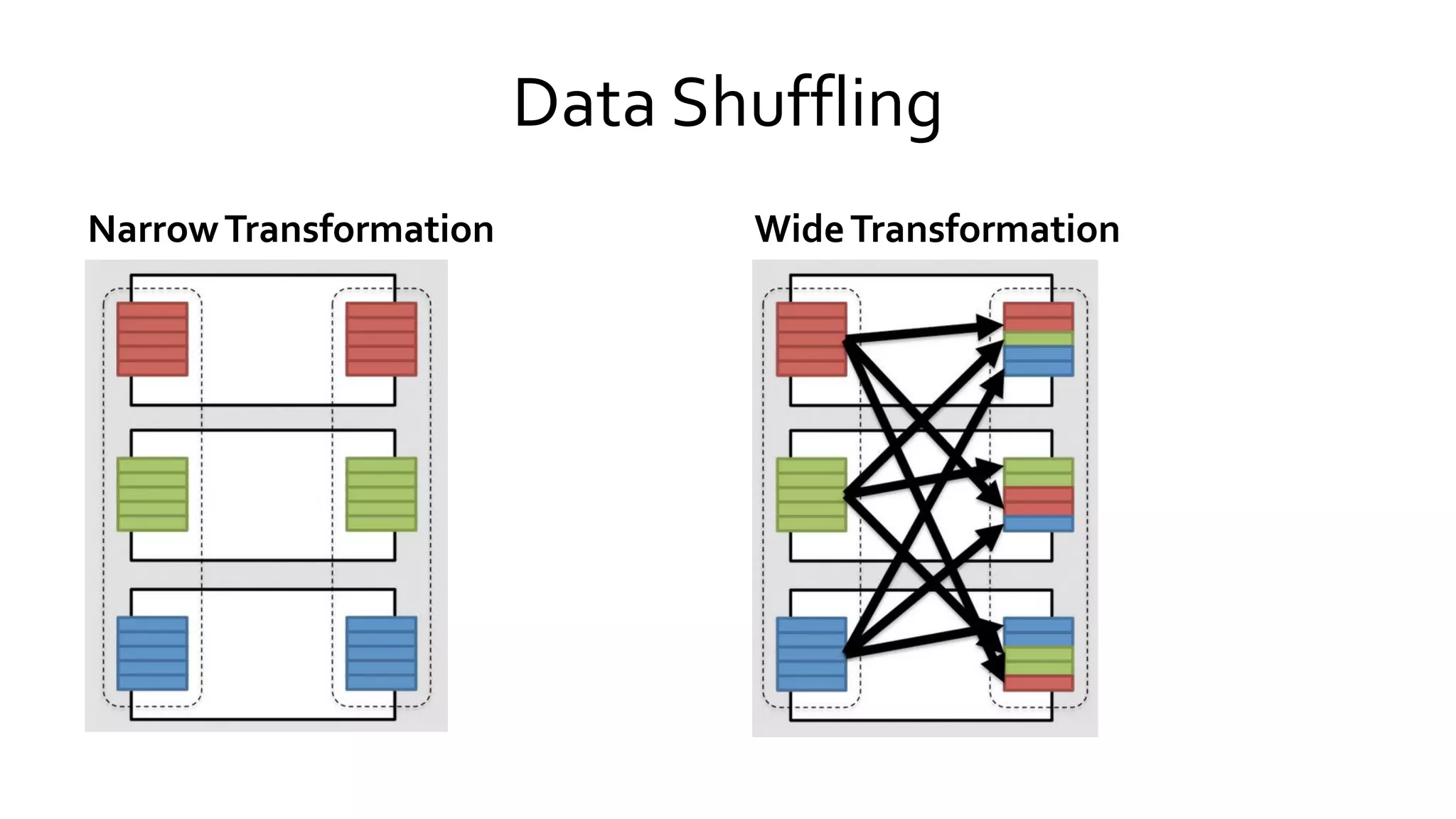
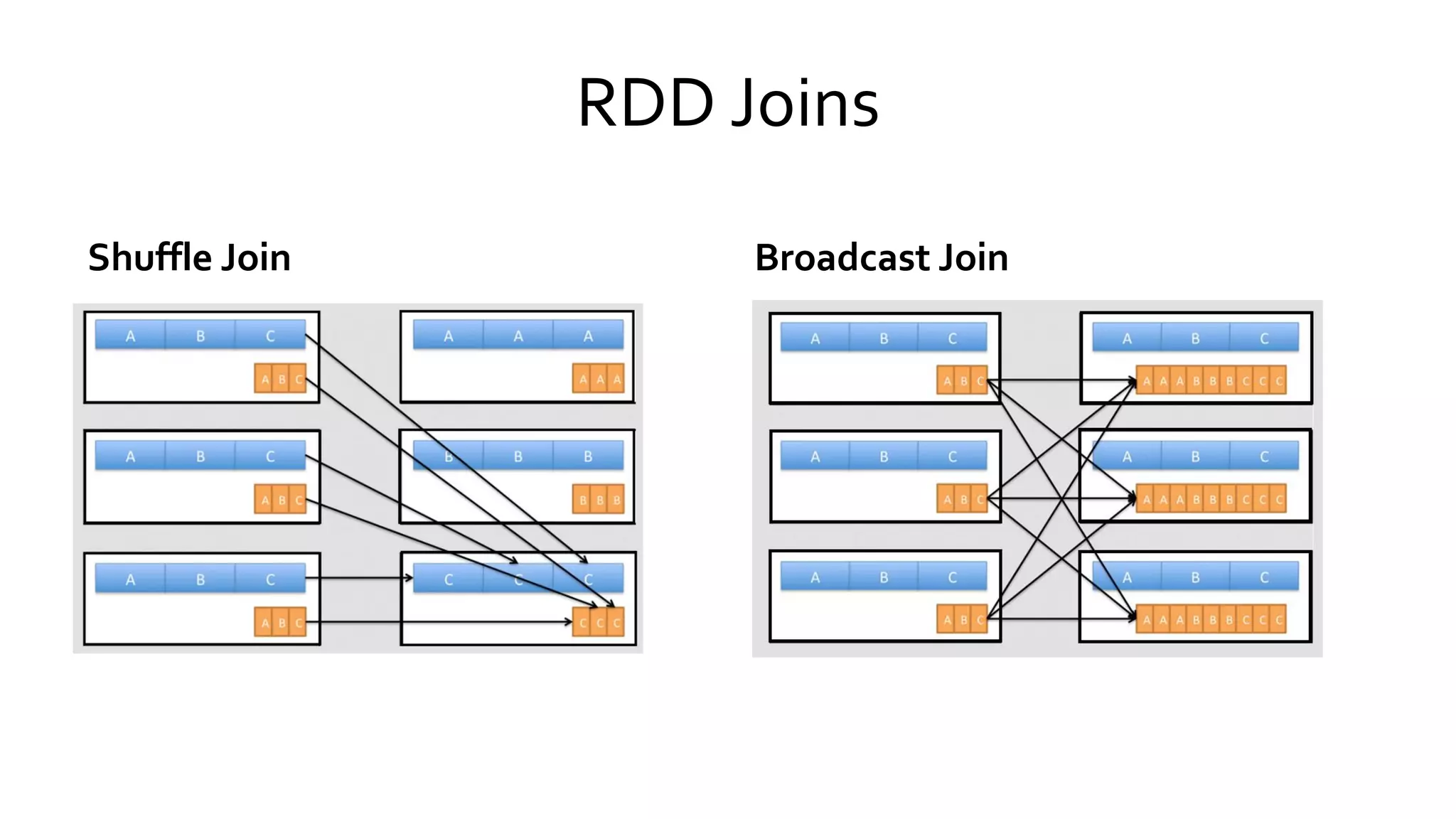
Discusses data shuffling mechanisms in Spark and methods for joining RDDs, highlighting shuffle versus broadcast joins.
Analyzes Spark's fault tolerance strategies that utilize RDD lineage for data recovery without costly replication.
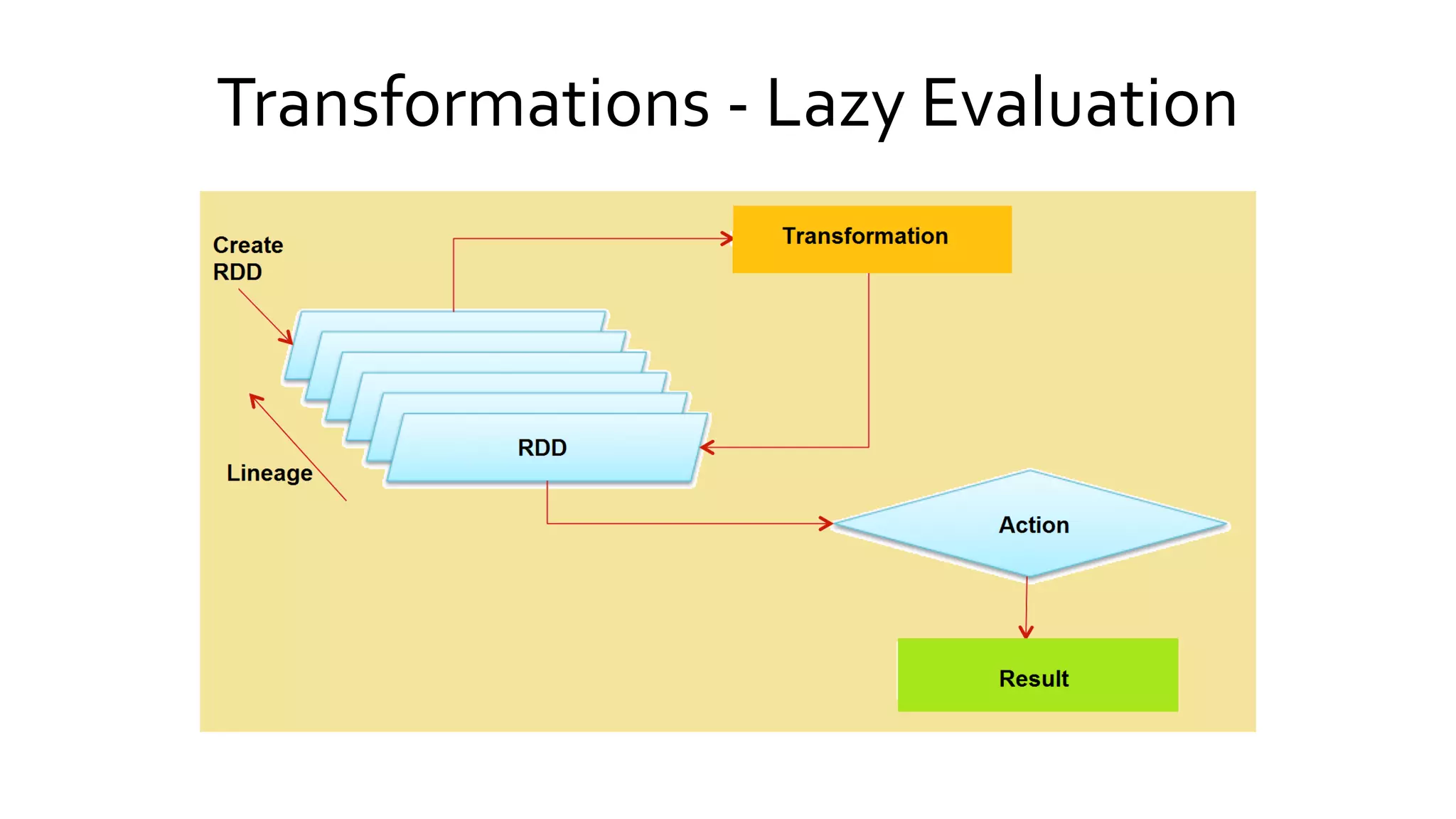
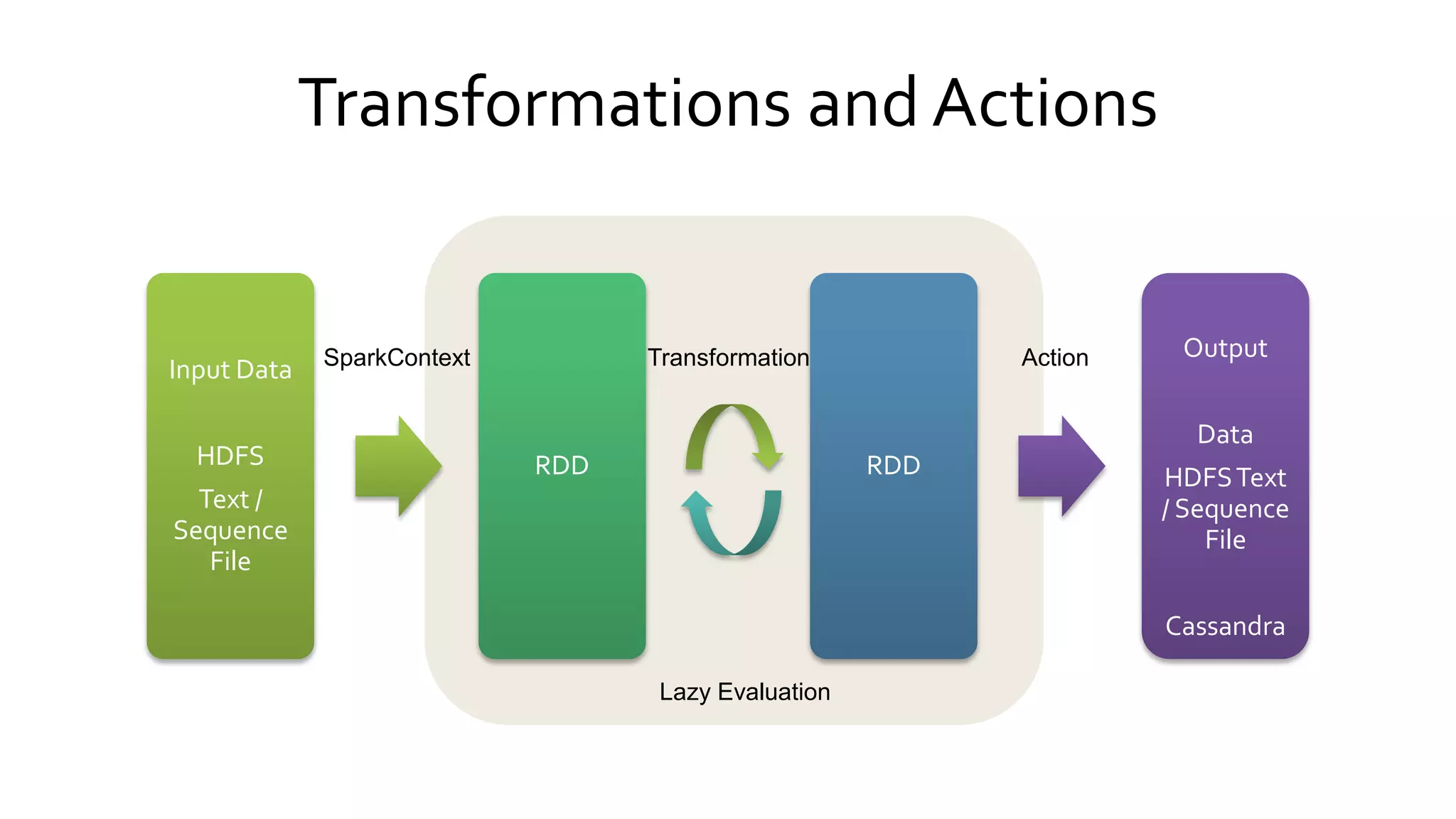
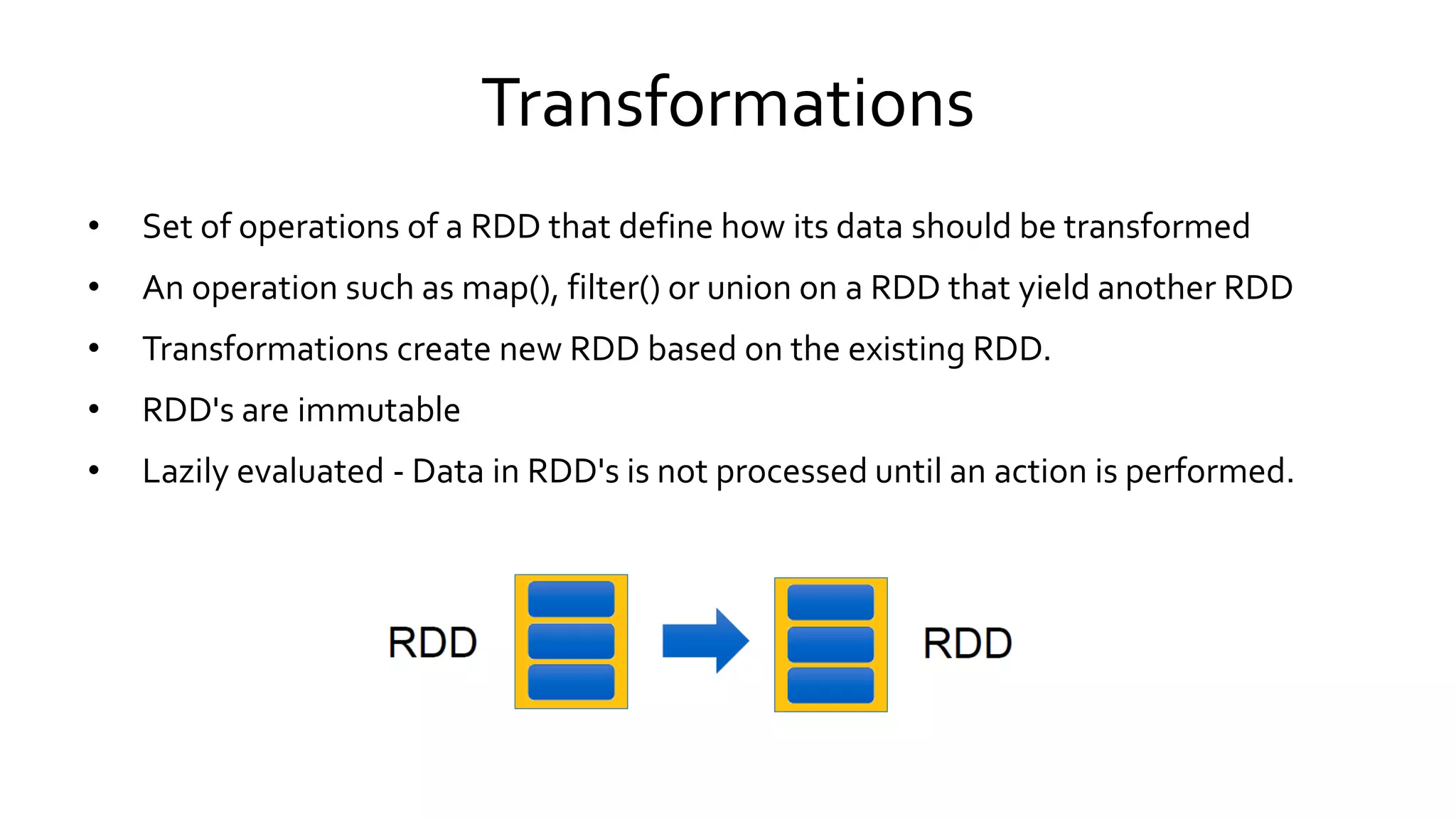
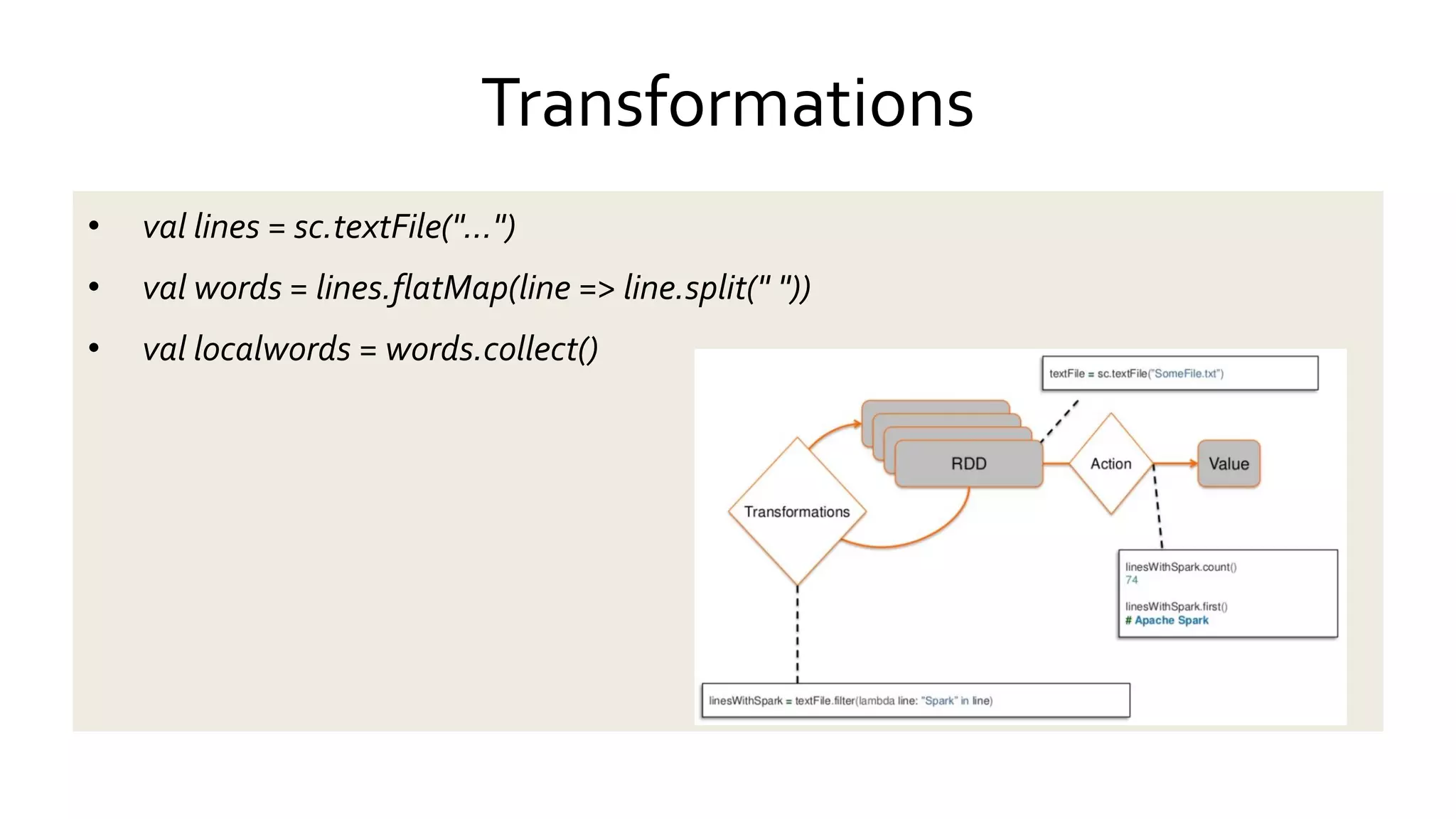
Details the distinctions between transformations and actions in Spark, emphasizing lazy evaluation and how RDDs are operated upon.
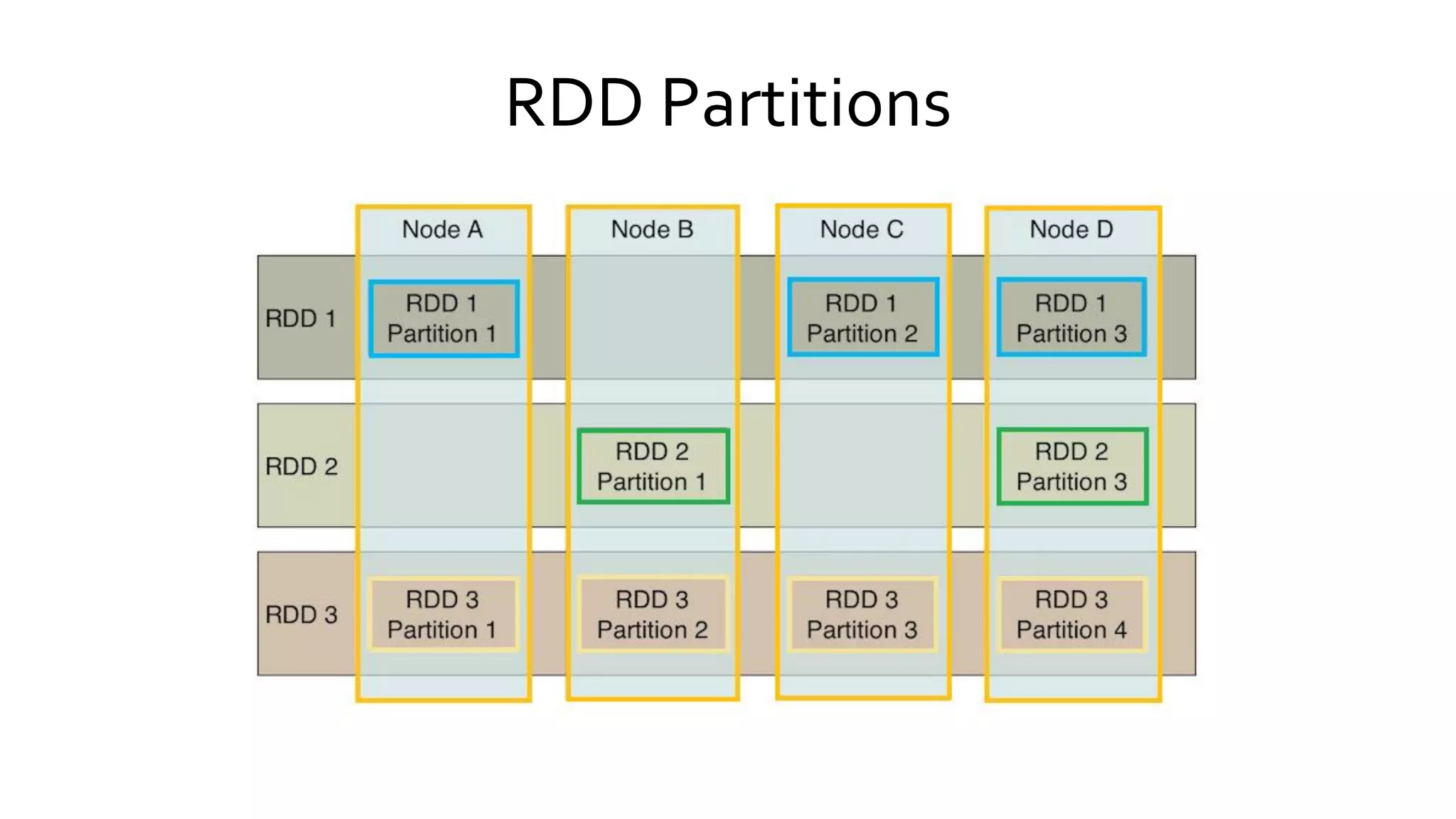
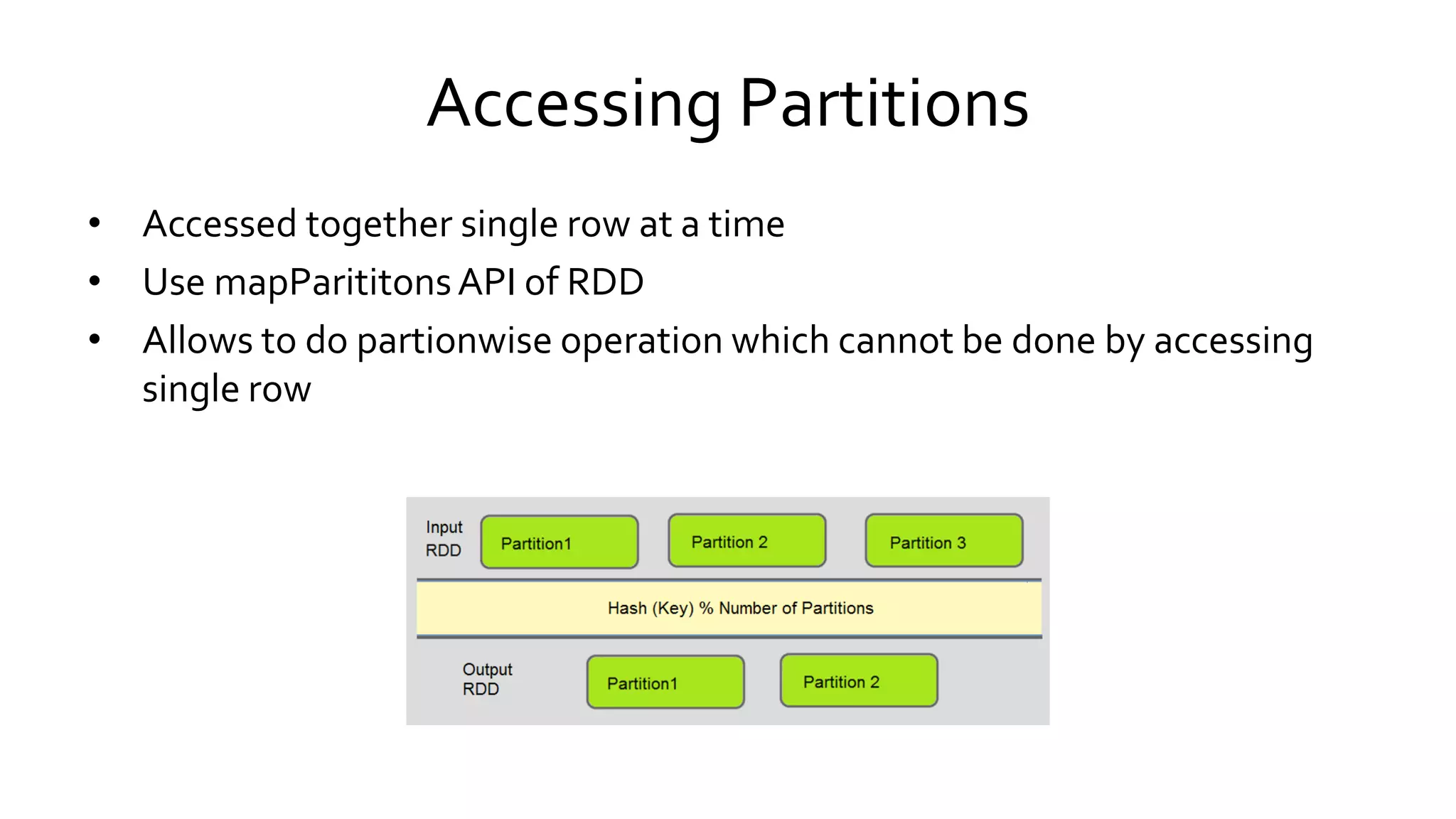
Describes the processes involved in creating RDDs, managing partitions, and the concepts of narrow and wide dependencies. Explains Spark's handling of shared variables, specifically broadcast variables and accumulators for efficient data processing. Discusses RDD partitions, caching strategies, and memory management to optimize performance in Spark applications.
Focuses on the ability to extend Spark's RDD API for custom operations and highlights the benefits of using RDDs in big data processing.
Provides links to resources and references for further reading on Apache Spark and its functionalities.
Concludes the presentation and invites further connection through LinkedIn.




































































































